STL六大部件从语言层面讲:
- 容器Container是个class template
- 算法Algorithm是个function template
- 迭代器Iterator是个class template
- 仿函数Functors是个class template
- 适配器Adapter是个class template
- 分配器Allocator是个class template
1.算法
Algorithms看不见Containers,对其一无所知;所以它需要的一切信息都必须从Iterators取得,而Iterators(由Containers供应)必须能够回答Algorithm的所有提问,才能搭配该Algorithm的所有操作。
一般STL中的算法都是以下两种形式(其中的Algorithm是一种泛指,可以替代其他的函数名称)
template
Algorithm (Iterator itr1, Iterator itr2)
{
..........
}
template
Algorithm (Iterator itr1, Iterator itr2, Cmp comp)
{
..........
}
因为算法对容器的操作必须通过迭代器来进行,在进行算法的讨论之前有必要对迭代器进行分类。
1.1迭代器的分类
迭代器由容器来提供,各种容器的Iterators的5种iterator_category如下:

除了output_iterator_tag,其余四个之间是继承关系。
1.2各种容器迭代器的打印
(1)通过iterator_traits可以将容器传入的迭代器区分出种类:

(2)通过使用typeid函数来实现迭代器类型的打印:
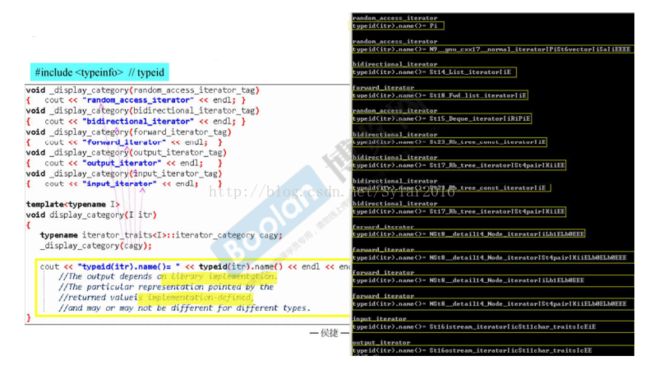
1.3iterator_category对算法的影响
前面说过算法需要迭代器的信息;而不同的算法对于不同的对象进行操作的时候,往往需要根据具体的情况处理。因此,在标准库中,我们表面上看到的算法都是接收迭代器就可以了,实际上算法在与操作对象的交流中早就知道了迭代器的类型,并且根据这个类型做出了不同的判断。这个判断的过程,一般是通过traits来实现的。
为了实现上述的思想,算法的结构可以大致表现为两个部分:
主函数部分,作为对外接口
次函数部分,作为对各种不同迭代器的分情况处理
下面以具体的例子进行说明。
(1)distance函数
distance函数用于计算两个迭代器之间的距离,具体的源代码如下:
template
inline iterator_traits::difference_type
_distance(InputIterator first, InputIterator last, input_iterator_tag) {
iterator_traits::difference_type = 0;
while (first != last) {
++ first;
++ n;
}
return n;
}
template
inline iterator_traits::difference_type
_distance(RandomAccessIterator first, RandomAccessIterator last,
random_access_iterator_tag) {
return last - first;
}
//--------------------------------------
template
inline iterator_traits::difference_type
distance(InputIterator first, InputIterator last) {
typedef typename
iterator_traits::iterator_category category;
return _distance(first, last, category());

从上图可以看出,主函数distance接收两个迭代器,返回两个迭代器之间的距离。在实现过程中主函数调用了名为_distance的次函数;该次函数需要指定迭代器的类型。主函数通过iterator_traits对接收的迭代器InputIterator的类型进行判断,然后选择正确的次函数进行距离的计算。
主函数有两个参数,次函数比主函数多一个参数,第三个参数category()由
iterator_traits判断出迭代器的种类后return给次函数,从而根据迭代器的类型选择不同的次函数。
(2)advance函数
advance函数的流程与distance函数的大同小异,具体如下图所示:

(3)copy函数
copy函数针对不同类型的
Iterator进行了详细的区分和判断,选择最高效的方法来完成复制。

(4)destroy函数
destroy函数和copy函数类似,也对不同类型的
Iterator进行了详细的区分和判断,选择最高效的方法来完成操作。
具体源代码及示意图如下所示:

(5)unique_copy函数
unique_copy()与之前的实现方法类似,但是要注意的一个地方是这个函数可以接受一个OutputIterator类型的迭代器作为其参数,OutputIterator类型迭代器的一个重要特点是:只写(write only)。具体如下图所示:

1.4算法对iterator_category的暗示
算法源代码对迭代器的类型并没有语法上的规定,但是会有暗示,具体如下图所示:

算法的效率与能否判断出iterator的分类有着重要的关系。算法源代码中对iterator_category都是采用暗示的方式,因为
算法主要为模版函数,而模版函数可以传入任何的类型,所以只是定义模版的时候定义为需要的迭代器名字,但并不是真正的区分类型。如果传入的类型不正确,编译会不通过,采用这样的方式来区分iterator的类型。
1.5相关算法分析
(1)算法accumulate

(2)
算法for_each

(3)算法
replace,replace_if , replace_copy

(4)算法
count, count_if

(4)算法
find、find_if

(5)算法sort

2.仿函数Functors
按照功能的不同,仿函数可分为算术类、逻辑类和关系类三种,具体如下图所示:

继承binary_function的意义在于,告诉算法传进来的是二元运算。仿函数在传递进算法的时候,需要告诉算法两个参与运算的类型,以及一个用于接受结果的类型。
如果没有继承,在某些场合也可以使用,但是当我们需要修改或者适配它本身的时候很可能就会出问题。
3.适配器Adapter
适配器按照类型的不同,可分为容器适配器、迭代器适配器和仿函数适配器三种,具体如下图所示:
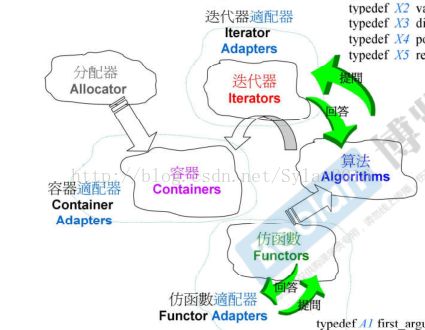
3.1容器适配器
容器适配器:stack、queue
3.2函数适配器
函数适配器:binder2nd
