1. 引言
许多数据分析应用都会涉及到从短文本中提取出潜在的主题,比如微博、短信、日志文件或者评论数据。一方面,提取出潜在的主题有助于下一步的分析,比如情感评分或者文本分类模型。另一方面,短文本数据存在一定的特殊性,我们无法直接用传统的主题模型算法来处理它。短文本数据的主要难点在于:
- 短文本数据中经常存在多词一义的现象[1],比如 “dollar”, "$", "$$", "fee", "charges" 拥有相同的含义,但是受限于文本篇幅的原因,我们很难直接从短文本数据中提取出这些信息。
- 与长文档不同的地方在于,短文本数据中通常只包含一个主题。这看似很好处理,但是传统的主题模型算法都假设一篇文档中包含多个主题,这给建模分析带来了不小的麻烦。
主题提取模型通常包含多个流程,比如文本预处理、文本向量化、主题挖掘和主题表示过程。每个流程中都有多种处理方法,不同的组合方法将会产生不同的建模结果。
本文将主要从实际操作的角度来介绍不同的短文本主题建模算法的优缺点,更多理论上的探讨可以参考以下文章。
下文中我将自己创建一个数据集,并利用 Python scikit-learn 来拟合相应的主题模型。
2. 主题发现模型
本文主要介绍三个主题模型, LDA(Latent Dirichlet Allocation), NMF(Non-Negative Matrix Factorization)和SVD(Singular Value Decomposition)。本文主要采用 scikit-learn 来实现这三个模型。
除了这三个模型外,还有其他一些模型也可以用来发现文档的结构。其中最重要的一个模型就是 KMeans 聚类模型,本文将对比 KMeans 聚类模型和其他主题模型的拟合效果。
首先,我们需要构建文本数据集。本文将以四个自己构建的文本数据集为例来构建主题模型:
- clearcut topics: 该数据集中只包含两个主题—— "berger-lovers" 和 "sandwich-haters"。
- unbalanced topics: 该数据集与第一个数据集包含的主题信息一致,但是此数据集的分布是有偏的。
- semantic topics: 该数据集包含四个主题,分别是 "berger-lovers", "berger-haters","sandwich-lovers" 和 "sandwich-haters"。此外,该数据集中还包含了两个潜在的主题 “food” 和 “feelings”。
- noisy topics: 正如前文所说的,短文本数据中经常存在多词一义的现象,该数据集主要用于模拟两个主题不同类型的文本。该数据集文本的篇幅小于其他三个数据集,这可以用来检验模型是否能够很好地处理短文本数据。

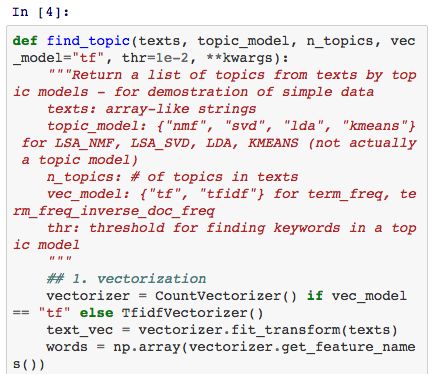
首先,我们需要考虑下如何评估一个主题模型建模效果的好坏程度。多数情况下,每个主题中的关键词有以下两个特征:
- 关键词出现的频率得足够大
- 足以区分不同的主题
一些研究表明:关键词还需具备以下两个特征:
- 相同主题的文档中关键词共同出现的频率应该差不多
- 每个主题中关键词的语义应该十分接近,比如水果主题中的 “apples” 和 “oranges”,或者情感主题中的 “love” 和 “hate”。
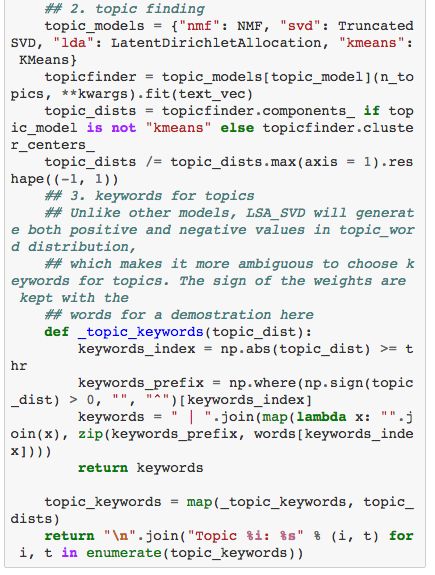
接下来,我们将介绍如何实现上述的四个模型——NMF, SVD, LDA 和 KMEANS。对于每个主题模型,我们将分别采用两种文本向量化的方法—— TF(Term Frequence) 和 TFIDF(Term-frequence-inverse-document-frequence)。通常情况下,如果你的数据集中有许多词语在多篇文档中都频繁出现,那么你应该选择采用 TFIDF 的向量化方法。此时这些频繁出现的词语将被视为噪声数据,这些数据会影响模型的拟合效果。然而对于短文本数据而言,TF和TFIDF方法并没有显著的区别,因为短文本数据集中很难碰到上述情况。如何将文本数据向量化是个非常热门的研究领域,比如 基于word embedding模型的方法——word2vec和doc2vec。
主题模型将选择主题词语分布中频率最高的词语作为该主题的关键词,但是对于 SVD 和 KMEANS 算法来说,模型得到的主题词语矩阵中既包含正向值也包含负向值,我们很难直接从中准确地提取出主题关键词。为了解决这个问题,我选择从中挑出绝对数值最大的几个词语作为关键词,并且根据正负值的情况加上相应的标签,即对负向词语加上 "^" 的前缀,比如"^bergers"。
2.1 SVD: 正交分解
sklearn 中的 truncated SVD implementation 类似于主成分分析算法,它们都试图利用正交分解的方法选择出具有最大方差的变量信息。
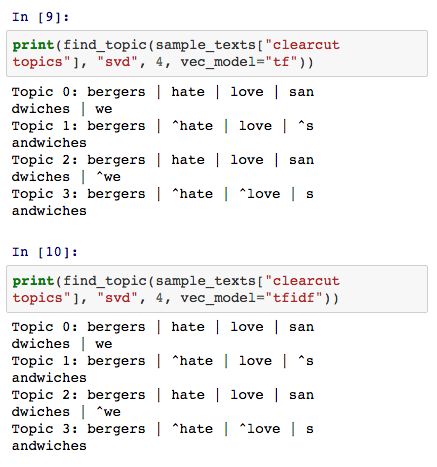
对于 clearcut-topic 数据集来说,我们分别利用 TF 和 TFIDF方法来向量化文本数据,并构建 SVD 模型,模型的拟合结果如下所示。正如我们之前所提到的,SVD 模型所提取的关键词中包含正负向词语。为了简单起见, 我们可以理解为该主题包含正向词语,不包含负向的词语。
比如,对于 "Topic 1: bergers | ^hate | love | ^sandwiches" 来说,该文本的主题中包含 "love bergers" 但是不包含 "hate sandwiches"。
由于模型的随机效应,所以每次运行模型得到的结果都会存在细微的差异。在 SVD 的拟合结果中我们发现发现 Topic 3: bergers | ^hate | ^love | sandwiches 成功地提取了 “food” 的主题。
在上述的例子中,我们设定了过多的主题数量,这是因为大多数时候我们无法事先知道某个文档包含多少个主题。如果我们令主题个数等于2,可以得到下述结果:

当我们在解释 SVD 模拟的拟合结果时,我们需要对比多个主题的信息。比如上述的模型拟合结果可以解释成:数据集中文档的主要差异是文档中包含 “love bergers” 但不包含 “hate sandwiches”。
接下来我们将利用 SVD 来拟合 unbalanced topic 数据集,检验该模型处理非平衡数据集的效果。

从下述结果中可以看出,SVD无法处理噪声数据,即无法从中提取出主题信息。

2.2 LDA: 根据词语的共现频率来提取主题
LDA 是最常用的主题提取模型之一,因为该模型能够处理多种类型的文本数据,而且模拟的拟合效果非常易于解释。
直观上来看,LDA 根据不同文档中词语的共现频率来提取文本中潜在的主题信息。另一方面,具有相同主题结构的文本之间往往非常相似,因此我们可以根据潜在的主题空间来推断词语之间的相似性和文档之间的相似性。
LDA 算法中主要有两类参数:
- 每个主题中各个关键词的分布参数
- 每篇文档中各个主题的分布参数
接下来我们将研究这些参数是如何影响 LDA 模型的计算过程,人们更多的是根据经验来选择最佳参数。
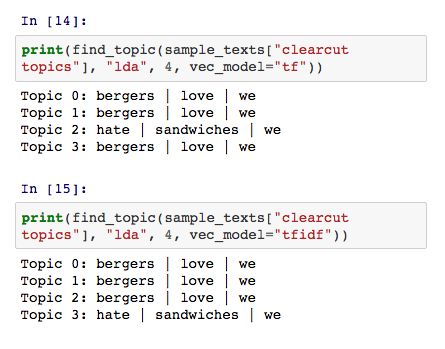
与 SVD 模型不同的是,LDA 模型所提取的主题非常好解释。以 clearcut-topics 数据集为例,LDA 模型中每个主题都有明确的关键词,它和SVD主要有以下两个区别:
- LDA 模型中可能存在重复的主题
- 不同的主题可以共享相同的关键词,比如单词 “we” 在所有的主题中都出现了。
此外,对 LDA 模型来说,采用不同的文本向量化方法也会得到不同的结果。
在 sklearn 中,参数 topic_word_prior 和 doc_topic_prior 分别用来控制 LDA 模型的两类参数。
其中 topic_word_prior 的默认值是(1/n_topics),这意味着主题中的每个词语服从均匀分布。

选择更小的 topic_word_prior 参数值可以提取粒度更小的主题信息,因为每个主题中都会选择更少的词语。

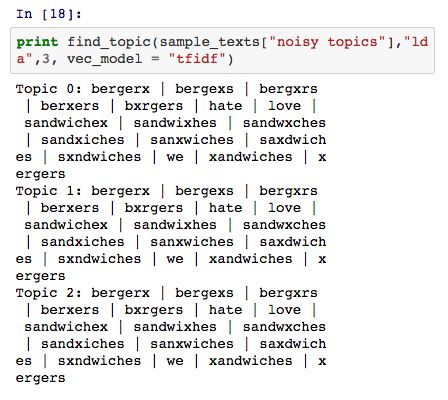
LDA 模型同样无法很好地处理 noisy topics 数据集,从下述结果中可以看出 LDA 模型提取的主题相当模糊:
2.3 NMF
NMF 可以视为 LDA模型的特例,从理论上来说,这两个模型之间的联系非常复杂。但是在实际应用中,NMF 经常被视为参数固定且可以获得稀疏解的 LDA 模型。虽然 NMF 模型的灵活性不如 LDA 模型,但是该模型可以很好地处理短文本数据集。
另一方面,NMF 最大的缺点是拟合结果的不一致——当我们设置过大的主题个数时,NMF 拟合的结果非常糟糕。相比之下,LDA模型的拟合结果更为稳健。
首先我们来看下 NMF 模型不一致的拟合结果。对于 clearcut topics 数据集来说,当我们设置提取5个主题时,其结果和真实结果非常相似:

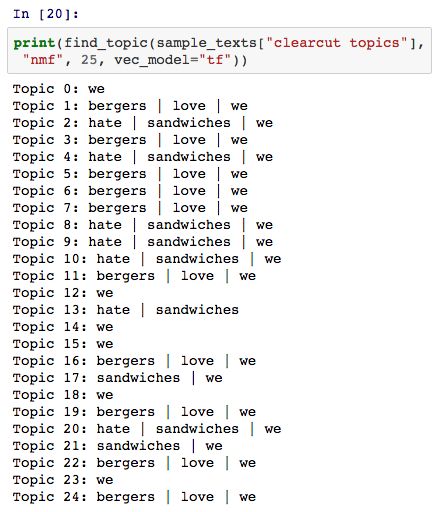
但是当我们增加主题个数时(远大于真实主题数2),NMF 模型将会得到一些奇异的结果:
相比之下,LDA模型的结果十分稳健。

对于非平衡数据集,设置好合适的主题个数,NMF 可以很好地提取出文档中的主题信息。

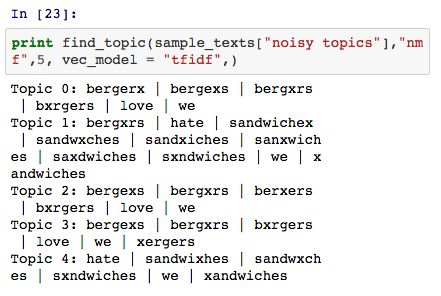
值得注意的是,NMF 是本文提到的四个模型中唯一一个能够较好地处理 noisy topics 数据的模型:
2.4 KMeans
类似于 KMeans 模型的聚类方法能够根据文档的向量形式对其进行分组。然而这个模型无法看成是主题模型,因为我们很难解释聚类结果中的关键词信息。
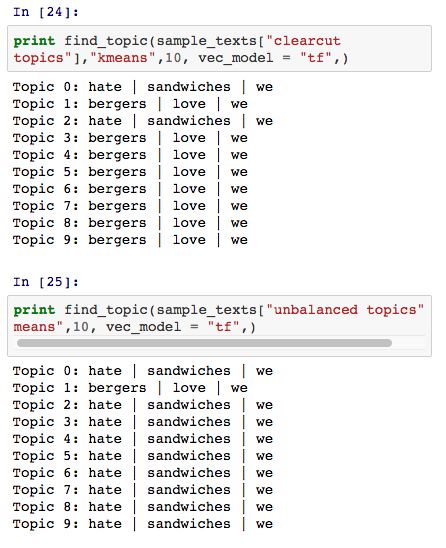
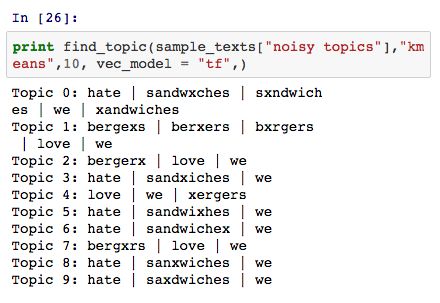
但是如果结合 TF或TFIDF方法,我们可以将 KMeans 模型的聚类中心视为一堆词语的概率组合:
2.5 寻找具有高语义相关的主题
最后,我将简单比较下不同的主题提取模型。大多数情况下,我们倾向于根据文档的主题分布情况对其进行分组,并根据关键词的分布情况来提取主题的信息。
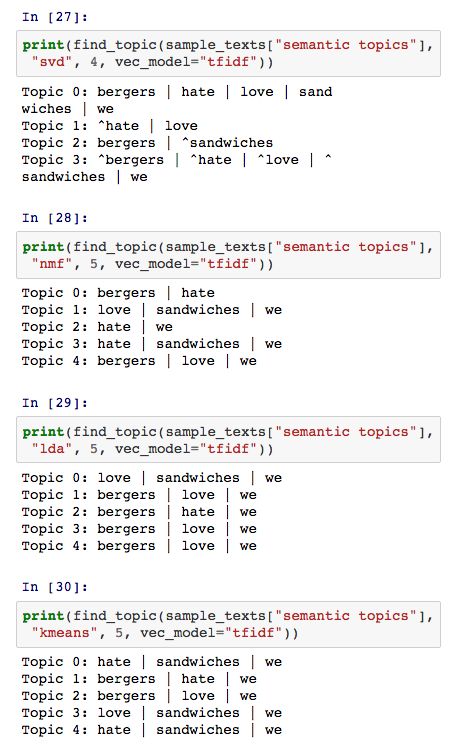
大多数研究者都认为词语的语义信息是由其上下文信息所决定的,比如 “love” 和 “hate”可以看成是语义相似的词语,因为这两个词都可以用在 “I _ apples” 的语境中。事实上,词向量最重要的一个研究就是如何构建词语、短语或者文档的向量形式,使得新的向量空间中仍然保留着语义信息。
找寻语义相同的词语不同于计算词语的共现频率。从下述的结果中可以看出,大多数主题提取模型只涉及到词语的共现频率,并没有考虑词语的语义信息,只有 SVD 模型简单涉及到语义信息。
需要注意的是,本文所采用的数据集是根据一定的规则随机生成的,所以下述结果更多的是用于说明不同模型之间的区别:
3. 总结
短文本数据集具有其独特的性质,建模时需要特别注意。
模型的选择依赖于主题的定义(共现频率高或者语义相似性)和主题提取的目的(文档表示或者是异常值检验)
-
我们可以首先采用 KMeans 或者 NMF 模型来快速获取文档的结构信息:
- 主题中词语的分布情况
- 文档中主题的分布情况
- 主题个数
- 每个主题中词语的个数
LDA 模型具有很好的灵活性,可以处理多种类型的文本数据。但是调参过程需要很好地理解数据结构,因此如果你想构建 LDA 模型,你最好先构建一个基准模型(KMEANS 或 NMF)
SVD 模型可以很好地提取出文本的主要信息。比如 SVD 模型可以很好地分析半结构化的数据(模板数据、截图或者html中的表格数据)。

原文链接:http://nbviewer.jupyter.org/github/dolaameng/tutorials/blob/master/topic-finding-for-short-texts/topics_for_short_texts.ipynb
原文作者:dolaameng
译者:Fibears