目录
- Spinnaker 介绍
- 环境、软件准备
- 安装 Development Spinnaker
- 配置依赖环境
- 配置并安装 Spinnaker
- 演示 Spinnaker Pipeline
- 演示 Spinnaker 集成 Jenkins
1、Spinnaker 介绍
Spinnaker 是 Netflix 的开源项目,是一个持续交付平台,它定位于将产品快速且持续的部署到多种云平台上。Spinnaker 通过将发布和各个云平台解耦,来将部署流程流水线化,从而降低平台迁移或多云品台部署应用的复杂度,它本身内部支持 Google、AWS EC2、Microsoft Azure、Kubernetes和 OpenStack 等云平台,并且它可以无缝集成其他持续集成(CI)流程,如 git、Jenkins、Travis CI、Docker registry、cron 调度器等。简而言之,Spinnaker 是致力于提供在多种平台上实现开箱即用的集群管理和部署功能的平台。
Spinnaker 官网 文档可以了解到,Spinnaker 主要包含两大块内容,集群管理和部署管理。
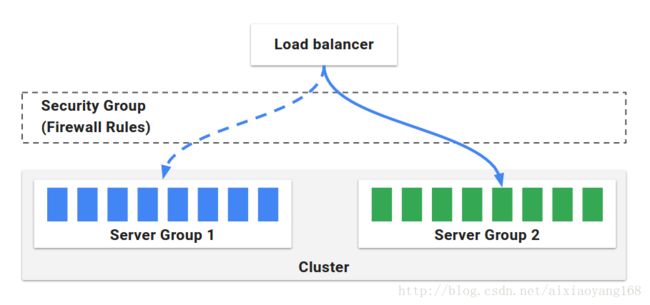
集群管理主要用于管理云上的资源,它分为以下几个块:
- Server Group:服务组,是资源管理单位,识别可部署组件和基础配置设置,它并且关联了一个负载均衡器和安全组,当部署完毕后,服务组就相当于一组运行中的软件实例集合,如(VM 实例,Kubernetes pods)。
- Cluster:集群,由用户定义的,对服务组的逻辑分组。
- Applications:应用,是对集群的逻辑分组。
- Load Balancer:负载均衡,用于将外部网络流量重定向到服务组中的机器实例,还可以指定一系列规则,用来对服务组中的机器实例做健康监测。
- Security Group:安全组,定义了网络访问权限,由IP、端口和通信协议组成的防火墙规则。
部署管理功能用于创建一个持续交付流程,它可分为管道和阶段两大部分。
- 管道

部署管理的核心是管道,在Spinnaker的定义中,管道由一系列的阶段(stages)组成。管道可以人工触发,也可以配置为自动触发,比如由 Jenkins Job 完成时、Docker Images 上传到仓库时,CRON 定时器、其他管道中的某一阶段。同时,管道可以配置参数和通知,可以在管道一些阶段上执行时发送邮件消息。Spinnaker 已经内置了一些阶段,如执行自定义脚本、触发 Jenkins 任务等。
- 阶段 阶段在 Spinnaker 中,可以作为管道的一个自动构建模块的功能组成。我们可以随意在管道中定义各个阶段执行顺序。Spinnaker 提供了很多阶段供我们选择使用,比如执行发布(Deploy)、执行自定义脚本 (script)、触发 Jenkins 任务 (jenkins)等,功能很强大。
- 部署策略
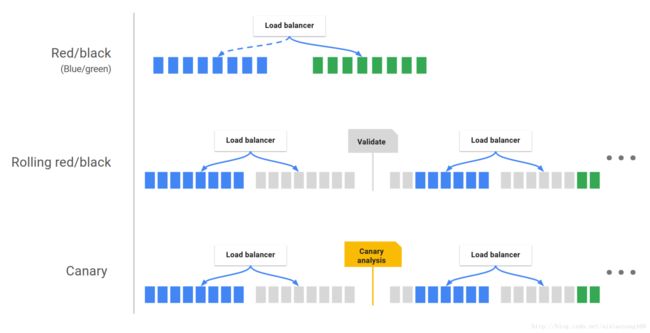
Spinnaker 支持精细的部署策略,比如 红/黑(蓝/绿)部署,多阶段环境部署,滚动红/黑策略,canary 发布等。用户可以为每个环境使用不同部署策略,比如,测试环境可以使用红/黑策略,生产环境使用滚动红/黑策略,它封装好了必须的步骤,用户不需要复杂操作,就可以实现企业级上线。
2、环境、软件准备
Spinnaker 安装在 官网文档 中写的很详细,可以使用一种全新的 CLI 工具 halyard,它帮助管理员更容易地安装,配置以及升级用于生产环境的 Spinnaker 实例,但是支持的是 Ubuntu 环境,而且部分资源依赖国外地址,SO 我尝试了一下,由于网络的原因,安装过程中没有能够继续下去。。。 所以,这里我选择了 Spinnaker GitHub 安装 Development 版本,配置虽然稍复杂一些,但是作为初试阶段,能够跑起来也是不错的。Development 版本目前只在 Ubuntu 14.04 LTS 和 Mac OS X 10.11 上测试过,由于手头没有现成的 Ubuntu 环境,就直接在本机 Mac OS 上尝试安装一下吧。
- git: version 2.10.1
- JDK8: version 1.8.0_91
- Redis: version 4.0.2
- Cassandra: verison 3.11.1
- Packer: version 1.1.2
- Docker: version 17.09.0-ce
- Jenkins: version 2.46.2
注意:Development 版本安装,需要获取 GitHub 源码编译安装,其中还需要拉取各个组件模块源码,所以需要安装好 Git。JDK8、Redis、Cassandra、Packer 是安装 Spinnaker 组件时需要依赖的。Jenkins 非必须安装,这里我下边需要演示集成 Jenkins,所以使用 Docker 快速安装一下。下边会详细介绍每个组件的作用,以及安装方式。
3、安装 Development Spinnaker
安装 Spinnaker 之前,有必要详细描述一下 Spinnaker 架构所依赖的各个组件。
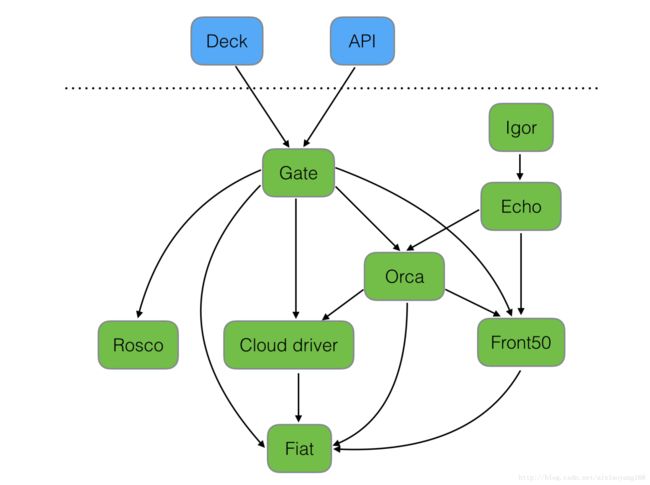
- Deck:面向用户 UI 界面组件,提供直观简介的操作界面,可视化操作发布部署流程。
- API: 面向调用 API 组件,我们可以不使用提供的 UI,直接调用 API 操作,由它后台帮我们执行发布等任务。
- Gate:是 API 的网关组件,可以理解为代理,所有请求由其代理转发。
- Rosco:是构建 beta 镜像的组件,需要配置 Packer 组件使用。
- Orca:是核心流程引擎组件,用来管理流程。
- Igor:是用来集成其他 CI 系统组件,如 Jenkins 等一个组件。
- Echo:是通知系统组件,发送邮件等信息。
- Front50:是存储管理组件,需要配置 Redis、Cassandra 等组件使用。
- Cloud driver 是它用来适配不同的云平台的组件,比如 Kubernetes,Google、AWS EC2、Microsoft Azure 等。
- Fiat 是鉴权的组件,配置权限管理,支持 OAuth、SAML、LDAP、GitHub teams、Azure groups、 Google Groups 等。
以上组件除了核心组件外,一些组价可选择配置是否启动,比如不做权限管理的话,Fiat 就可以不启动,不集成其他 CI 的话,那就可以不启动 Igor 组件等。这些都可以在配置文件中配置,下边会说到。Development 版本,各个组件独立服务运行,有各自的服务端口,且各个组件都有自己的独立的项目 GitHub 地址。
好了,讲了这么多 Spinnaker 相关的东西了,接下来开始安装 Spinnaker。
3.1 配置依赖环境
Spinnaker 平台需要依赖部分环境,所以为了防止下边安装过程中出现错误,可以提前安装一下。
- JDK8
- Redis
- Cassandra
- Packer
1、由于 Spinnaker 核心服务是由 SpringBoot 框架写的,所以需要安装 JDK8 2、Spinnaker 需要使用 Redis 存储数据,所以也需要安装。 3、Cassandra 是非关系型数据库存储,默认 Front50 组件和 Echo 组件配置使用该存储,也需要安装。 4、Packer 是开源的支持多平台创建镜像工具,rosco 组件配置使用该工具,也需要安装。
以上依赖环境可以去官网下载安装,我这里本机 JDK8 环境已经安装,其他的因为本机是 Mac OS 环境,那么我选择使用 homebrew 安装,非常方便。
$ brew install redis cassandra packer
安装完毕后,我们启动 redis 和 cassandra,packer 不需要启动,Spinnaker 可以连接调用即可。
3.2 配置并安装 Spinnaker
# clone Spinnaker 代码
$ mkdir /Users/wanyang3/spinnaker
$ cd /Users/wanyang3/spinnaker $ git clone https://github.com/spinnaker/spinnaker.git ... # clone Spinnaker 其他个组件代码 $ mkdir build $ cd build $ ../spinnaker/dev/refresh_source.sh --pull_origin ...
说明一下,Spinnaker 项目里面包含核心配置文件,但不包含各组件代码,所以需要创建 build 文件夹,并执行 refresh_source.sh 脚本,会依次 clone 各个组件代码,这里得花点时间了。执行完毕后,显示目录如下:
$ ls -alt /Users/wanyang3/spinnaker/build
total 24 drwxr-xr-x 17 wanyang3 staff 578 11 23 14:49 . drwxr-xr-x 7 wanyang3 staff 238 11 28 15:43 .. -rw-r--r--@ 1 wanyang3 staff 6148 11 23 14:49 .DS_Store drwxr-xr-x 14 wanyang3 staff 476 11 17 14:32 citest drwxr-xr-x 45 wanyang3 staff 1530 11 17 14:46 clouddriver drwxr-xr-x 49 wanyang3 staff 1666 11 21 14:32 deck -rw-r--r-- 1 wanyang3 staff 175 11 17 16:24 dump.rdb drwxr-xr-x 32 wanyang3 staff 1088 11 17 15:14 echo drwxr-xr-x 30 wanyang3 staff 1020 11 17 14:32 fiat drwxr-xr-x 35 wanyang3 staff 1190 11 17 14:53 front50 drwxr-xr-x 25 wanyang3 staff 850 11 20 14:13 gate drwxr-xr-x 34 wanyang3 staff 1156 11 17 14:32 halyard drwxr-xr-x 24 wanyang3 staff 816 11 20 17:49 igor drwxr-xr-x 19 wanyang3 staff 646 11 22 11:57 logs drwxr-xr-x 49 wanyang3 staff 1666 11 17 15:11 orca drwxr-xr-x 25 wanyang3 staff 850 11 17 14:46 rosco drwxr-xr-x 18 wanyang3 staff 612 11 17 14:32 spinnaker-monitoring
接下来,我们需要配置一下 Spinnaker。
$ cd /Users/wanyang3/spinnaker
$ mkdir -p $HOME/.spinnaker $ touch $HOME/.spinnaker/spinnaker-local.yml $ chmod 600 $HOME/.spinnaker/spinnaker-local.yml $ cp spinnaker/config/spinnaker.yml $HOME/.spinnaker/spinnaker-local.yml # 修改配置文件 $ vim $HOME/.spinnaker/spinnaker-local.yml
注意:这里的文件 spinnaker-local.yml 是 Spinnaker 核心配置文件,这里可以配置各个组件是否启动或关闭,以及其他参数。同时
这里有必要在详细说一下,通过对 spinnaker-local.yml 配置文件的分析,Spinnaker 各个组件默认启动端口如下:
|
组件 |
端口 |
依赖组件 |
端口 |
|---|---|---|---|
|
Clouddriver |
7002 |
Redis |
6379 |
|
Fiat |
7003 |
||
|
Front50 |
8080 |
Cassandra |
9042 |
|
Orca |
8083 |
||
|
Gate |
8084 |
||
|
Rosco |
8087 |
||
|
Igor |
8088 |
||
|
Echo |
8089 |
||
|
Deck |
9000 |
接下来可以启动 Spinnaker 服务了。
$ cd /Users/wanyang3/spinnaker/build
$ ../spinnaker/dev/run_dev.sh [service]
注意:[service] 参数可指定一个或多个组件名称,若指定则只启动指定组件,若不指定,默认启动所有组件,这里我们就不指定了,启动所有配置开启的组件。如果正常的话,可以看到输出日志中依次启动各个组件,然后执行 gradle 编译,最后完成启动 Spinnaker。
Starting clouddriver
Starting front50
Starting orca
Starting rosco
Starting echo
Starting igor
Waiting for clouddriver to start accepting requests on port 7002...
...
:clouddriver-web:compileJava UP-TO-DATE :clouddriver-web:compileGroovy UP-TO-DATE :clouddriver-web:processResources UP-TO-DATE :clouddriver-web:classes UP-TO-DATE :clouddriver-web:findMainClass :clouddriver-web:bootRun ... 2017-11-28 17:34:06.440 INFO 6648 --- [ main] .d.s.w.r.o.CachingOperationNameGenerator : Generating unique operation named: getUsingGET_2 2017-11-28 17:34:06.443 INFO 6648 --- [ main] .d.s.w.r.o.CachingOperationNameGenerator : Generating unique operation named: listUsingGET_8 2017-11-28 17:34:06.445 INFO 6648 --- [ main] .d.s.w.r.o.CachingOperationNameGenerator : Generating unique operation named: listUsingGET_9 2017-11-28 17:34:06.498 INFO 6648 --- [ main] c.n.s.c.listeners.OperationsTypeChecker : Found 0 cloud provider annotations: [] 2017-11-28 17:34:06.567 INFO 6648 --- [ main] s.b.c.e.t.TomcatEmbeddedServletContainer : Tomcat started on port(s): 7002 (http) 2017-11-28 17:34:06.578 INFO 6648 --- [ main] com.netflix.spinnaker.clouddriver.Main : Started Main in 19.568 seconds (JVM running for 22.055)
不过这里我发现了几个问题。
问题一:如果我们启动之前未启动 Redis 服务,那么这里日志就会输出 redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool 异常了。
问题二:本机测试时并没有一次启动完所有服务,大部分可以正常启动,Fiat、Gate、Deck 三个组件未启动,Fiat 未启动可以理解,是因为配置文件中设置默认不启动。Gate、Deck 怎么还得自己去手动启动呢。。。
问题三:第一次启动时,发现 front50 未启动,报错类似 Can not find keyspaces 'front50' 这样,这是因为未在 Cassandra 中为创建 front50 的 keyspaces。可通过如下方式查看:
$ cqlsh
Connected to Test Cluster at 127.0.0.1:9042. [cqlsh 5.0.1 | Cassandra 3.11.1 | CQL spec 3.4.4 | Native protocol v4] Use HELP for help. cqlsh> describe keyspaces; system_schema system system_traces system_auth system_distributed
可以执行一下命令创建:
cqlsh> CREATE KEYSPACE IF NOT EXISTS front50
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 }; cqlsh> describe keyspaces; system_schema system front50 system_traces system_auth system_distributed
后来查看了下 Spinnaker 执行脚本,发现是有执行创建该 keyspaces 的代码的,不过好像我第一次安装的时候并没有执行。。。
$ cat /Users/wanyang3/spinnaker/spinnaker/pylib/spinnaker/change_cassandra.py ... print 'Installing cassandra keyspaces...' os.system('cqlsh -f "/opt/spinnaker/cassandra/create_echo_keyspace.cql"') os.system('cqlsh -f "/opt/spinnaker/cassandra/create_front50_keyspace.cql"') ...
要是碰到没有执行安装 echo 和 front50 keyspace 导致这两个组件报错的话,可以手动执行一下,创建语句 Spinnaker 已经提供好了,cqlsh 客户端执行
好了,现在大部分服务已经启动好了,但是 deck 和 gate 服务还没有启动起来呢!分别进入到 build 目录下 deck 和 gate 目录,先启动 gate 在启动 deck,因为 deck 中请求地址是直接连接 gate,然后 gate 网关在对请求做转发。
$ cd /Users/wanyang3/spinnaker/build/gate
$ ./start_dev.sh
如果确定组件是否启动成功呢?我们可以简单的 lsof -i : 查看端口情况 也可以分别查看各个组件的日志,看下各组件启动时是否有异常信息。
$ ls -alt /Users/wanyang3/spinnaker/build/logs total 46168 drwxr-xr-x 19 wanyang3 staff 646 11 22 11:57 . drwxr-xr-x 17 wanyang3 staff 578 11 29 09:23 .. -rw-r--r-- 1 wanyang3 staff 89 11 28 17:33 clouddriver.err -rw-r--r-- 1 wanyang3 staff 76945 11 29 09:53 clouddriver.log -rw-r--r-- 1 wanyang3 staff 2529 11 22 11:57 deck.err -rw-r--r-- 1 wanyang3 staff 3586 11 22 11:57 deck.log -rw-r--r-- 1 wanyang3 staff 507 11 28 17:33 echo.err -rw-r--r-- 1 wanyang3 staff 3408986 11 29 09:56 echo.log -rw-r--r-- 1 wanyang3 staff 0 11 17 14:40 fiat.err -rw-r--r-- 1 wanyang3 staff 788 11 28 17:33 front50.err -rw-r--r-- 1 wanyang3 staff 62153 11 28 17:34 front50.log -rw-r--r-- 1 wanyang3 staff 450 11 27 17:05 gate.err -rw-r--r-- 1 wanyang3 staff 2192698 11 27 17:05 gate.log -rw-r--r-- 1 wanyang3 staff 89 11 28 17:33 igor.err -rw-r--r-- 1 wanyang3 staff 17736046 11 29 09:56 igor.log -rw-r--r-- 1 wanyang3 staff 89 11 28 17:32 orca.err -rw-r--r-- 1 wanyang3 staff 63183 11 28 17:33 orca.log -rw-r--r-- 1 wanyang3 staff 89 11 28 17:33 rosco.err -rw-r--r-- 1 wanyang3 staff 41101 11 28 17:33 rosco.log
接下来启动 deck 组件,deck 启动的话,会稍微麻烦一下,可以参考 Deck GitHub Doc 文档说明操作。
首先需要安装依赖环境 node 和 yarn
$ brew install node yarn
这里我们是本地搭建的 develop 版本,所有服务均为 localhost。上边说了,deck 先需要通过连接本地 gate 连将请求转发到对应组件上。所以可以通过如下方式启动 deck
API_HOST=http://localhost:8084 yarn run start
先稍等一会,这里会先执行编译,启动完毕之后,我们就可以通过访问 http://localhost:9000 访问 Spinnaker deck 组件提供的 UI 页面了,页面简洁明了,非常好操作。
从上图可以看到,Spinnaker 主要的功能已经列出来了。而且这些功能是可以控制的,当扩展或停止了组件以后,UI 页面也会跟着展现出来,接入简单,可扩展性强。
4、演示 Spinnaker Pipeline
Spinnaker 的两个核心集群管理和部署管理,对于集群管理这块,它对国外常用的云平台集成的比较好,如 Google、AWS EC2、Microsoft Azure 等,因为手头没有相应的资源,这里暂时没法尝试,还要它支持 Kubernates,后期我将继续研究它如何跟 Kubernetes 结合完成集群管理,刚好最近在研究 Kubernetes,手头有搭建好的 k8s 集群。针对部署管理这块,Spinnaker 核心为三大块 Pipeline、Stage、Deployment Strategies,下边来详细演示一下 Spinnaker 提供的强大的 Pipeline 功能。
Spinnaker 平台,是按照 Project 项目分类,每个项目包含多个 Application 应用,每个应用里面包含多个 Pipelines ,每个 Pipeline 包含多个 Stage 阶段,在每个阶段中可以定义不同的 Deployment Strategies 部署策略。整体是按照这种方式来定义的,这样既可以很好的先按照项目分类,然后可以根据项目中应用再次细分,最后落实到每个应用的流程上,不同的流程配置不同的部署阶段和部署策略,从而使用户有一个很清晰的脉络来梳理并配置自己不同业务的部署流程线。
4.1 创建 Project、Application
首先创建一个项目 project_test,然后创建一个应用 app_test,并将应用 app_test 跟 project_test 项目关联起来。
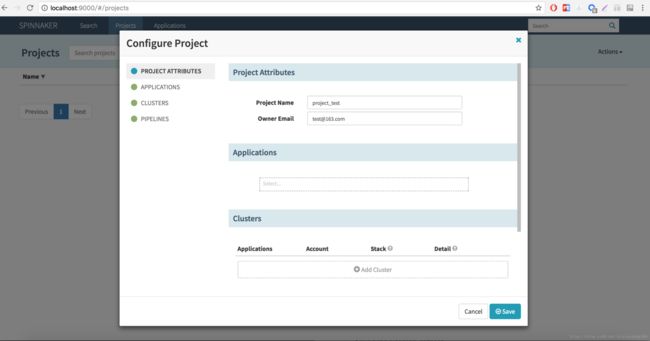
点击导航栏 “Projects” -> “Actions” -> “Create Project”,输入名称 project_test,Application 下拉选择项先不选,因为我们还没创建 Application,等创建完毕之后,在选择配置。
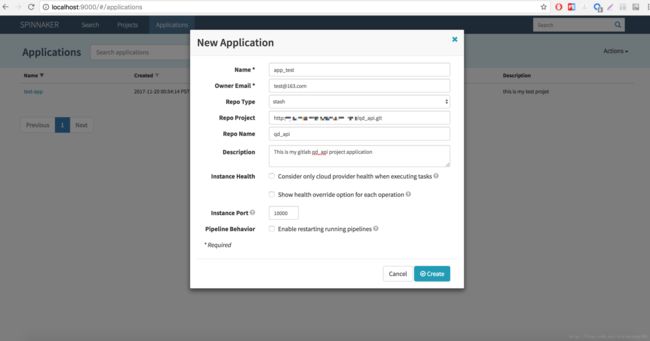
点击导航栏 “Applications” -> “Action” -> “Create Application”,输入名称 app_test,选择代码仓库类型,默认有三种:stash、github、bitbucket。这里我选择 stash,配置自己搭建的 GitLab 代码仓库即可,如果项目托管在 github 或 bitbucket 上,可对应选择。下边实例端口处填写端口号,根据提示信息,是要填写该应用实例端口号,最终可以通过 IP + Port 方式访问该实例,类似 Kubernetes 中的 Pod。
最后,将 project_test 跟 app_test 关联起来,点击导航栏 “Projects” -> “project_test” -> “Project Configuration” -> “Applications”,下拉列表中选择 app_test,点击 “Save” 保存即可。

4.2 创建 Pipeline
接下来创建 Pipeline,进入 app_test 详情页面,点击 “PIPELINES”,目前是没有任何信息的,点击 “+ Create”,弹框中选择类型为 Pipeline,输入流程名称,这里我命名为 first_pipeline。因为第一次创建,下边 “Copy From” 选择没出来,后续在创建时,我们也可以通过 “Copy From” 方式选择已存在的 Pipeline,非常方便就复制了一个一样配置的流程了。创建完毕后,就会出现详细配置 Pipeline State 的页面了。

4.3 配置 Configuration 项
刚开始这里只有一个 Configuration 选项,可以配置 Automated Triggers、Parameters、Notifications 等,这里说下 Automated Triggers 和 Parameters 这两个非常有用,我们可以将此视为 Pipeline 启动前的一些初始化配置,比如启动需要的参数配置、自动触发配置等,为后续各阶段提供必要的信息。
Automated Triggers 自动触发,它提供 7 种类型的触发方式:
- CRON:调度触发,可以执行一个 cron 调度任务来定时任务触发该流程。
- Git:当执行 Git push 操作时,触发该流程
- Jenkins:监听 Jenkins 的某一个 Job
- Travis:监听 Travis 的某一个 Job
- Pipeline:监听另一个 Pipeline 执行
- Pub/Sub:当接受到 pubsub 消息时触发
- Docker Registry:当 image 更新时触发。
基本能满足我们日常持续集成或交付的需求,当然每一个类型都需要配置相应的参数,比如 Cron 类型,需要配置执行频率、启动时间等。
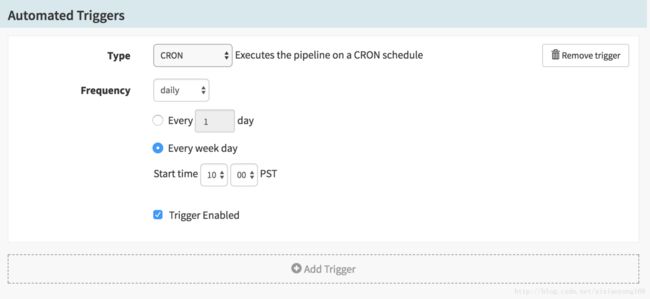


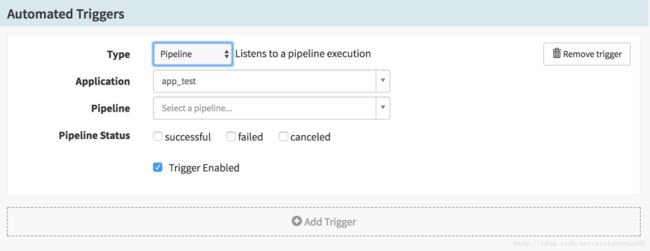
这里就不一一截图列举,可以亲自试验一下吧,每种类型的配置参数不一样,一些参数如果需要下拉选择的时候没有可选项,说明在启动 Spinnaker 的时候,配置文件中没有配置,也或者是配置的信息不完整或不正确导致。例如 Jenkins 类型,选择 Master 的时候,如果没有在 $HOME/.spinnaker/spinnaker-local.yml 文件中配置 Jenkins 信息的话,那么这里就肯定不会出现可选信息了。Docker Registry 中 Registry Name 选项也是同理。同时这些触发方式,可以组合使用的,添加多个 Automated Triggers 组合使用,效果杠杠的。
Parameters 参数,可以配置 Pipeline 参数,在流程启动是,会要求输入或选择对应的参数,并且在后续 Stage 中可以直接获取使用,这是非常有必要的,我们使用 jenkins Job 时,有构建参数选项配置,这里如果我们要触发对应的 Jenkins Job,那么可以把对应的必要参数设置在这里,后续 Stage 触发 Jenkins Job 时,构建参数赋值就可以直接通过表达式来获取了。

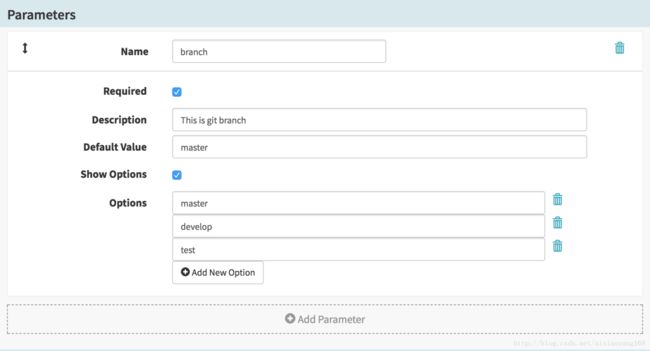
比如这里我设置 ci_version 和 branch 两个必填参数,并且 branch 带默认值,且可设置为可选参数。
4.3 配置各个 Stage 项
接下来,给 Pipeline 添加 Stage 了,实际应用中就需要我们结合自己的业务逻辑,合理添加 Stage,来达到期望的持续集成交付功能啦。这里我做一个简单的的功能演示,先来一个 Manual Judgment 类型 Stage,做人工判断选择,根据启动者选择的类型,在分别执行对应的 Check Preconditions 类型 Stage,做先决条件检查,这里得用到表达式判断(下边会说到表达式),最后为每条路径配置不同的类型的 Stage,这里一条使用 Wait 类型,等待固定秒后自动到下一个Stage 或结束,另一条选择 Webhook 类型,调用一个 API 接口,正常返回后结束流程。下边一步步介绍每个 Stage 配置,最终完成整个 Pipeline。
4.3.1 配置 Manual Judgment Stage
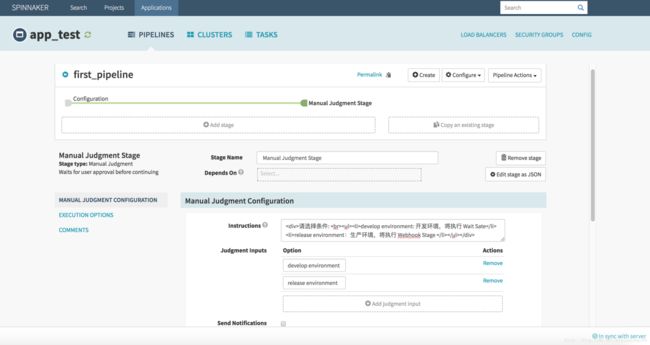
首先创建一个 Manual Judgment 类型的 Stage,来做人工判断选择,顾名思义就是执行 Pipeline 到该 Stage 的时候,会等待用户选择配置选项,Stage 才可以继续执行下去。鼠标点击 Configuration 选项,使其图标变绿(意味着对该选中项增加下一步 Stage,后续其他 Stage 增加 Stage 操作一样)。点击 “+ Add Stage”,下方区域 Type 选择 Manual Judgment,Name 名称我填写 “Manual Judgment Stage” 直观明了,Instructions 处填写该 Stage 的说明信息,实际应用中,一些必要的说明信息是很有必要的,其他人操作该流程时好做参考提示,这里还支持 HTML 代码,所以我再次输入提示信息如下:
>请选择条件: >
> >develop environment: 开发环境,将执行 Wait Sate</li> >release environment:生产环境,将执行 Webhook Stage </li> </ul> </div> 这样就算其他人执行这个示例流程,到这一步也知道该如何选择了吧!接下来 Judgment Inputs 判断项,这里我添加两判断项 develop environment 和 release environment,启动 Pipeline 执行到该 Stage 时,会等待我们选择判断项时,就会显示这两项。后续 Stage 也可以通过表达式获取到选择的值,来串联对应其他 Stage 很实用。填写完毕,点击 “Save Changes” 保存即可,如下图所示。
4.3.2 配置 Check Preconditions Stage
上边 Manual Judgment Stage 配置了两个 Judgment Inputs 判断项,接下来我们建两个 Check Preconditions Stage 来分别对这两种判断项做条件检测,条件检测成功,则执行对应的后续 Stage 流程。点击 “Manual Judgment Stage” 使其变绿,点击 “+ Add Stage”,Type 选择 Check Preconditions,Name 名称我填写 “Check Preconditions develop” 说明是针对条件为 develop environment 类型的验证,Preconditions 条件配置处点击 “+ Add Precondition”,弹框 Edit Preconditions 如下图。
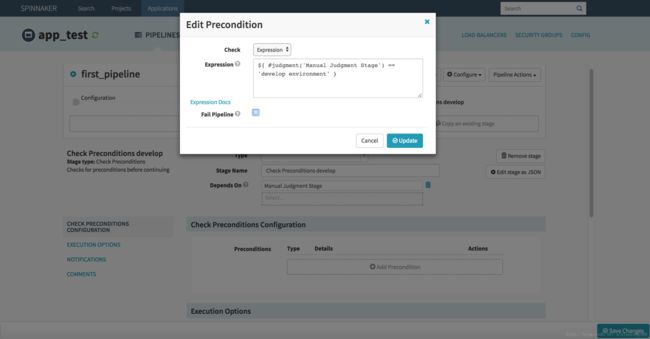
Check 处选择 Expression 表达式方式,然后在 Expression 文本域填写表达式 ${ #judgment('Manual Judgment Stage') == 'develop environment' },说明一下,这个表达式意思就是从名称为 “Manual Judgment Stage” 的 Judgment Stage 获取选择的值是否为 “develop environment”,如果条件匹配,则返回 true,继续执行当前 Stage 后续 Stage 流程,否则返回 False,执行前 Stage 的后续其他 Stage,如果未配置其他 Stage,则流程结束。Fail Pipeline 选项,如果勾选,则匹配不成功后,则直接结束流程。根据实际需要配置,这里我不勾选,因为该 Stage 判断不匹配的时候,我们还需要执行另一个判断 Stage 呢,可不能结束流程了。配置完毕,如下图。

接下来配置另一个 Check Preconditions Stage,这里就不用在一步步创建了,可以直接复制 “Check Preconditions develop” ,然后修改下名称和表达式即可,是不是很方便。点击 “Manual Judgment Stage” 使其变绿,点击 “+ Copy existing stage”,弹框选择 “Check Preconditions develop”,点击 “Copy Stage” 即可完成创建,弹框如下图。
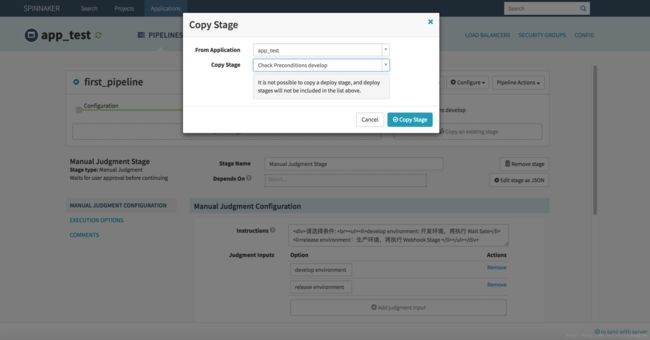
然后修改下 Name 为 “Check Preconditions release”,表达式处修改为 ${ #judgment('Manual Judgment Stage') == 'release environment' },保存即可。配置完毕,如下图。

4.3.3 配置 Wait Stage
配置好了 Check Preconditions Stage,接下来我们为 “Check Preconditions develop” stage 配置后续 Stage,使其在验证成功后,可以继续执行下去。点击 “Check Preconditions develop” 使其变绿,点击 “+ Add Stage”,Type 选择 Wait,Name 名称我填写 “Wait Stage”,这个 Stage 什么都不干,等待固定时间后结束流程使用。Wait Time 设置等待秒数,这里我设置为30s。配置完毕,如下图。
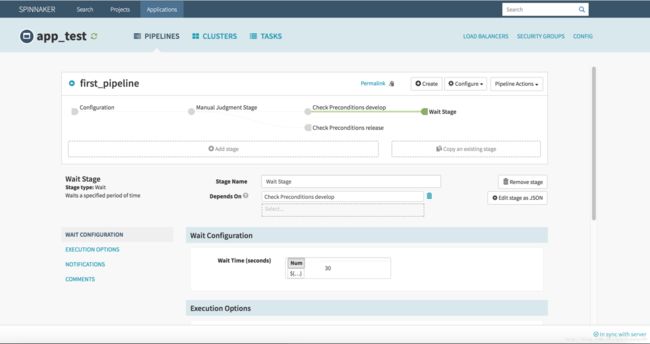
4.3.4 配置 Webhook Stage
接下来为另一个 “Check Preconditions release” Stage 配置后续 Stage,使其在验证成功后,可以继续下去。点击 “Check Preconditions release” 使其变绿,点击 “+ Add Stage”,Type 选择 Webhook,Webhook URL 为需要触发的 URL 地址,实际应用中用处很大,可以触发其他接口或者其他流程等等,而且可以配置解析返回值,进行状态判断,是否触发成功还是失败,来 Fail Pipeline 或其他操作,这里我简单一点,触发 http://www.baidu.com,Method 选择 Http 请求方式,支持 GET、HEAD、POST、PUT、DELETE 方式,选择了每一种方式之后,会出现对应该请求方式的其他参数配置,这里我选择 GET 方式,不需要配置其他参数。Wait for complation 等待完成配置,这下边有详细的解析返回值或返回状态的配置,也可以支持异步接口方式,比如提供一个获取状态 Staus 的 URL,然后配置对应信息,那么流程执行到此时,会请求异步接口并解析,直到返回状态匹配成功,才结束流程等,这里示例简单些,不配置了。配置完成后,如下图。

4.3.5 启动 Pipeline
好了,经过上边一系列的配置,一个简单的拥有 5 个 Stage 的 Pipeline 就完成了,接下来我们启动一下 first_pipeline 试试效果吧!回到 app_test 应用的 PIPELINES 页面,我们会看到我们所有配置的 Pipeline 列表,找到对应 first_pipeline 的 Pipeline,点击后边 “Start Manual Execution” 按钮,会弹出启动确认框,如果流程 Configuration 项配置了参数或者 Trigger,这里会一并弹出,在填入对应的值后,就可以启动流程了。例如该流程,我们配置了 Parameters 参数 ci_version 和 branch 参数,所以启动弹框如下图。
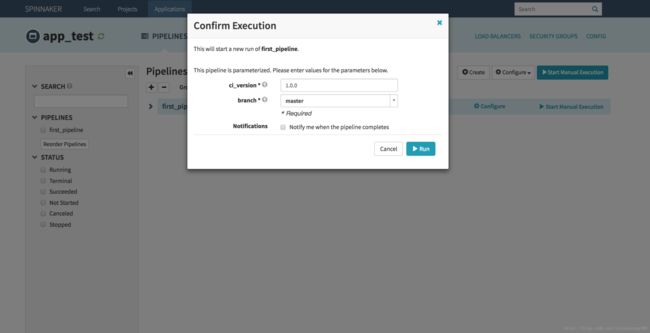
输入 ci_version 参数,以及选择 branch 参数后,点击 “RUN” 即可启动流程啦!启动后,我们会发现按照之前的设计,流程会卡在第一个 Stage,等待我们人工做判断,这里我们先选择 “develop environment” 选项,继续到下一个 Stage 吧。
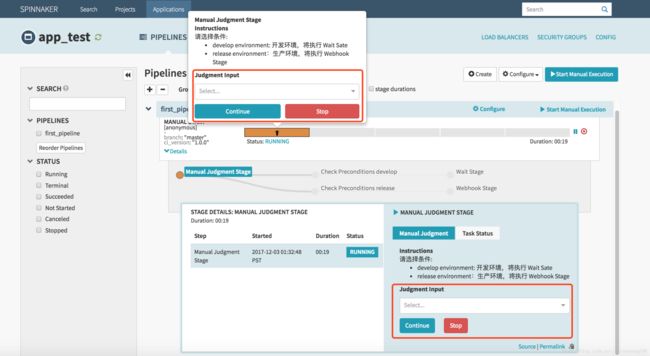
说明一下,这里可以鼠标悬停在第一个 Stage 上,就会显示配置的 Judgment Input 选项,以及 Instructions 说明,也可以点击 “Details” 下方显示详细信息,在此选择亦可以。
选择完毕后,流程会自动执行到下一个 Stage,流程会分别走到 “Check Preconditions develop” 和 “Check Preconditions release” Stage,然后做条件判断,还记得之前我们配置的 Expression 吧,这里就起到作用了,我们选择的是 “develop environment”, 那么验证 “Check Preconditions develop” 就会通过,直接继续到对应的下一个 Stage。验证 “Check Preconditions release” 失败,那么该节点状态就是 STOPPED 状态,不执行后续 Stage。
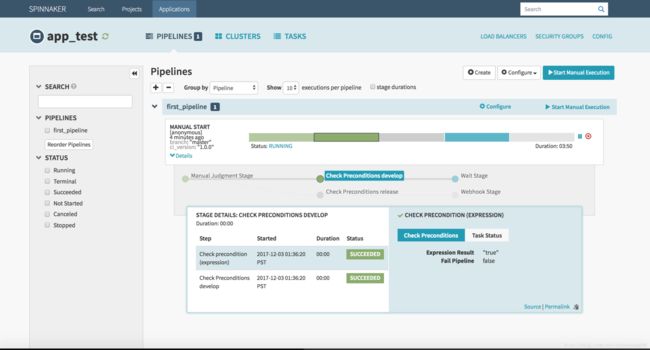
此时我们可以看到流程已经到了 Wait Stage 了,这一步什么都不干,等待 30s 流程结束。在等待过程中,也可以人为跳过等待时间,鼠标悬停该 Stage 上,会弹出跳过按钮。等待完毕后,该流程就成功结束啦!
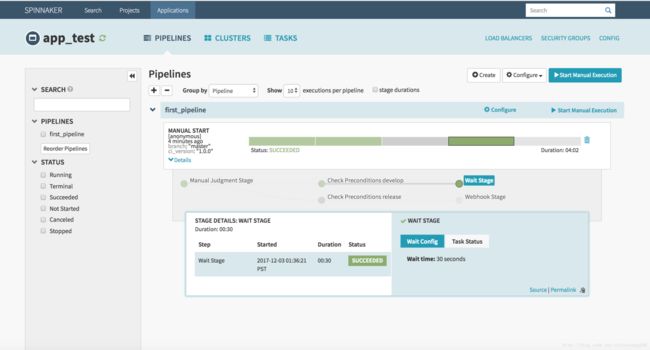
OK,到目前为止,Pipeline 的一条路线可以成功执行了,接下来验证一下,选择 “release environment” 选项后,流程的另一条路线执行情况吧!过程我就不在一一描述了,直接看结果吧!
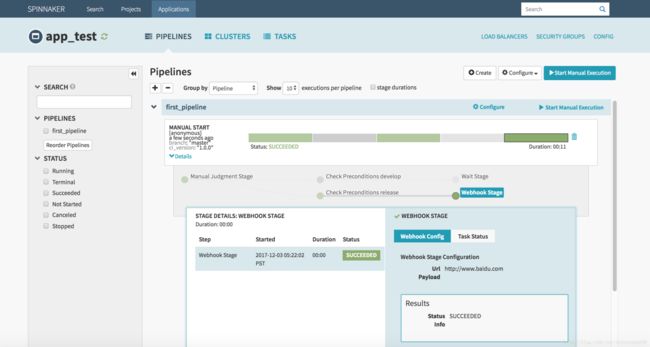
OK,同样可以正常运行。Spinnaker Pipeline 还有很多使用高级的用法,比如它可以触发 Script 脚本、执行 Job、触发其他 Pipeline 运行、部署项目到配置的云平台等等,基本能够满足我们日常业务需求哒!而且它还在持续更新中,相信以后能更方便更高效的接入更多平台。
5、演示 Spinnaker 集成 Jenkins
对于持续集成流程,我们使用的比较多的开源工具 Jenkins,Spinnaker 设计中就能够很好的支持第三方工具,通过 Igor 组件就能很好的支持 Jenkins 等工具。下边我们就演示一下 Spinnaker 如何集成 Jenkins 工具。
5.1 搭建并配置 Jenkins
因为 Spinnaker 本身启动时并没有直接启动一个 Jenkins 服务,所以需要我们自己启动一个 Jenkins 服务或 Jenkins 集群服务,然后将 Jenkins 信息配置到 Spinnaker 配置文件中,使其可以关联到对应 Jenkins,然后就可以在 Spinnaker 中尽情使用 Jenkins 服务啦!
Jenkins 服务搭建及配置,这里我就不在详细说了,具体可以参考之前文章 初试Jenkins2.0 Pipeline持续集成 前半部分 Jenkins 安装这块,讲的很详细。这里我用 Docker 方式在本地快速搭建一个 Jenkins 服务。
docker run -d -p 9090:8080 -p 50000:50000 -v /Users/wanyang3/jenkins_home:/var/jenkins_home jenkins
此时 Jenkins 服务就运行在本地 http://127.0.0.1:9090 上了,我们配置管理员账户 admin,密码 admin 为了后边配置 Spinnaker 使用。接下来我们创建一个普通的测试 Job,名称为 maven_test,参数化构建过程处我们配置一个 ci_version 参数,目的很明显,就是为了接收上边 Pipeline 启动参数中的 ci_version 值,让他们能够串联起来。
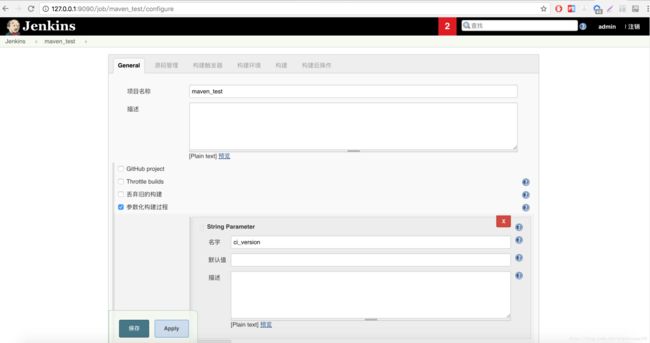
然后,在源码管理处,配置我们的代码仓库地址及分支 (这里分支也可以配置成参数,从 Spinnaker 启动参数中获取哈,这里就不演示了)。最后,我们在配置一下构建,执行一个 shell,简单打印一下获取的参数,最后在执行一个 mvn clean 命令。
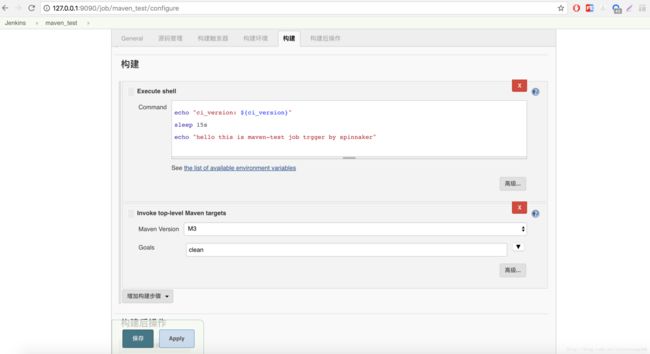
配置完成后,接下来就需要配置 Spinnaker config 文件,开启对 Jenkins 的支持以及配置 Jenkins 信息。
5.2 配置 Spinnaker config 集成 Jenkins
上边提到,Spinnaker 的配置文件为 $HOME/.spinnaker/spinnaker-local.yml,那么我们需要做一些修改。
$ vim $HOME/.spinnaker/spinnaker-local.yml
... igor: enabled: true # 这里默认为 false,修改为 true host: ${services.default.host} port: 8088 baseUrl: ${services.default.protocol}://${services.igor.host}:${services.igor.port} ... jenkins: enabled: ${services.igor.enabled:false} defaultMaster: name: Jenkins baseUrl: http://localhost:9090 # 配置上边启动的 Jenkins 服务地址 username: admin # 管理员用户名 password: admin # 管理员密码或管理员对应的 API Token ...
配置完成后,在 Run 一下 Spinnaker 服务,默认 Spinnaker 会检测各组件如果已经启动的话,将不再重启。当然也可以先 Stop,然后在 Run 所有组件服务也可以。
$ cd /Users/wanyang3/spinnaker/build
$ ../spinnaker/dev/stop_dev.sh [service] $ ../spinnaker/dev/run_dev.sh [service]
注意:重启服务后,若某些组件未启动,需要像上边一样,手动启动组件。上边我们设置了 Igor 为 true,那么会自动启动起来,一定要保证 igor 能正常启动,否则没法集成 Jenkins。
5.3 配置 Jenkins Stage
我们继续使用 first_pipeline 这个示例 Pipeline,简单的在 Wait Stage 后边追加一个 Jenkins Stage,让其执行上边配置的 Jenkins 名称为 maven_test 的 Job,并且将 参数 ci_version 传递过去。
点击 “Wait Stage” 使其变绿,点击 “+ Add Stage”,Type 选择 Jenkins,Master 处选择刚配置文件中定义的 name: Jenkins Jenkins,这里也可以配置多个 Master,具体可以参考文档。Job 处选择 maven_test,默认会拉取该 Jenkins 下所有 Job。 Job Parameters 这里就需要传递 ci_version 参数了,实际应用中,我们是要动态获取启动参数中的参数配置,所以这里可以通过表达式 ${ parameters['ci_version']} 来获取参数。Wait for results 默认勾选,等待 Jenkins 的执行结果,Jenkins 执行完毕,才结束流程。配置完成后,如下图。
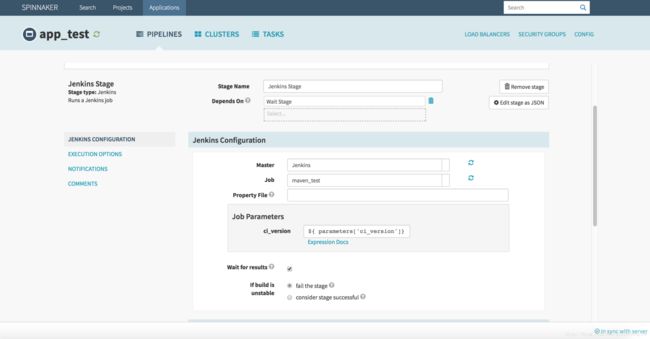
OK,配置完成。最后我们在来启动一下 first_pipeline,输入 ci_version 参数,选择 branch 参数启动,选择 “develop environment” 继续,执行完 “Check Preconditions develop” Stage,继续到 “Wait Stage” 等待 30s 后,执行 “Jenkins Stage”,但是执行失败了。。。 这是为啥? 看返回的报错信息是 403 No valid crumb was included in the request,原因是 Jenkins 默认开启防止跨站点请求伪造导致的,解决方案就是去 Jenkins —> 系统管理 —> 防止跨站点请求伪造处,去掉勾选即可。再次运行,就可以成功运行啦!
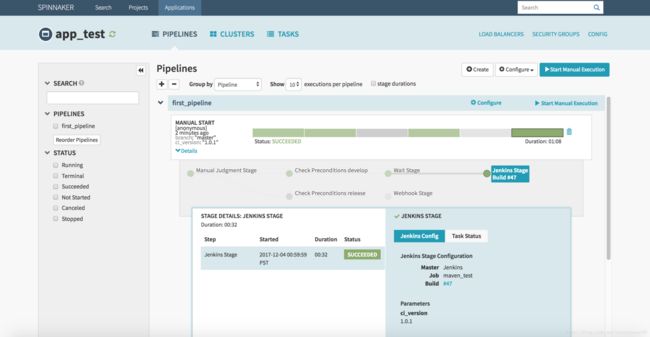
点击详情中 “Build #47” 链接,查看此次 Build Log,可以看到正常启动并传递参数。
...
[maven_test] $ /bin/sh -xe /tmp/hudson9078124639399895924.sh + echo ci_version: 1.0.1 ci_version: 1.0.1 + sleep 15s + echo hello this is maven-test job trgger by spinnaker hello this is maven-test job trgger by spinnaker [maven_test] $ /var/jenkins_home/tools/.repository/bin/mvn clean [INFO] Scanning for projects... [INFO] [INFO] ------------------------------------------------------------------------ [INFO] Building qd_api 0.0.1-SNAPSHOT [INFO] ------------------------------------------------------------------------ [INFO] [INFO] --- maven-clean-plugin:2.5:clean (default-clean) @ qd_api --- [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 0.809 s [INFO] Finished at: 2017-12-04T09:00:22+00:00 [INFO] Final Memory: 5M/59M [INFO] ------