可以看我的博客 lmwen.top
或者订阅我的公众号

简介
因为公司项目的原因,最近花了点时间去研究NLP
自然语言处理是一门比较复杂的技术,说深了,它涉及到机器学习和神经网络模型,说浅了,你会用他人实现好的工具就ok了。这么复杂的东西,当然首选python来实现啦!
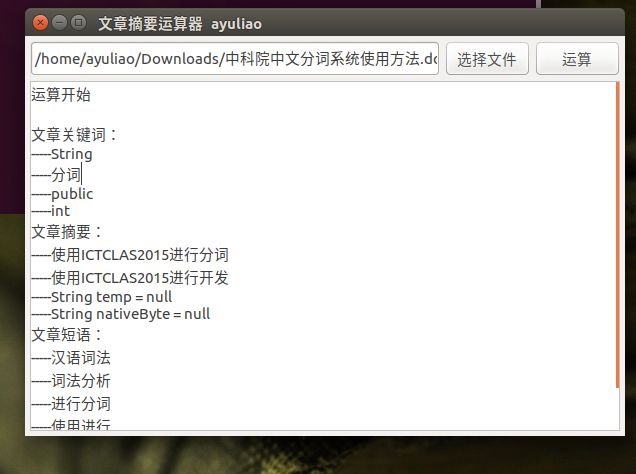
本章我们来实现一个简单的软件,可以对word文档、pdf文档进行关键词提取、自动摘要、中文分词和短语提取,效果如下
环境配置
我使用的环境:python2.7+ubuntu16.04+java1.8.0
python使用了的第三方库有:wxpython、Jpype、docx2txt、pdfminer
汉语处理库:HanLP
简单说说这些库wxpython:一个跨平台的python图形界面库,非常友好,使用它可以比较轻松的搭建一个界面还ok的图形界面,可以通过pip下载,也可以直接去 wxpython官网下载,它有很多中文教程,随便搜搜就有了
Jpype:让python可以调动Java程序,一般为jar包,Jpype不同Jython,Jython运行在JVM上,而Jpype依旧运行在python上,只是在运行期间嵌入了JVM,你依旧可以通过pip下载,ubuntu还可以通过apt-get下载,主要不同版本的python对应不同版本的Jpype,Python2.7对应Jpype1,Python3对应Jpype1-py3,这里使用这个库的原因是,我们使用的自然语言处理算法使用java实现的,所以要通过Jpype来调用相应jar包中的方法
docx2txt:从库的名字也可以轻易的看出,docx2txt用于将docx格式的文档,也就是word文档转成txt,该库使用起来非常简单
pdfminer:pdfminer主要用于处理pdf格式的文件,可以将pdf格式的文件转成txt
HanLP:一个中国开发者开发的汉语处理库,这个库很强大,而且完全开源,非常感谢这个开发者,非常感谢开源,只要使用库,最核心的中文处理功能都可以轻松实现,你要的只是通过Python将实现好的JAVA语言,其核心算法都通过JAVA实现,可以去相应的github上了解该项目, HanLP
自然语言处理
虽说我们已经找到了第三方自然语言处理库,但是为了更好的理解自然语言处理或跟好的利用这些工具,我觉得一些基本的理念还是要清楚的,下面我来总结一下这几天学习到的
中文分词工具
中华文化博大精深,精深到可以搞死我们,不同英文,每个单词之间都一个空格隔开,这种特性让英文分词相对好实现,但是中文不一样,中文之间是没有间隔的,而且不同的分词方式可以带来完全不一样的结果,如对春药店进行分词,会有两个完全不同的结果
12
春/ 药店/春药/ 店/
正是因为中文具有这些复杂的特性,什么成语啊,一词多义啊之类的,让中文分词变得非常难搞,需要研究出相应的算法,但是市面上已经有一些中文分词工具可以使用了,除了前面提到的HanLP,还有哈工的LTP、中科院计算所的NLPIR、清华大学的THULAC和Jieba,这些都是比较优秀的分词工具,因为我不是什么专业人士,所以对这些工具的效率啊,准确性啊无法评估,但是网上有人对这些工具做过评估,发现哈工的LTP和清华的THULAC不错,但是我使用HanLP,主要是因为HanLP文档友好,同时社区比较活跃,github上2000多个星,而且时常更新与维护
下面给出中文分词工具对应的github网址哈工大LTP
中科院计算所NLPIR
清华大学THULAC
jieba
背景知识
在自然语言处理领域有一些很常见的术语,下面解释一下这些术语
中文分词
机器是无法识别出一句中文所表达的意义的,所以第一步要进行分词,目的就是将一段话分割成一个个有意义的词,要实现这个目的就要有一个优雅的语言模型和语料库
语言模型
语言模型用大白话说就是一个算法,一个自然语言处理工具一般实现了多种语言模型,通过不同语言模型对内容极进行计算可以获得不同的结果,所以我们应该根据需求来选择不同的语言模型,可以阅读下面的文章加深理解语言模型的基本概念
语料库
语料库其实就是经过整理的语言文本,将真实语言中出现的一些词汇、语言材料整理起来,语料库的质量十分重要,是分词工具的根基,网上也有很多开源的语料库,语料基本格式如下
1234567891011
一一 一一列举 一一对应 一丁点 一丁点儿 一万年 一丈红 一下 一下子 一不做 一不小心 一专多能 一世 一丘之貉
词向量
首先我们要明白向量的作用。向量是人把自然界的东西抽象出来交给机器处理的东西,基本上可以说向量是人对机器输入的主要方式了。理解了上面那句话,那么词向量也就好解释了,所谓词向量就是用来将语言中的词进行数学化的一种方式。可以举个例子弄明白词向量的作用,对于一个词,可以将它抽象成为一个向量,如(0,1)(最简单的一个形式),该向量在二维空间就是一条线,那么另外一个词,同样可以抽象成一个向量,如(0,2),它同样在二维空间中是一条线,通过计算两条线的夹角cos值,就可以判断出两个词之间的相似性,这样就解决了一个实际的问题,如何判断两个句子或两篇文章的相似性,那么其中词向量的作用就是将语言抽象成数学化的一种表示。
具体实现
那么下面我们就来看看如何具体实现它
首先明确软件运行的成功流程,一开始,启动图形界面,然后用户选择文件,乳沟用户选择的是pdf或docx,那么点击运算程序就进行运算处理,其中的步骤就是将pdf或docx转成字符串,然后再进行分词,最后显示在图形界面上,如果不是pdf也不是docx,那么给出相应的错误提示
PDF TO TXT
首先来完成PDF转TXT,代码比较简单,学习一下如何使用pdfminer则可,基础用法可以上网查查,这里直接上代码了
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172
-- coding:utf-8 --from cStringIO import StringIOfrom pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreterfrom pdfminer.converter import TextConverterfrom pdfminer.layout import LAParamsfrom pdfminer.pdfpage import PDFPageimport osimport sys, getoptimport HanLP as ayuimport string# PDF转txtdef convert(fname, pages=None): if not pages: pagenums = set() else: pagenums = set(pages) output = StringIO() manager = PDFResourceManager() converter = TextConverter(manager, output, laparams=LAParams()) interpreter = PDFPageInterpreter(manager, converter) infile = file(fname, 'rb') for page in PDFPage.get_pages(infile, pagenums): interpreter.process_page(page) infile.close() converter.close() text = output.getvalue() output.close return text# 构造文件路径,进行分词处理def convertMultiple(pdfDir, txtDir): if pdfDir == "": pdfDir = os.getcwd() + "//" for pdf in os.listdir(pdfDir): # iterate through pdfs in pdf directory fileExtension = pdf.split(".")[-1] if fileExtension == "pdf": pdfFilename = pdfDir + pdf text = convert(pdfFilename) # get string of text content of pdf\ res = ayu.GetKeyWord(text,5) res2 = ayu.GetSummary(text,5) res3 = ayu.GetPhrase(text,5) p2tlist = list(); p2tlist.append(res) p2tlist.append(res2) p2tlist.append(res3) return p2tlist# i : info# p : pdfDir# t = txtDirdef main(argv,pdfDir = "",txtDir = ""): try: opts, args = getopt.getopt(argv, "ip:t:") except getopt.GetoptError: print("pdfToT.py -p -t ") sys.exit(2) for opt, arg in opts: if opt == "-i": print("pdfToT.py -p -t ") sys.exit() elif opt == "-p": pdfDir = arg elif opt == "-t": txtDir = arg return convertMultiple(pdfDir, txtDir)if name == "main": main("/home/ayuliao/HanLP/AyuZRYY/word2vec.pdf")
在该Python中,一开始调用main()方法,做一下预处理操作,使用了getopt,可以通过命令行参数来直接传入PDF文件的路径,然后就调用convertMultiple()方法,构建pdf文件的具体路径,将路径传入convert()方法,将pdf转成了相应的字符流,将这些字符流传递给分装好的中文分词方法,GetKeyWord()方法用于获取关键字,GetSummary()方法用于获得文章的简述,GetPhrase()方法获得文章的短语,将获得的内容都添加都list中,回传回去
DOCX TO TXT
接着将word文档也就是docx类型的文档转成字符串,DOCX转TXT其实比较麻烦,因为docx这个格式比较恶心,但是python太强大了,直接一个库docx2txt,轻松搞定
1234567891011121314151617
-- coding:utf-8 --import docx2txtimport osimport HanLP as ayu# 将docx转成字符串并进行分词def WToT(filePath): text = docx2txt.process(filePath) res = ayu.GetKeyWord(text, 4) res2 = ayu.GetSummary(text, 4) res3 = ayu.GetPhrase(text, 4) w2tlist = list(); w2tlist.append(res) w2tlist.append(res2) w2tlist.append(res3) return w2tlist
直接使用docx2txt库中的process()方法,将docx文件具体的路径传进去就ok了,有兴趣可以看看具体是怎么实现的(反正我没看;))
进行中文分词
如果你自己仔细看完了HanLP这个开源项目的文档,就会知道,使用这个库其实十分简单,唯一有点麻烦的是,它是java实现的,而我们编写的python代码,但HanLP社区非常活跃,所以这个坑已经有前辈帮我踩过了,可以看https://github.com/yesseecity/hanLP-python这个项目,已经完美实现python调用HanLP了,只是他使用的是python3的版本,所以还是需要自己摸索一下,如果你使用过Jpype这个牛逼的库,会发现实现python调用Java中的方法也不是特别麻烦,首先你要确定你的电脑中下载并配置了Java,比较HanLP里是Java代码,要跑到JVM下的,确定java环境没问题,就可以通过JPype来让python调用Java中实现的代码
可以通过下面的代码测试一下python是否可以连接上Java
1234
from jpype import *startJVM(getDefaultJVMPath())java.lang.System.out.println("Hello ayuliao")shutdownJVM()
如果出现
1234
Hello ayuliaoJVM activity report : classes loaded : 31JVM has been shutdown
说明你可以通过python调用JAVA了,我在windows上尝试了几次没有成功,怀疑过JAVA环境配置问题,但是环境似乎没问题,所以最终还是在Ubuntu上运行,果然在意开发效率,远离windows
在正式写这部分核心代码前,你需要下载HanLP的Java包,可以去这里下载HanLP Java包
下面就是正式的python代码了
123456789101112131415161718192021222324252627282930313233
-- coding:utf-8 --from jpype import *import osimport sysreload(sys)# 因为解码的时候会默认使用系统的编码,一般是ascii,如果是中文就会出现编码错误,直接将系统编码改成utf8则可sys.setdefaultencoding('utf8')path = os.getcwd();# print(path)startJVM(getDefaultJVMPath(), "-Djava.class.path="+path+"/hanlp-portable-1.3.4.jar:"+path+"/hanlp", "-Xms1g", "-Xmx1g") # 启动JVM,Windows需要将冒号:替换为分号;HanLP = JClass('com.hankcs.hanlp.HanLP')# 获得分词def GetFenWord(content): return HanLP.segment(content)# 获得文章关键字def GetKeyWord(content,number): return HanLP.extractKeyword(content,number)# 获得文章简述def GetSummary(content,number): return HanLP.extractSummary(content,number)# 获得文章短语def GetPhrase(content,number): return HanLP.extractPhrase(content, number)# 停止JVM运行def ShopJVM(): shutdownJVM()
python编写图像界面
python本身自带有图像界面库Tkinter,对应Tkinter,网上的资料比较多,但是我没有选它,因为感觉有点丑,所以选择了wxPython发现其实也没有漂亮到哪里去…..
学习了一下wxPython的用法,其实不难,就是一开始没有概念,写起来比较麻烦,但是wxPython封装的非常好,而且通过wxPython开发图形化界面还可以使用GUI可视化构建工具wxFormBuilder,有点像Android开发界面布局一样了,哈哈
使用wxFormBuilder是不错的选择,但是我不怎么喜欢,我下载下来看了看看它生成的代码,知道布局大概该怎么写后,就不怎么用了,因为通过代码来控制,感觉可以更精细点,可以看wxPython 基础使用教程这篇博文来学习使用wxPython和wxFormBuilder
下面直接看代码
12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576
!/usr/bin/python# coding:utf-8import wximport osimport Pdf2Txt as p2timport Word2Txt as w2tdef OnOpen(event): wilcard = "Python source (.pdf)|.pdf|Compiled Python (.pdf)|.pdf|All files (.)|." wilcard = "" dialog = wx.FileDialog(None, "选择一个文件", os.getcwd(), "", wilcard, wx.OPEN) if dialog.ShowModal() == wx.ID_OK: filename.SetValue(dialog.GetPath()) dialog.Destroy()def OnSave(event): if filename.GetValue() == '': contents.SetValue("必须选择一个文件才可进行运算!!!") else: filepath = filename.GetValue() fileExtension = filepath.split(".")[-1] if(fileExtension == "pdf"): res = p2t.main(filepath) if(fileExtension == "docx"): res = w2t.WToT(filepath) if(fileExtension != "pdf" or fileExtension != "docx"): contents.SetValue("只能运算pdf格式和docx格式的文件!!!") str = "运算开始\n\n" y=0 for r in res: i = 0 for k in r: if(i==0): if(y==0): str += "文章关键词:\n" if(y==1): str += "文章摘要:\n" if(y==2): str += "文章短语:\n" str += "-----"+k+"\n" i = i+1 y = y+1 str +="\n运算结束" contents.SetValue(str)app = wx.App()win = wx.Frame(None, title="文章摘要运算器 ayuliao", size=(600, 400))bkg = wx.Panel(win)loadButton = wx.Button(bkg, label='选择文件')loadButton.Bind(wx.EVT_BUTTON, OnOpen)saveButton = wx.Button(bkg, label='运算')saveButton.Bind(wx.EVT_BUTTON, OnSave)filename = wx.TextCtrl(bkg)contents = wx.TextCtrl(bkg, style=wx.TE_MULTILINE | wx.HSCROLL)hbox = wx.BoxSizer()hbox.Add(filename, proportion=1, flag=wx.EXPAND)hbox.Add(loadButton, proportion=0, flag=wx.LEFT, border=5)hbox.Add(saveButton, proportion=0, flag=wx.LEFT, border=5)vbox = wx.BoxSizer(wx.VERTICAL)vbox.Add(hbox, proportion=0, flag=wx.EXPAND | wx.ALL, border=5)vbox.Add(contents, proportion=1, flag=wx.EXPAND | wx.LEFT | wx.BOTTOM | wx.RIGHT, border=5)bkg.SetSizer(vbox)win.Show()app.MainLoop()
在代码中,我们构建了两个Button按钮,并给它设置了相应的点击函数,分别是从系统中选择文件(目的是得到文件的路径)和进行中文分词运算
结尾
代码我已经上传到github,我称这个项目为GAS(Get Article Summary),方便你直接下载下来使用,别忘了给我一个star,毕竟我也很不容易
GAS下载
有代码创造乐趣—ayuliao