第二十六节决策树系列之Cart回归树及其参数(5)
上一节我们讲了不同的决策树对应的计算纯度的计算方法,其实都是针对分类来说,本节的话我们讲解回归树的部分。
目录
1-Cart回归树的概念
1-代码详解
1-Cart回归树的概念
对于回归树来说,之前咱们讲的三个决策树(ID3,C4.5和Cart树)里只有CART树具有回归上的意义,其实它无非就是把分裂条件给变了变,把叶子节点的表达给变了变。剩下的全部过程都是和分类树没有区别的。它的分裂条件变成什么了呢?分裂条件仍然是通过遍历维度搜索。当你搜索完了,尝试分裂,你要评估这次分裂是好还是不好的时候?不能再使用Gini系数和信息熵了。因为每一个样本跟每一个样本之间的结果都不一样。你想你原来是怎么算信息熵和Gini系数的?先看看我这叶子连接节点有几类数据,把它们分别统计一下,算出一个数。而回归问题,它的y lable有一样的吗?应该说没有一样的。这种情况下肯定不能用刚才那个Gini系数和熵来做了。那用什么呢,用mse来统计。
举例比如下图:
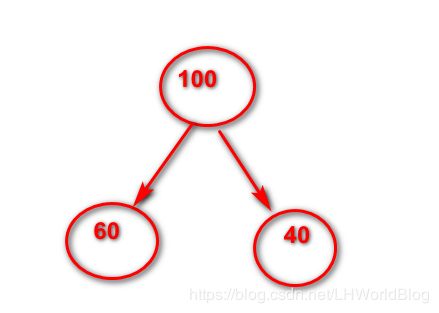
根节点里有100个数据我尝试分裂。分裂出两支来, 一分支是有60个数据。另一支有40个数据。此时怎么评估这次的分裂效果呢?先计算这60条数据的y的均值。然后用这60条数据的每一个真实的y减去y的均值加平方求和除以60。就得出了这个叶子节点里边的平均mse,能够理解吧?那么右边一样,先是计算出40条y平均。用每一条y减去这个y的平均加平方求和,最后乘以各自的权重,还是要乘以一个1/60和1/40的。那么你多次尝试分裂是不是就得到 或者你去想它会把y比较相近的一些节点分到同一个节点里边去,对不对? 所以这就是回归树的计算流程。评估每次分裂效果的指标我们叫它mse,它实际上是方差。就是一个集合里边的每一个数减去均值平方通通加起来再除以数目本身,假如有十个数,求这10个数的方差,首先要求出它的均值μ,用每一个数减去μ的差的平方,再相加,除一个1/10。这就是这个集合的方差。方差是一个统计学的指标,它描述的是什么?是这一组数据的离散程度。你方差越大代表这个数据里边天差地别,对吗?天南海北。方差越小,代表这一组数据非常紧密。彼此之间都差不了多少。那我们既然要做回归问题,我最终希望落到这个叶子节点里边的lable越近越好还是越远越好?那肯定是越近越好对吧。我分着分着,越分越近,越分越近,最后得到的叶子结点都是最近的那些落到同一个叶子节点。那未来预测的时候怎么办?它落到某一个叶子节点了。这个叶子节点是不是不知道应该给它输出多少值啊?它会输出多少呢?平均值。能够理解吗?也就是说这个东西回归分析做出来之后,它是锯齿状的。能够理解吗?锯齿状的一个回归分析。例如下图:

就是因为x都落在同一个叶子节点里边输出一个均值。而不象参数型模型了,按理来说,你只要变一点儿,那么y的结果多多少少都会变一点儿。而这个你的x只要变了一点儿就会影响到你最终落到那一个叶子节点。这样你给的输出是不是就都是一样的了。所以对于回归树来说还是那四个问题。
一、它分几支,我们刚才看了这个数分两支,对不对?
二、它怎么判断分裂条件。从原来的Gini系数变成了方差。或者说变成了mse
三、它什么时候停止?还是那些预剪枝的过程。我们后面会讲。
四、叶子节点怎么表达。从原来的投票算概率变成了算平均值。就是这么简单。
1-代码详解
我们来看下决策树的应用代码:
解释下上面代码:
1、from sklearn.datasets import load_iris iris = load_iris(),iris['data'] ['target']。这个iris里边就包含了iris(data)和(target),这里边有两种调用它的方式。一种你可以写iris.Data,一种还有这种字典的方式,索引data,实际上sklearn把我们这两种风格的ATI都保留下来了。
2、我们在这儿引入了一个工具叫pandas,我们之前简单的讲了讲numpy就是一个简单的玩数组的东西,而pandas就是对numpy简单的进行了一个加强。原来的numpy是一个数组,pandas给每一列数组起了一个名字。比如说data是数组。你想调用其中一个元素,用numoy来去你就必须写data[0,0],而pandas分别给行和列起了索引号。可以使用名称来更灵活的调用它,这是其一,也是最根本的区别。其次,pandas里边集成了很多方面的数据操作的东西。这两个就是一个简单的tool就是两个简单的工具。你学Excel有多难学它就有多难能明所以它不是很复杂的东西。pandas里边有一个对象叫dataframe实际上是叫数据帧,数据帧就是一个带名称的二维数组。二维数组只有索引号。而dataframe加了一个名称。data = pd.DataFrame(iris.data),我们把这个iris里边儿的data拿出来,它是一个numpy数组。二维数组。data扔到dataframe中返回的一个什么东西呢?返回一个panda里边叫df的对象。那df对象有两个属性。一个叫columns,是指它这个列的名称。一个叫index是指行的名称。
3、然后我们通过train_test_split 这个工具来划分出验证集和测试集。然后我们新建一个对象叫做DecisionTreeClassifier,然后我们可以看到它实际上有两个类是决策树的。DecisionTreeClassifier,DecisionTreeRegressor。分别是什么意思呢?不用我说大家是不是已经明白了?一个是用来做分类的,一个是用来做回归的。
4、我们看下DecisionTreeClassifier的超参数有哪些呢?
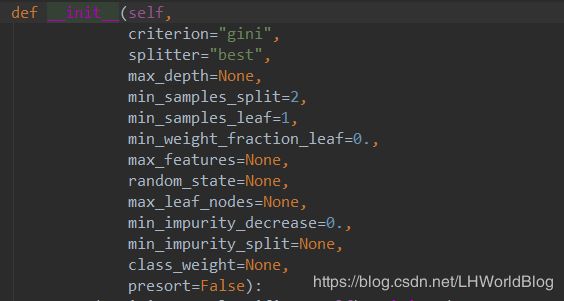
criterion,是拿什么东西来评价的标准。可以取值gini,Gini越高它越不纯。也可以取值entropy评估的是信息增益。
splitter,取值Best是找到最好的那个分裂。取值random是找到最好的随机分裂,也就是说它随机多少次之后,把随机出来过的最好的结果给你。相当于一个加速运算的东西。相当于找到了一个随机出来的最优解,有点像随机梯度的意思。
max-depth,树的最大深度。这个可以说是我们最常用的预剪枝的操作手段。我们很多时候不去设置那些细枝末节的规则。仅仅设一下树的最大深度,就是你分裂多少层就不要再继续分裂了。我管你分的好分不好,你都不要再分裂了。
min_samples_split ,除了根结点和叶子结点其他中间的那些节点分裂一个所需要的最小的样本量默认是2。意思是这些节点要分裂所需的最小样本数是2。
min_samples_leaf,叶节点最小样本数。
min_weight_fraction_leaf,就是你这个叶子结点占总的比例有多少能成为叶子结点,这个比较有意思。
max_features,就是说在你寻找最佳切割点的时候要不要考虑所有的维度咱们本来是不是遍历所有的维度?现在改成随机取几个维度遍历。不取全了,能明白我的意思吗?因为它要分裂很多层,虽然第一层没有考虑到这个维度。第二层的时候有可能就考虑到了,如果是default=none那么如果是none什么意思啊?全部的维度都要进来去考虑如果你是int那么是什么意思呢?你传一个整形进来。就是每次在寻找切割的时候就随机的找到。你比如说乘以六。那么它就随机找的六个维度去考虑,寻找最佳切割点。那这样就肯定会变的不准了,但会变得更快了。然后如果你传一个浮点数过来那么实际上是百分比。你比如说传一个0.6。就是你每一次分裂的时候,就随机挑选出60%的维度出来,来寻找最佳切割点,如果是auto,是开个根号。比如说你有100个维度。我就给你整十个纬度。能够理解吗?sqrt也是开根号。Log2是取个log2然后再取,默认的通常是就选none,有多少我就考虑多少。
max_leaf_nodes ,最多的叶子节点也是,如果叶子节点够多了,你就不用再分裂了。
min_impurity_decrease ,我们的目的是gini系数必须得变小,我才让你分裂。你原来的分裂越大,当传入一个float进来,必须要gini系数必须要缩小多少才能进行此次分裂。
class-weigh,我们可以看到所有的函数,分类器也好,回归器也好,都会有这个参数。class-weight代表什么呢?代表每类样本,你到底有多么看重它?它的目的是将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)。该参数在处理非平衡的训练数据(某些类的训练样本数很少)时,可以使得损失函数对样本数不足的数据更加关注。
5、我们创造一个这个DecisionTreeClassifier,然后输出acc score,然后输出我们再验证集上的准确度,达到了97%,能看到吗?比之前咱们的逻辑回归,训练及效果要好不少。
6、for d in depth,以及下面的代码大致意思是,我把树的深度从一到15遍历了一遍。然后分别画出这15棵树到底错误率是多少。训练15个模型,我们可以看,随着树的深度增加,在4的时候验证集错误率最低,但是后来随着深度的增加,反倒又上升了。这就有一点点过拟合的意思,但在咱们这个数据集里很难形成过拟合。因为总共才150条数据。但是这个东西你可以看到,不是说树越深在验证集上效果就表现得越好。
下一节里面我们会讲解决策树的另一个问题即什么时候停止的问题。