介绍
本来无意写FCN的,而是想耐心将R-CNN系列的文章梳理完全。只是在研究已分别在目标识别和实例分割领域成为state-of-art模型的R-FCN与Mask-RCNN网络时,发现它们都借鉴了这篇FCN的idea。于是想在这里先对它作一分析、介绍。
FCN产生于2015年,当时随着Alexnet在Imagenet分类领域的巨大成功,Vgg, Googlenet等更复杂的CNN网络相继提出,CNN网络在图片分类领域的发展也是如火如荼,高歌猛进。此时R-CNN网络的作者首先试着将CNN用于目标识别领域当中并取得了较大的成功,于是机敏的各个计算机视觉领域研究人员都将目光转向了CNN。他们试图将CNN与自己的研究领域相结合,从而生出不一样的花火来。FCN的作者正是其中之一,他将在分类、目标识别领域混得很好的CNN网络稍作修改用来进行semantic segmentation,结果自然很好,于是有了这样一篇先驱性的文章。
它最终发在CVPR上面,由Berkley的学者来完成。是一篇在Semantic segmentation领域有着开山鼻祖地位的文章。
语义分割(Semantci segmentation)
与目标识别(object detection)孜孜于找到图片中的物体位置,并使用框框将其标出不同,Semantic segmentation致力于在更细的粒度上对图片中的物体或有意义区域进行分割。它不像object detection那样只是用框将所识别的物体标识出来,而是在图像像素级别上对包含物体进行区分,从而实现更好的物体轮廓描述与分割。它与Object detection之间的不同可见于以下图中。

FCN的基本网络结构
FCN主要用于解决semantic segmentation(即检测出图片上的每个pixel类别)问题。如下图是它的基本结构轮廓及网络输入、输出。
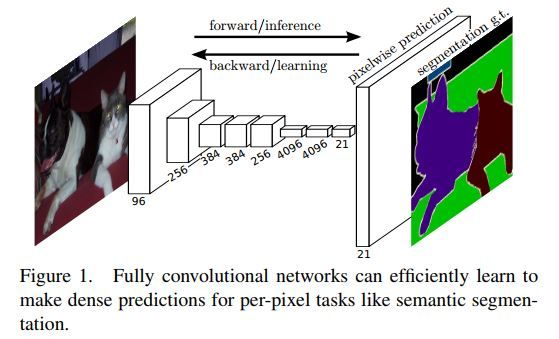
FCN相对用于图片分类领域的经典网络如Alexnet, VGG, Googlenet等只是在最后几层稍作了修改,替换,以让它们适用在了semantic segmentation上面。下图中可看出FCN相当于分类CNN网络在模型后端所有的变化。
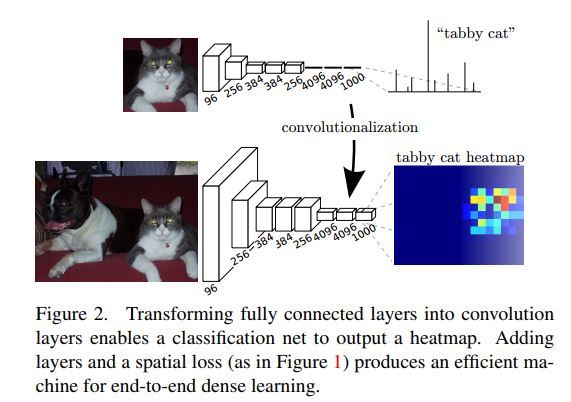
从上图中,我们可以看出在layer level上而言,FCN与分类CNN网络之间的主要不同在于模型的前端输入与后端输出处理上面。首先前端输入,一般CNN分类网络选择使用固定大小的image patch来作为输入,这个patch往往是从原图当中剪切出来的;而FCN网络则使用整张原图来作为输入。然后在模型的后端,CNN分类网络会使用FC层对最后的CNN层生成出的feature map进行处理,从而丢掉由前端CNN各层处理所一直暗暗保存着的图片上敏感区域的位置信息,进而只抽象表达出它的类别信息来,以交由后面的softmax等层来最终预测出它的类别概率分布;FCN则不同,它丢掉了CNN分类网络后端的FC层,进而保留了图片上的区域位置信息,又在其后加上了几层CNN来进一步分析处理,整合主干网络输出特征,最终它生成出有着C+1(C为目标类别数,+1是为了考虑进去图片背景)个channels的heat map(本质上可以理解为是cnn所产生的feature map)来。
由于FCN网络前端CNN处理过程中会不断选择用Pool来整合、下采样特征,从而扩大后来层次的receptive fields,因此最终我们生成出来的heat map其大小肯定要小于原输入图片大小。实际上它们之间满足s倍的关系,s为图片中下采样层次stride的乘积即累积下采样步长。
而我们Semantic segmentation的目标是要预测输入图片每个像素点的可能类别。因此我们要想办法将输出的heat map与input raw image关联起来。简单的话可以直接使用线性二次插值来解决。FCN中通过在网络最后加入步长为s的deconvolution层来使得最终的网络输出heat map具有与输入原图一样的大小。这可以在文章后面的模型代码解析中看得出来。
FCN网络结构增强
通常CNN网络随着层次的加深,会不断对处理的特征进行抽象、概括描述。这样在较浅的层次一般会有着较细粒度的图片特征像目标边缘等,其较深的层次则渐渐失掉了细特征而只抽象包含反映目标基本概念的特征。有时候像semantic segmentation这种细粒度识别目标轮廓的问题如果只选用最深的CNN feature maps的话往往会过于粗线条而不能细致。因此作者试着考虑将不同层次特征融合,然后共同用于生成最终的heat map。此过程可见于下图。

FCN训练
不必多言,FCN训练当中自然也使用了迁移学习即使用分类网络已有的权重初始化整个模型的前端CNN处理网络,然后再使用特定的VOC等dataset对后端新采用的诸层进行finetune。
FCN网络评价标准
下图所示这些评价标准适用于所有的semantic segmentation问题。

代码示例
数据输入层如下,可见我们输入的数据也是一个pair,分别为待处理的数据及一个标注着图片上各像素类别信息的label map。这样的数据集显然难标注的多,自然也贵的多。没办法搞AI现在自然是要花钱的,买机器,搞数据集都是花钱的大头。
def load_image(self, idx):
"""
Load input image and preprocess for Caffe:
- cast to float
- switch channels RGB -> BGR
- subtract mean
- transpose to channel x height x width order
"""
im = Image.open('{}/JPEGImages/{}.jpg'.format(self.voc_dir, idx))
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
in_ -= self.mean
in_ = in_.transpose((2,0,1))
return in_
def load_label(self, idx):
"""
Load label image as 1 x height x width integer array of label indices.
The leading singleton dimension is required by the loss.
"""
im = Image.open('{}/SegmentationClass/{}.png'.format(self.voc_dir, idx))
label = np.array(im, dtype=np.uint8)
label = label[np.newaxis, ...]
return label
FCN网络的后端几层描述,我们能看出它相对于之前的分类CNN,去掉了最后面的FC层,然后加了个Conv层来输出21个channels的feature maps。(21是因为VOC共有21类)。然后再有一个stride为32的deconvolution层来进行上采样以使得最终生成的heat map能够与输入图片一一对应,大小一致。这后面的crop层,是因为我们在前端input data预处理时对它有padding操作。关于为何作padding,作者的github上有很好的解释。特录在最后面。
layer {
name: "score_fr"
type: "Convolution"
bottom: "fc7"
top: "score_fr"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 21
pad: 0
kernel_size: 1
}
}
layer {
name: "upscore"
type: "Deconvolution"
bottom: "score_fr"
top: "upscore"
param {
lr_mult: 0
}
convolution_param {
num_output: 21
bias_term: false
kernel_size: 64
stride: 32
}
}
layer {
name: "score"
type: "Crop"
bottom: "upscore"
bottom: "data"
top: "score"
crop_param {
axis: 2
offset: 19
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "score"
bottom: "label"
top: "loss"
loss_param {
ignore_label: 255
normalize: false
}
}
为何对输入要做padding?
Why pad the input?: The 100 pixel input padding guarantees that the network output can be aligned to the input for any input size in the given datasets, for instance PASCAL VOC. The alignment is handled automatically by net specification and the crop layer. It is possible, though less convenient, to calculate the exact offsets necessary and do away with this amount of padding.
参考文献
- Fully Convolutional Networks for Semantic Segmentation, 2015
- https://github.com/shelhamer/fcn.berkeleyvision.org
- Adversarial Examples for Semantic Segmentation and Object Detection, 2017