- android系统selinux中添加新属性property
辉色投像
1.定位/android/system/sepolicy/private/property_contexts声明属性开头:persist.charge声明属性类型:u:object_r:system_prop:s0图12.定位到android/system/sepolicy/public/domain.te删除neverallow{domain-init}default_prop:property
- C#中使用split分割字符串
互联网打工人no1
c#
1、用字符串分隔:usingSystem.Text.RegularExpressions;stringstr="aaajsbbbjsccc";string[]sArray=Regex.Split(str,"js",RegexOptions.IgnoreCase);foreach(stringiinsArray)Response.Write(i.ToString()+"");输出结果:aaabbbc
- SpringBlade dict-biz/list 接口 SQL 注入漏洞
文章永久免费只为良心
oracle数据库
SpringBladedict-biz/list接口SQL注入漏洞POC:构造请求包查看返回包你的网址/api/blade-system/dict-biz/list?updatexml(1,concat(0x7e,md5(1),0x7e),1)=1漏洞概述在SpringBlade框架中,如果dict-biz/list接口的后台处理逻辑没有正确地对用户输入进行过滤或参数化查询(PreparedSta
- openssl+keepalived安装部署
_小亦_
项目部署keepalivedopenssl
文章目录OpenSSL安装下载地址编译安装修改系统配置版本Keepalived安装下载地址安装遇到问题安装完成配置文件keepalived运行检查运行状态查看系统日志修改服务service重新加载systemd检查配置文件语法错误OpenSSL安装下载地址考虑到后面设备可能没法连接到外网,所以采用安装包的方式进行部署,下载地址:https://www.openssl.org/source/old/
- CentOS的根目录下,/bin 和 /sbin 用途和权限
Energet!c
Linux日常centoslinux运维
CentOS的根目录下,/bin和/sbin用途和权限一、/bin(Binary)二、/sbin(SystemBinary)三、总结在CentOS的根目录下,/bin和/sbin目录有不同的用途和权限一、/bin(Binary)用途:存放系统的基本命令,这些命令对所有用户都是可用的。例如:ls、cp、mv、rm等。权限:普通用户和系统管理员都可以使用这些命令。二、/sbin(SystemBinar
- vue3中el-table中点击图片放大时,被表格覆盖
叫我小鹏呀
vue.jsjavascript前端
问题:vue3中el-table中点击图片放大时,被表格覆盖。解决方法:el-image添加preview-teleported
- [Unity]在场景中随机生成不同位置且不重叠的物体
Bartender_Jill
Graphics图形学笔记unity游戏引擎动画
1.前言最近任务需要用到Unity在场景中随机生成物体,且这些物体不能重叠,简单记录一下。参考资料:Howtoensurethatspawnedtargetsdonotoverlap?2.结果与代码结果如下所示:代码如下所示:usingSystem.Collections.Generic;usingUnityEngine;namespaceAssets.Scripts{publicclassNew
- ubuntu安装wordpress
lissettecarlr
1安装nginx网上安装方式很多,这就就直接用apt-get了apt-getinstallnginx不用启动啥,然后直接在浏览器里面输入IP:80就能看到nginx的主页了。如果修改了一些配置可以使用下列命令重启一下systemctlrestartnginx.service2安装mysql输入安装前也可以更新一下软件源,在安装过程中将会让你输入数据库的密码。sudoapt-getinstallmy
- 最简单将静态网页挂载到服务器上(不用nginx)
全能全知者
服务器nginx运维前端html笔记
最简单将静态网页挂载到服务器上(不用nginx)如果随便弄个静态网页挂在服务器都要用nignx就太麻烦了,所以直接使用Apache来搭建一些简单前端静态网页会相对方便很多检查Web服务器服务状态:sudosystemctlstatushttpd#ApacheWeb服务器如果发现没有安装web服务器:安装Apache:sudoyuminstallhttpd启动Apache:sudosystemctl
- 新能源汽车 BMS 学习笔记篇—BMS 基本定义及分类
WPG大大通
其他笔记汽车BMS经验分享新能源电池
一、BMS定义1、概念:BMS(BatteryManagementSystem)即电池管理系统,其管理对象是二次电池(充电电池或蓄电池),其主要目的是电池的利用率,防止电池出现过度充电和过度放电,可应用于电动汽车、电瓶车、机器人、无人机等图片来源:腾讯网https://new.qq.com《标准普尔警告,电动汽车电池生产面临供应链和地缘政治风险》2、四大功能①感知和测量:检测电池的电压、电流、温度
- 代码的执行效果
高天
packagecom20210409;publicclassdemo04{publicstaticvoidmain(String[]args){//////&&当前的条件不满足,则最后结果一定不满足,后面的条件不再执行////&不管条件是否满足所有条件均作判断//intx=1,y=1;//if(++y==2&&x++==2){//x=7;//}//System.out.println("x="+x
- Hadoop
傲雪凌霜,松柏长青
后端大数据hadoop大数据分布式
ApacheHadoop是一个开源的分布式计算框架,主要用于处理海量数据集。它具有高度的可扩展性、容错性和高效的分布式存储与计算能力。Hadoop核心由四个主要模块组成,分别是HDFS(分布式文件系统)、MapReduce(分布式计算框架)、YARN(资源管理)和HadoopCommon(公共工具和库)。1.HDFS(HadoopDistributedFileSystem)HDFS是Hadoop生
- k8s证书过期问题处理
olina_qin
kubernetes容器云原生
k8s证书过期问题处理opensslx509-in/etc/kubernetes/pki/apiserver.crt-noout-dateskubeadmcertsrenewallsystemctlrestartkubeleopensslx509-in/etc/kubernetes/pki/apiserver.crt-noout-text|grep"NotAfter"cp/etc/kubernet
- 如何重启Linux服务器?
老男孩IT教育
gitlinux运维
在Linux操作系统中,提供了多种方法用于重启服务器,那么Linux服务器如何重启?以下列举了常用的几种方法,希望对大家有所帮助,快来看看吧。重启Linux服务器有以下几种方法:1、使用命令行使用reboot命令reboot使用shutdown命令shutdown-rnow2、使用systemctl使用以下命令:systemctlreboot3、使用web界面大多数现代Linux发行版本都提供一个
- PAT Advanced 1015. Reversible Primes (C语言实现)
OliverLew
我的PAT系列文章更新重心已移至Github,欢迎来看PAT题解的小伙伴请到GithubPages浏览最新内容。此处文章目前已更新至与GithubPages同步。欢迎star我的repo。题目Areversibleprimeinanynumbersystemisaprimewhose"reverse"inthatnumbersystemisalsoaprime.Forexampleinthedec
- linux挂载文件夹
小码快撩
linux
1.使用NFS(NetworkFileSystem)NFS是一种分布式文件系统协议,允许一个系统将其文件系统的一部分共享给其他系统。检查是否安装NFSrpm-qa|grepnfs2.启动和启用NFS服务假设服务名称为nfs-server.service,你可以使用以下命令启动和启用它:sudosystemctlstartnfs-server.servicesudosystemctlenablenf
- Python实现mysql命令行
xu-jssy
pythonmysqladb
一、源码importosimportpymysqldefsql_shell():password=input("EnterPassword:")#访问密码ifpassword.strip()!="yyds":print("Bye")return#清空控制台输出os.system("cls"ifos.name=="nt"else"clear")try:#连接到MySQL数据库conn=pymysql
- 复盘
赵建庄
行动后反思,AAR(AfterActionReview),是知识管理的一种工具,起源于美国陆军的作战方法,强调在每次行动后进行及时反思、总结和改进。《复盘》一书其实就是这种方法的具体应用,名字不同,然而实质相同。相比AAR这样的说法,复盘更简洁,容易被国人接受,而且,书中给出了非常详细的步骤,有较强的指导意义和实战性,AAR的六步法,说的比较简单,有人可以悟,结合实际业务演变出各种变化,大多数人可
- Tomcat 中 catalina.out、catalina.log、localhost.log 和 access_log 的区别
金色888
打开Tomcat安装目录中的log文件夹,我们可以看到很多日志文件,这篇文章就来介绍下这些日记文件的具体区别。catalina.out日志#catalina.out日志文件是Tomcat的标准输出(stdout)和标准出错(stderr)输出的“目的地”。我们在应用里使用System.out打印的内容都会输出到这个日志文件中。另外,如果我们在应用里使用其他的日志框架,配置了向Console输出日志
- 华为坤灵路由器配置SSH
redmond88
网络技术华为ssh运维
配置SSH服务器的管理网口IP地址。system-view[HUAWEI]sysnameSSHServer[SSHServer]interfacemeth0/0/0[SSHServer-MEth0/0/0]ipaddress10.248.103.194255.255.255.0[SSHServer-MEth0/0/0]quit在SSH服务器端生成本地密钥对。[SSHServer]rsalocal-
- 华为坤灵路由器初始化开局的注意事项,含NAT配置
redmond88
网络技术华为服务器运维
坤灵路由器比较坑,无web界面,全程命令行配置,但是版本更新导致和华为企业路由器配置很多不一样的地方,今天介绍下1、aaa密码复杂度修改:#使能设备对密码进行四选三复杂度检查功能。system-view[HUAWEI]aaa[HUAWEI-aaa]local-aaa-userpasswordpolicyadministrator[HUAWEI-aaa-lupp-admin]passwordcomp
- day12 控制流程 if switch while do...while 猜数字游戏
卓越小Y
JAVA学习日志游戏java开发语言
控制流程顺序结构所有的程序都是按顺序执行if语句选择结构单选择语句if(a>0){System.out.println(“hello”);}packagecom.ckw.blog.select;importjava.util.Scanner;publicclassdemo01{publicstaticvoidmain(String[]args){intscore=0;Scannerscanner=
- C#文件被占用的解决方案
花北城
C#项目文件占用
问题打更新包时,提示文件被占用。System.IO.IOException:文件“D:\RS\RS_CCVI20111210.exe”正由另一进程使用,因此该进程无法访问该文件。在System.IO.__Error.WinIOError(Int32errorCode,StringmaybeFullPath)在System.IO.FileStream.Init(Stringpath,FileMode
- FPGA器件在线配置方法概述
fpga和matlab
FPGA其他fpga开发FPGA在线配置
目录1.配置电路结构和原理2.ICR控制电路软件3.几种常见的FPGA在线配置方法3.1动态部分重配置(PartialReconfiguration,PR)3.2在系统编程(In-SystemProgramming,ISP)3.3多比特流配置(Multi-BitstreamConfiguration)3.4远程更新与配置3.5使用OpenCL或HLS工具FPGA(Field-Programmabl
- C# 自动化
TineAine
C#代码片段自动化c#自动化模拟操作
实现的方法可能很笨,但是确实很好用usingSystem;usingSystem.Collections.Generic;usingSystem.Linq;usingSystem.Runtime.InteropServices;usingSystem.Text;usingSystem.Threading;usingSystem.Threading.Tasks;/******************
- 数组拷贝Arraycopy
xing2516
Arraycopyjava
packageqing;//数组拷贝publicclassArraycopy{publicstaticvoidmain(String[]args){//一维数组拷贝Stringa[]={"小米","华为","阿里","腾讯","百度"};String[]aBak=newString[6];//从a数组第0个copy到数组aBak0个开始,长度是a数组长度System.arraycopy(a,0,a
- Java – 数组Copy的几种方式
hooc
javaweb
目前在Java中数据拷贝提供了如下方式:cloneSystem.arraycopyArrays.copyOfArrays.copyOfRange1、clone方法clone方法是从Object类继承过来的,基本数据类型(String,boolean,char,byte,short,float,double,long)都可以直接使用clone方法进行克隆,注意String类型是因为其值不可变所以才可
- java数组拷贝的方法
千锋IT教育
javajava数组
小千在给大家讲解数组扩容时,涉及到了数组中数据元素的拷贝复制。那么除了上面的拷贝方式之外,数组还有哪些拷贝方式呢?1.拷贝方式在Java中,数组的拷贝主要有三种实现方式:1.通过循环语句,将原数组中的各个元素拷贝到新数组中(即数组扩容案例中使用的方法);2.System类提供的数组拷贝方法;3.Arrays类提供的数组拷贝方法。接下来小千就设计几个案例,来给大家展示这几种方式都是怎么进行数组拷贝的
- Java中四种常用的数组复制的方法copyOf(),arraycop(),clone()和copyOfRange()的使用与区别
方九九
java知识点总结java
所谓复制数组,是指将一个数组中的元素在另一个数组中进行复制。本文主要介绍关于Java里面的数组复制(拷贝)的几种方式和用法。在Java中实现数组复制分别有以下4种方法:1.Arrays类的copyOf()方法2.Arrays类的copyOfRange()方法3.System类的arraycopy()方法4.Object类的clone()方法下面来详细介绍这4种方法的使用。使用copyOf()方法和
- springboot与日志
最后的夏t
日志1、日志框架小张;开发一个大型系统;1、System.out.println("");将关键数据打印在控制台;去掉?写在一个文件?2、框架来记录系统的一些运行时信息;日志框架;zhanglogging.jar;3、高大上的几个功能?异步模式?自动归档?xxxx?zhanglogging-good.jar?4、将以前框架卸下来?换上新的框架,重新修改之前相关的API;zhanglogging-p
- java工厂模式
3213213333332132
java抽象工厂
工厂模式有
1、工厂方法
2、抽象工厂方法。
下面我的实现是抽象工厂方法,
给所有具体的产品类定一个通用的接口。
package 工厂模式;
/**
* 航天飞行接口
*
* @Description
* @author FuJianyong
* 2015-7-14下午02:42:05
*/
public interface SpaceF
- nginx频率限制+python测试
ronin47
nginx 频率 python
部分内容参考:http://www.abc3210.com/2013/web_04/82.shtml
首先说一下遇到这个问题是因为网站被攻击,阿里云报警,想到要限制一下访问频率,而不是限制ip(限制ip的方案稍后给出)。nginx连接资源被吃空返回状态码是502,添加本方案限制后返回599,与正常状态码区别开。步骤如下:
- java线程和线程池的使用
dyy_gusi
ThreadPoolthreadRunnabletimer
java线程和线程池
一、创建多线程的方式
java多线程很常见,如何使用多线程,如何创建线程,java中有两种方式,第一种是让自己的类实现Runnable接口,第二种是让自己的类继承Thread类。其实Thread类自己也是实现了Runnable接口。具体使用实例如下:
1、通过实现Runnable接口方式 1 2
- Linux
171815164
linux
ubuntu kernel
http://kernel.ubuntu.com/~kernel-ppa/mainline/v4.1.2-unstable/
安卓sdk代理
mirrors.neusoft.edu.cn 80
输入法和jdk
sudo apt-get install fcitx
su
- Tomcat JDBC Connection Pool
g21121
Connection
Tomcat7 抛弃了以往的DBCP 采用了新的Tomcat Jdbc Pool 作为数据库连接组件,事实上DBCP已经被Hibernate 所抛弃,因为他存在很多问题,诸如:更新缓慢,bug较多,编译问题,代码复杂等等。
Tomcat Jdbc P
- 敲代码的一点想法
永夜-极光
java随笔感想
入门学习java编程已经半年了,一路敲代码下来,现在也才1w+行代码量,也就菜鸟水准吧,但是在整个学习过程中,我一直在想,为什么很多培训老师,网上的文章都是要我们背一些代码?比如学习Arraylist的时候,教师就让我们先参考源代码写一遍,然
- jvm指令集
程序员是怎么炼成的
jvm 指令集
转自:http://blog.csdn.net/hudashi/article/details/7062675#comments
将值推送至栈顶时 const ldc push load指令
const系列
该系列命令主要负责把简单的数值类型送到栈顶。(从常量池或者局部变量push到栈顶时均使用)
0x02 &nbs
- Oracle字符集的查看查询和Oracle字符集的设置修改
aijuans
oracle
本文主要讨论以下几个部分:如何查看查询oracle字符集、 修改设置字符集以及常见的oracle utf8字符集和oracle exp 字符集问题。
一、什么是Oracle字符集
Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。ORACLE 支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。它使数据库工具,错误消息,排序次序,日期,时间,货
- png在Ie6下透明度处理方法
antonyup_2006
css浏览器FirebugIE
由于之前到深圳现场支撑上线,当时为了解决个控件下载,我机器上的IE8老报个错,不得以把ie8卸载掉,换个Ie6,问题解决了,今天出差回来,用ie6登入另一个正在开发的系统,遇到了Png图片的问题,当然升级到ie8(ie8自带的开发人员工具调试前端页面JS之类的还是比较方便的,和FireBug一样,呵呵),这个问题就解决了,但稍微做了下这个问题的处理。
我们知道PNG是图像文件存储格式,查询资
- 表查询常用命令高级查询方法(二)
百合不是茶
oracle分页查询分组查询联合查询
----------------------------------------------------分组查询 group by having --平均工资和最高工资 select avg(sal)平均工资,max(sal) from emp ; --每个部门的平均工资和最高工资
- uploadify3.1版本参数使用详解
bijian1013
JavaScriptuploadify3.1
使用:
绑定的界面元素<input id='gallery'type='file'/>$("#gallery").uploadify({设置参数,参数如下});
设置的属性:
id: jQuery(this).attr('id'),//绑定的input的ID
langFile: 'http://ww
- 精通Oracle10编程SQL(17)使用ORACLE系统包
bijian1013
oracle数据库plsql
/*
*使用ORACLE系统包
*/
--1.DBMS_OUTPUT
--ENABLE:用于激活过程PUT,PUT_LINE,NEW_LINE,GET_LINE和GET_LINES的调用
--语法:DBMS_OUTPUT.enable(buffer_size in integer default 20000);
--DISABLE:用于禁止对过程PUT,PUT_LINE,NEW
- 【JVM一】JVM垃圾回收日志
bit1129
垃圾回收
将JVM垃圾回收的日志记录下来,对于分析垃圾回收的运行状态,进而调整内存分配(年轻代,老年代,永久代的内存分配)等是很有意义的。JVM与垃圾回收日志相关的参数包括:
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-Xloggc
-XX:+PrintGC
通
- Toast使用
白糖_
toast
Android中的Toast是一种简易的消息提示框,toast提示框不能被用户点击,toast会根据用户设置的显示时间后自动消失。
创建Toast
两个方法创建Toast
makeText(Context context, int resId, int duration)
参数:context是toast显示在
- angular.identity
boyitech
AngularJSAngularJS API
angular.identiy 描述: 返回它第一参数的函数. 此函数多用于函数是编程. 使用方法: angular.identity(value); 参数详解: Param Type Details value
*
to be returned. 返回值: 传入的value 实例代码:
<!DOCTYPE HTML>
- java-两整数相除,求循环节
bylijinnan
java
import java.util.ArrayList;
import java.util.List;
public class CircleDigitsInDivision {
/**
* 题目:求循环节,若整除则返回NULL,否则返回char*指向循环节。先写思路。函数原型:char*get_circle_digits(unsigned k,unsigned j)
- Java 日期 周 年
Chen.H
javaC++cC#
/**
* java日期操作(月末、周末等的日期操作)
*
* @author
*
*/
public class DateUtil {
/** */
/**
* 取得某天相加(减)後的那一天
*
* @param date
* @param num
*
- [高考与专业]欢迎广大高中毕业生加入自动控制与计算机应用专业
comsci
计算机
不知道现在的高校还设置这个宽口径专业没有,自动控制与计算机应用专业,我就是这个专业毕业的,这个专业的课程非常多,既要学习自动控制方面的课程,也要学习计算机专业的课程,对数学也要求比较高.....如果有这个专业,欢迎大家报考...毕业出来之后,就业的途径非常广.....
以后
- 分层查询(Hierarchical Queries)
daizj
oracle递归查询层次查询
Hierarchical Queries
If a table contains hierarchical data, then you can select rows in a hierarchical order using the hierarchical query clause:
hierarchical_query_clause::=
start with condi
- 数据迁移
daysinsun
数据迁移
最近公司在重构一个医疗系统,原来的系统是两个.Net系统,现需要重构到java中。数据库分别为SQL Server和Mysql,现需要将数据库统一为Hana数据库,发现了几个问题,但最后通过努力都解决了。
1、原本通过Hana的数据迁移工具把数据是可以迁移过去的,在MySQl里面的字段为TEXT类型的到Hana里面就存储不了了,最后不得不更改为clob。
2、在数据插入的时候有些字段特别长
- C语言学习二进制的表示示例
dcj3sjt126com
cbasic
进制的表示示例
# include <stdio.h>
int main(void)
{
int i = 0x32C;
printf("i = %d\n", i);
/*
printf的用法
%d表示以十进制输出
%x或%X表示以十六进制的输出
%o表示以八进制输出
*/
return 0;
}
- NsTimer 和 UITableViewCell 之间的控制
dcj3sjt126com
ios
情况是这样的:
一个UITableView, 每个Cell的内容是我自定义的 viewA viewA上面有很多的动画, 我需要添加NSTimer来做动画, 由于TableView的复用机制, 我添加的动画会不断开启, 没有停止, 动画会执行越来越多.
解决办法:
在配置cell的时候开始动画, 然后在cell结束显示的时候停止动画
查找cell结束显示的代理
- MySql中case when then 的使用
fanxiaolong
casewhenthenend
select "主键", "项目编号", "项目名称","项目创建时间", "项目状态","部门名称","创建人"
union
(select
pp.id as "主键",
pp.project_number as &
- Ehcache(01)——简介、基本操作
234390216
cacheehcache简介CacheManagercrud
Ehcache简介
目录
1 CacheManager
1.1 构造方法构建
1.2 静态方法构建
2 Cache
2.1&
- 最容易懂的javascript闭包学习入门
jackyrong
JavaScript
http://www.ruanyifeng.com/blog/2009/08/learning_javascript_closures.html
闭包(closure)是Javascript语言的一个难点,也是它的特色,很多高级应用都要依靠闭包实现。
下面就是我的学习笔记,对于Javascript初学者应该是很有用的。
一、变量的作用域
要理解闭包,首先必须理解Javascript特殊
- 提升网站转化率的四步优化方案
php教程分享
数据结构PHP数据挖掘Google活动
网站开发完成后,我们在进行网站优化最关键的问题就是如何提高整体的转化率,这也是营销策略里最最重要的方面之一,并且也是网站综合运营实例的结果。文中分享了四大优化策略:调查、研究、优化、评估,这四大策略可以很好地帮助用户设计出高效的优化方案。
PHP开发的网站优化一个网站最关键和棘手的是,如何提高整体的转化率,这是任何营销策略里最重要的方面之一,而提升网站转化率是网站综合运营实力的结果。今天,我就分
- web开发里什么是HTML5的WebSocket?
naruto1990
Webhtml5浏览器socket
当前火起来的HTML5语言里面,很多学者们都还没有完全了解这语言的效果情况,我最喜欢的Web开发技术就是正迅速变得流行的 WebSocket API。WebSocket 提供了一个受欢迎的技术,以替代我们过去几年一直在用的Ajax技术。这个新的API提供了一个方法,从客户端使用简单的语法有效地推动消息到服务器。让我们看一看6个HTML5教程介绍里 的 WebSocket API:它可用于客户端、服
- Socket初步编程——简单实现群聊
Everyday都不同
socket网络编程初步认识
初次接触到socket网络编程,也参考了网络上众前辈的文章。尝试自己也写了一下,记录下过程吧:
服务端:(接收客户端消息并把它们打印出来)
public class SocketServer {
private List<Socket> socketList = new ArrayList<Socket>();
public s
- 面试:Hashtable与HashMap的区别(结合线程)
toknowme
昨天去了某钱公司面试,面试过程中被问道
Hashtable与HashMap的区别?当时就是回答了一点,Hashtable是线程安全的,HashMap是线程不安全的,说白了,就是Hashtable是的同步的,HashMap不是同步的,需要额外的处理一下。
今天就动手写了一个例子,直接看代码吧
package com.learn.lesson001;
import java
- MVC设计模式的总结
xp9802
设计模式mvc框架IOC
随着Web应用的商业逻辑包含逐渐复杂的公式分析计算、决策支持等,使客户机越
来越不堪重负,因此将系统的商业分离出来。单独形成一部分,这样三层结构产生了。
其中‘层’是逻辑上的划分。
三层体系结构是将整个系统划分为如图2.1所示的结构[3]
(1)表现层(Presentation layer):包含表示代码、用户交互GUI、数据验证。
该层用于向客户端用户提供GUI交互,它允许用户
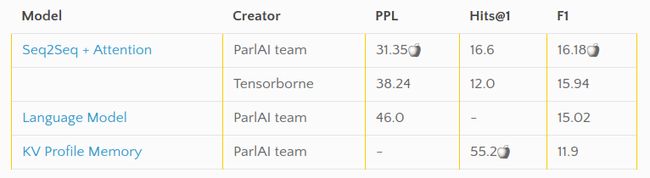 ConvAI2 baseline
ConvAI2 baseline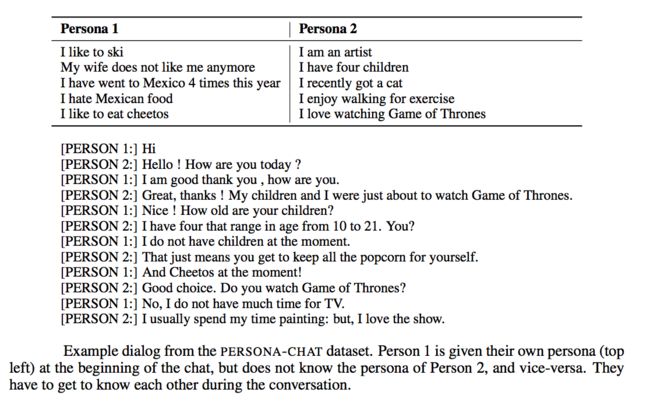 ConvAI2_dataset
ConvAI2_dataset