Objc 的方法调用是运行时决定的,系统会根据 selector 动态地查找 IMP,那么这一过程究竟是怎样实现的?selector 是如何与 IMP 对应起来的?面对应用内部成千上万次的函数调用,它会不会造成性能瓶颈?基于这些疑问,本文将会从源码的角度来探究 Objc 的消息派发流程。
一切都源于 objc_msgSend
在 Objc 中我们这样去调用函数:
[obj func1]
但是编译器会将其翻译成如下代码:
objc_msgSend(obj, @selector(func1));
objc_msgSend 是处理方法调用的核心,Objc 中的函数调用都交由 objc_msgSend 执行,它会启动整个消息派发流程,寻找与 selector 相对应的函数实现,所以我们源码探究的切入点就是 objc_msgSend。从这里可以下载到 objc 的源码,本文用的是 objc4-680 版本。
objc_msgSend 是汇编语言写的,为什么是这样呢?一方面是性能上的考虑,动态查找 IMP 是一项耗时的过程,况且应用运行时会无数次的调用函数,因此需要 objc_msgSend 在执行速度上达到最优;另一方面是编程语言上的问题,因为程序员会设计出各式各样的函数,它们的参数也是数量不一、类型多变的,使用 C 语言很难写出函数原型来处理所有的情景,所以需要使用汇编来解决。
另一个需要注意的地方是函数的返回值,使用汇编可以解决可变参数的问题,但是函数返回值还是要区别对待。如果函数的返回值是 struct 或是 float,那么会有 objc_msgSend_stret 以及 objc_msgSend_fpret 版本与其对应,详情可见 message.h 文件。
以下是 ARM64 架构上的 objc_msgSend 代码(对应 objc-msg-arm64.s 文件):
ENTRY _objc_msgSend
MESSENGER_START
cmp x0, #0 // nil check and tagged pointer check
b.le LNilOrTagged // (MSB tagged pointer looks negative)
ldr x13, [x0] // x13 = isa
and x9, x13, #ISA_MASK // x9 = class
LGetIsaDone:
CacheLookup NORMAL // calls imp or objc_msgSend_uncached
LNilOrTagged:
b.eq LReturnZero // nil check
// tagged
adrp x10, _objc_debug_taggedpointer_classes@PAGE
add x10, x10, _objc_debug_taggedpointer_classes@PAGEOFF
ubfx x11, x0, #60, #4
ldr x9, [x10, x11, LSL #3]
b LGetIsaDone
LReturnZero:
// x0 is already zero
mov x1, #0
movi d0, #0
movi d1, #0
movi d2, #0
movi d3, #0
MESSENGER_END_NIL
ret
END_ENTRY _objc_msgSend
objc_msgSend 首先会去检测对象指针是否为 nil 或是 tagged pointer,如果是 nil,则返回的 IMP 也是 nil;如果是 tagged pointer,则对其进行特殊处理得到 isa 指针。接下来便是根据 isa 拿到 class 指针,然后进入最关键的一步:CacheLookup。
方法缓存
为了提升 IMP 的查询速度,系统为其设计了缓存。objc_msgSend 进行消息派发的第一步便是去缓存中查找 IMP,具体的查询流程在 CacheLookup 中。在阅读 CacheLookup 代码前,我们需要弄清楚 Objc 的方法缓存究竟是什么。
/// An opaque type that represents an Objective-C class.
typedef struct objc_class *Class;
struct objc_class : objc_object {
// Class ISA;
Class superclass;
cache_t cache; // formerly cache pointer and vtable
class_data_bits_t bits;
......
}
方法缓存存在于类对象中,而且每个类都有一份。类的结构推荐大家看这篇文章:从 NSObject 的初始化了解 isa,本文就不再赘述。在上面代码中,我们可以看到方法缓存的类型是 cache_t,它的定义如下:
struct cache_t {
struct bucket_t *_buckets;
mask_t _mask;
mask_t _occupied;
...
}
struct bucket_t {
cache_key_t _key;
IMP _imp;
...
}
其中的 mask_t 以及 cache_key_t 定义如下:
#if __LP64__
typedef uint32_t mask_t; // x86_64 & arm64 asm are less efficient with 16-bits
#else
typedef uint16_t mask_t;
#endif
typedef unsigned long uintptr_t;
typedef uintptr_t cache_key_t;
在 Objc 中,方法缓存被设计成一张 hash 表,对应于 cache_t 结构体中的 _buckets 属性。cache_t 中的 _mask 属性代表 _buckets 数组的最大索引(size = _mask + 1),_occupied 代表当前已存放的缓存数量,当 _occupied / _buckets.size > 3 / 4 时,系统会对 _buckets 数组扩容。以下是 Objc 存放缓存的算法,我们来看下缓存是怎样被填充的:
cache_t *getCache(Class cls)
{
assert(cls);
return &cls->cache;
}
cache_key_t getKey(SEL sel)
{
assert(sel);
return (cache_key_t)sel;
}
static void cache_fill_nolock(Class cls, SEL sel, IMP imp, id receiver)
{
// 1. 合法性检查
......
cache_t *cache = getCache(cls);
cache_key_t key = getKey(sel);
// 2. 判断是否需要扩容
......
// 3. 插入缓存
// Scan for the first unused slot and insert there.
// There is guaranteed to be an empty slot because the
// minimum size is 4 and we resized at 3/4 full.
bucket_t *bucket = cache->find(key, receiver);
if (bucket->key() == 0) cache->incrementOccupied();
bucket->set(key, imp);
}
系统首先会进行一些合法性检查以及判断是否需要对缓存进行扩容,接下来便是调用 cache->find(key, receiver) 函数寻找存放缓存的位置,最后调用 bucket->set(key, imp) 设置缓存。这样看来核心代码就在 cache->find 中了,我们来看它的实现:
static inline mask_t cache_hash(cache_key_t key, mask_t mask)
{
return (mask_t)(key & mask);
}
static inline mask_t cache_next(mask_t i, mask_t mask) {
return i ? i-1 : mask;
}
bucket_t * cache_t::find(cache_key_t k, id receiver)
{
assert(k != 0);
bucket_t *b = buckets();
mask_t m = mask();
mask_t begin = cache_hash(k, m);
mask_t i = begin;
do {
if (b[i].key() == 0 || b[i].key() == k) {
return &b[i];
}
} while ((i = cache_next(i, m)) != begin);
// hack
Class cls = (Class)((uintptr_t)this - offsetof(objc_class, cache));
cache_t::bad_cache(receiver, (SEL)k, cls);
}
系统通过 cache_hash 函数对 selector 进行简单的运算,得到 hash 表的索引,然后去 _buckets 中取出缓存,如果为空或是发现之前已经记录过,那么就返回缓存,否则就依次遍历 hash 表来寻找合适的位置。以上便是 Objc 用于存放缓存的核心算法,只要把相关的数据结构弄清楚了就很容易看懂,那么接下来就来看 CacheLookup 到底做了些什么事情:
.macro CacheLookup
// x1 = SEL, x9 = isa
ldp x10, x11, [x9, #CACHE] // x10 = buckets, x11 = occupied|mask
and w12, w1, w11 // x12 = _cmd & mask
add x12, x10, x12, LSL #4 // x12 = buckets + ((_cmd & mask)<<4)
ldp x16, x17, [x12] // {x16, x17} = *bucket
1: cmp x16, x1 // if (bucket->sel != _cmd)
b.ne 2f // scan more
CacheHit $0 // call or return imp
2: // not hit: x12 = not-hit bucket
CheckMiss $0 // miss if bucket->cls == 0
cmp x12, x10 // wrap if bucket == buckets
b.eq 3f
ldp x16, x17, [x12, #-16]! // {x16, x17} = *--bucket
b 1b // loop
3: // wrap: x12 = first bucket, w11 = mask
add x12, x12, w11, UXTW #4 // x12 = buckets+(mask<<4)
// Clone scanning loop to miss instead of hang when cache is corrupt.
// The slow path may detect any corruption and halt later.
ldp x16, x17, [x12] // {x16, x17} = *bucket
1: cmp x16, x1 // if (bucket->sel != _cmd)
b.ne 2f // scan more
CacheHit $0 // call or return imp
2: // not hit: x12 = not-hit bucket
CheckMiss $0 // miss if bucket->cls == 0
cmp x12, x10 // wrap if bucket == buckets
b.eq 3f
ldp x16, x17, [x12, #-16]! // {x16, x17} = *--bucket
b 1b // loop
3: // double wrap
JumpMiss $0
.endmacro
虽然 CacheLookup 都是用汇编写的,但是有了上面的基础再配合代码注释,理解起来并不困难。大体上来说,还是先通过 selector 计算得到 hash 表的索引,然后去 buckets 中寻找缓存,若是有冲突就
顺位向下寻找,如果最后找到了,就执行相应的 IMP,否则就交由 JumpMiss 处理:
.macro JumpMiss
.if $0 == NORMAL
b __objc_msgSend_uncached_impcache
.else
b LGetImpMiss
.endif
由于最初我们是这样调用 CacheLookup 的:CacheLookup NORMAL ,所以当缓存没有命中时,系统会跳转到 __objc_msgSend_uncached_impcache 进行下一步的处理。
STATIC_ENTRY __objc_msgSend_uncached_impcache
// 保存寄存器中的值
......
// receiver and selector already in x0 and x1
mov x2, x9
bl __class_lookupMethodAndLoadCache3
// imp in x0
mov x17, x0
// 恢复寄存器
......
br x17
END_ENTRY __objc_msgSend_uncached_impcache
可以看到 __objc_msgSend_uncached_impcache 最终调用 __class_lookupMethodAndLoadCache3 函数来处理缓存失效的情况,同时它也是我们接下来要讲的消息派发的第二阶段:消息发送。
消息发送
消息发送是在缓存失效后启动的,主要的作用就是在类自身以及继承体系中寻找 IMP,与此外还给了程序员动态添加 IMP 的机会。前面我们提到系统在缓存失效后会调用 __class_lookupMethodAndLoadCache3 函数,但是 __class_lookupMethodAndLoadCache3 仅仅调用了 lookUpImpOrForward 函数(参见 objc-runtime-new.mm 文件):
/***********************************************************************
* _class_lookupMethodAndLoadCache.
* Method lookup for dispatchers ONLY. OTHER CODE SHOULD USE lookUpImp().
* This lookup avoids optimistic cache scan because the dispatcher
* already tried that.
**********************************************************************/
IMP _class_lookupMethodAndLoadCache3(id obj, SEL sel, Class cls)
{
return lookUpImpOrForward(cls, sel, obj,
YES/*initialize*/, NO/*cache*/, YES/*resolver*/);
}
看来 lookUpImpOrForward 函数是消息发送的核心,我们来看它到底做了些什么:
- 在缓存中寻找 IMP。由于之前对缓存的查询以失败告终,所以 _class_lookupMethodAndLoadCache3 调用 lookUpImpOrForward 函数时传入的 cache 参数为 NO,因此这里并不会触发缓存的查询操作。
Class curClass;
IMP imp = nil;
Method meth;
bool triedResolver = NO;
runtimeLock.assertUnlocked();
// Optimistic cache lookup
if (cache) {
imp = cache_getImp(cls, sel);
if (imp) return imp;
}
-
进行一些准备工作,realizeClass 用来申请 class_rw_t 的可读写空间,_class_initialize 是对类进行初始化。
if (!cls->isRealized()) { rwlock_writer_t lock(runtimeLock); realizeClass(cls); } if (initialize && !cls->isInitialized()) { _class_initialize (_class_getNonMetaClass(cls, inst)); } 准备工作结束后,开始消息发送的流程。
// The lock is held to make method-lookup + cache-fill atomic
// with respect to method addition. Otherwise, a category could
// be added but ignored indefinitely because the cache was re-filled
// with the old value after the cache flush on behalf of the category.
retry:
runtimeLock.read();
// Ignore GC selectors
if (ignoreSelector(sel)) {
imp = _objc_ignored_method;
cache_fill(cls, sel, imp, inst);
goto done;
}
// Try this class's cache.
imp = cache_getImp(cls, sel);
if (imp) goto done;
系统先是调用 runtimeLock.read() 加锁,然后判断 sel 是否与垃圾回收相关,是的话就返回 _objc_ignored_method,否则就去缓存中查找,如果缓存未命中,就进入下一步。
- 调用 getMethodNoSuper_nolock 在类自身的方法列表中查找,如果找到,则调用 log_and_fill_cache 填充缓存并结束查询流程,否则进入下一步。
// Try this class's method lists.
meth = getMethodNoSuper_nolock(cls, sel);
if (meth) {
log_and_fill_cache(cls, meth->imp, sel, inst, cls);
imp = meth->imp;
goto done;
}
log_and_fill_cache 最终会调用到 cache_fill_nolock 函数,也就是我们之前讲的存放缓存的那一套流程。
- 按照继承体系依次在父类的缓存以及方法列表中寻找 IMP。
// Try superclass caches and method lists.
curClass = cls;
while ((curClass = curClass->superclass)) {
// Superclass cache.
imp = cache_getImp(curClass, sel);
if (imp) {
if (imp != (IMP)_objc_msgForward_impcache) {
// Found the method in a superclass. Cache it in this class.
log_and_fill_cache(cls, imp, sel, inst, curClass);
goto done;
}
else {
// Found a forward:: entry in a superclass.
// Stop searching, but don't cache yet; call method
// resolver for this class first.
break;
}
}
// Superclass method list.
meth = getMethodNoSuper_nolock(curClass, sel);
if (meth) {
log_and_fill_cache(cls, meth->imp, sel, inst, curClass);
imp = meth->imp;
goto done;
}
}
如果在父类中找到了 IMP,系统会将其填充到子类的方法缓存中(不会填充到父类的缓存),然后结束流程。如果在父类中没有找到 IMP 或者找到的 IMP 是 _objc_msgForward_impcache,那么系统会结束对父类的查询,然后进入下一步。
- 动态方法解析。
// No implementation found. Try method resolver once.
if (resolver && !triedResolver) {
runtimeLock.unlockRead();
_class_resolveMethod(cls, sel, inst);
// Don't cache the result; we don't hold the lock so it may have
// changed already. Re-do the search from scratch instead.
triedResolver = YES;
goto retry;
}
系统使用 runtimeLock.unlockRead() 解锁,然后调用 _class_resolveMethod 函数给程序员一个动态添加 IMP 的机会:
void _class_resolveMethod(Class cls, SEL sel, id inst)
{
if (! cls->isMetaClass()) {
// try [cls resolveInstanceMethod:sel]
_class_resolveInstanceMethod(cls, sel, inst);
}
else {
// try [nonMetaClass resolveClassMethod:sel]
// and [cls resolveInstanceMethod:sel]
_class_resolveClassMethod(cls, sel, inst);
if (!lookUpImpOrNil(cls, sel, inst,
NO/*initialize*/, YES/*cache*/, NO/*resolver*/))
{
_class_resolveInstanceMethod(cls, sel, inst);
}
}
}
_class_resolveMethod 首先会判断 cls 是否是元类,如果不是元类,就去调用 _class_resolveInstanceMethod 来动态解析实例方法,否则就调用 _class_resolveClassMethod 动态解析类方法,如果 _class_resolveClassMethod 没有起到作用,就调用 _class_resolveInstanceMethod 再次解析。
这里以 _class_resolveInstanceMethod 为例:
static void _class_resolveInstanceMethod(Class cls, SEL sel, id inst)
{
if (! lookUpImpOrNil(cls->ISA(), SEL_resolveInstanceMethod, cls,
NO/*initialize*/, YES/*cache*/, NO/*resolver*/))
{
// Resolver not implemented.
return;
}
BOOL (*msg)(Class, SEL, SEL) = (typeof(msg))objc_msgSend;
bool resolved = msg(cls, SEL_resolveInstanceMethod, sel);
// Cache the result (good or bad) so the resolver doesn't fire next time.
// +resolveInstanceMethod adds to self a.k.a. cls
IMP imp = lookUpImpOrNil(cls, sel, inst,
NO/*initialize*/, YES/*cache*/, NO/*resolver*/);
// 打印日志
......
}
实例方法的动态解析需要程序员实现 + (BOOL)resolveInstanceMethod:(SEL)sel; 方法,在其中为类添加 IMP, _class_resolveInstanceMethod 函数运行时会去调用这个方法,然后利用 lookUpImpOrNil 函数缓存结果。如果需要动态添加类方法,你需要实现 + (BOOL)resolveClassMethod:(SEL)sel;。
动态解析结束后,goto retry; 会重复之前的查找流程,这会是消息发送流程的最后一次尝试。
- retry 结束后,如果 IMP 还是没有找到,那么系统就返回 _objc_msgForward_impcache,进入消息转发阶段。
// No implementation found, and method resolver didn't help.
// Use forwarding.
imp = (IMP)_objc_msgForward_impcache;
cache_fill(cls, sel, imp, inst);
done:
runtimeLock.unlockRead();
// paranoia: look for ignored selectors with non-ignored implementations
assert(!(ignoreSelector(sel) && imp != (IMP)&_objc_ignored_method));
// paranoia: never let uncached leak out
assert(imp != _objc_msgSend_uncached_impcache);
return imp;
消息转发
消息转发是 Objc 消息派发的第三步,也是最后一步,不过 _objc_msgForward_impcache 只是内部使用的函数指针,它需要被转为 _objc_msgForward 才可以被外部调用。
/********************************************************************
*
* id _objc_msgForward(id self, SEL _cmd,...);
*
* _objc_msgForward is the externally-callable
* function returned by things like method_getImplementation().
* _objc_msgForward_impcache is the function pointer actually stored in
* method caches.
*
********************************************************************/
STATIC_ENTRY __objc_msgForward_impcache
MESSENGER_START
nop
MESSENGER_END_SLOW
// No stret specialization.
b __objc_msgForward
END_ENTRY __objc_msgForward_impcache
而 _objc_msgForward 也不是终点,它仅仅调用 __objc_forward_handler:
ENTRY __objc_msgForward
adrp x17, __objc_forward_handler@PAGE
ldr x17, [x17, __objc_forward_handler@PAGEOFF]
br x17
END_ENTRY __objc_msgForward
那么 __objc_forward_handler 究竟是什么,我们可以在 objc-runtime.mm 文件中找到它的默认实现:
// Default forward handler halts the process.
__attribute__((noreturn)) void
objc_defaultForwardHandler(id self, SEL sel)
{
_objc_fatal("%c[%s %s]: unrecognized selector sent to instance %p "
"(no message forward handler is installed)",
class_isMetaClass(object_getClass(self)) ? '+' : '-',
object_getClassName(self), sel_getName(sel), self);
}
void *_objc_forward_handler = (void*)objc_defaultForwardHandler;
void objc_setForwardHandler(void *fwd, void *fwd_stret)
{
_objc_forward_handler = fwd;
#if SUPPORT_STRET
_objc_forward_stret_handler = fwd_stret;
#endif
}
用来设置 __objc_forward_handler 的函数是 objc_setForwardHandler,但是在苹果开源的代码中并没有看到它在哪里被调用,那么就在实际项目中打个断点看一下:
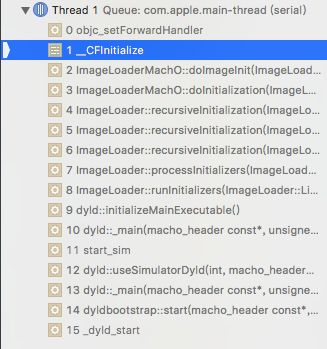
它是在
__CFInitialize 函数中被调用,调用时传入
__forwarding_prep_0___ 以及
__forwarding_prep_1___ 参数:

结合
objc_setForwardHandler 的代码,可以看出
__forwarding_prep_0___ 对应
_objc_forward_handler,而
__forwarding_prep_1___ 对应
_objc_forward_stret_handler。然而在源码中依旧没有看到
__forwarding_prep_0___,那么就反汇编看一下
__forwarding_prep_0___ 都做了些什么:
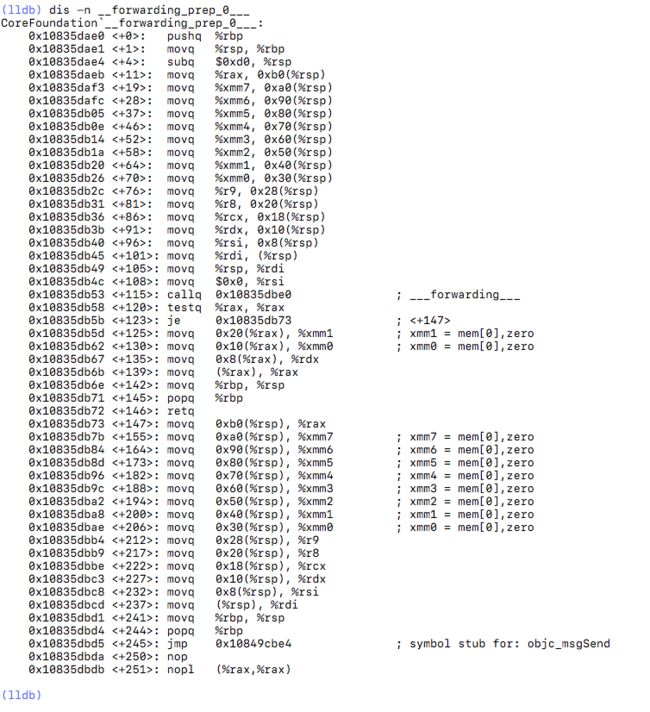
__forwarding_prep_0___ 内部调用 ___forwarding___ 函数,如果 ___forwarding___ 的结果不为空,则将结果返回,否则调用 objc_msgSend,下一步应该就是抛出 doesNotRecognizeSelector 错误了。使用 dis -n ___forwarding___ 命令可以查看 ___forwarding___ 的内部逻辑,这里就不截图了(图片大概有两个外接显示器那么高),下面简单总结一下 ___forwarding___ 内部的流程:
如果用户实现了 forwardingTargetForSelector 函数,就用它拿到用于消息转发的新的 target,如果 target 不为空并且不是当前对象,那么就调用 objc_msgSend(target, sel, ...) 函数,否则进入下一步。
判断当前对象是否为僵尸对象,是的话就会抛出异常:
如果用户实现了 methodSignatureForSelector 函数并且生成的签名不为空,系统就会根据它创建 NSInvocation 对象,并将其作为参数传递给 forwardInvocation 函数,否则进入下一步。
判断 selector 是否在 runtime 注册过,没有的话会出现这样的提错误信息:
否则就是大家喜闻乐见的的 doesNotRecognizeSelector 错误,如果连 doesNotRecognizeSelector 也没有实现,错误信息会是这样:
以上就是消息转发的流程。
总结
上面的内容涵盖了 Objc 消息派发的三部曲:1. 缓存查找;2. 消息发送;3. 消息转发,由于内容十分庞杂,所以这里总结下消息派发的流程来帮助大家理解:
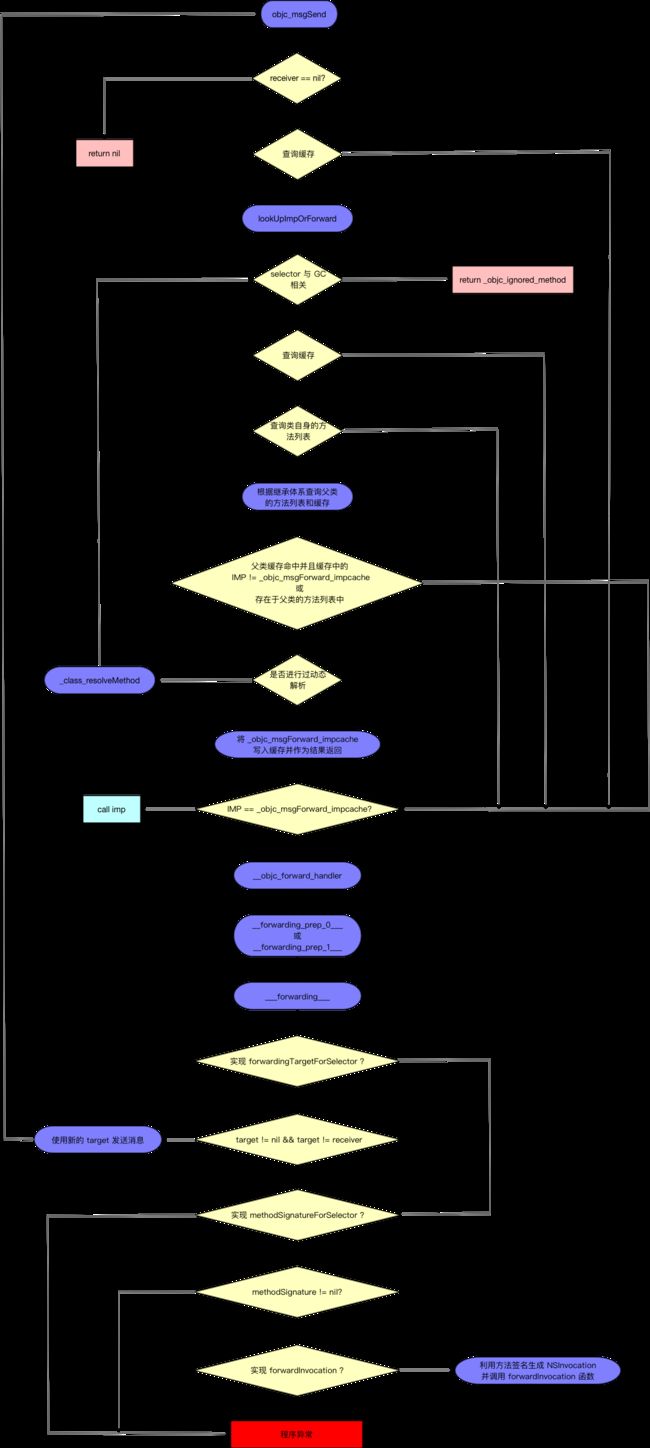
enmmmmmmm,终于写完了,断断续续花了好多时间,中途还差点弃坑,不过最终还是完成了,真是可喜可贺,晚上给自己加个鸡腿