姓名:纪雅丽17101223419
转载自:http://mp.weixin.qq.com/s/PQ4i4tozqNB2wCXaiubz3w,有删节。
【嵌牛导读】:“从零开始,开发一款聊天机器人”AI对于社会真正的贡献并不是某一个模型算法多么炫酷高深,而是它可以为尽量多的人所利用,来做实事。
【嵌牛鼻子】:聊天机器人 NLP 语言理解模型 LR seq2seq
【嵌牛提问】:聊天机器人到底是怎么实现的呢?它的原理都是什么?
【嵌牛正文】:
一、聊天机器人的语言理解模块
聊天机器人的语言理解有很多种实现技术。在此,介绍一下solution:对于用户输入问题进行意图识别和实体提取。
意图识别和语言提取可以通过基于规则(rule-based))和基于模型(model-based)两种方式来实现。
最简单直接的是基于规则的方法:用关键字/正则表达式匹配的方式,来发现自然语言中的意图和实体。
其实,如果大家真的去开发一个以使用为目的,垂直领域内回答有限问题的Bot。就会发现,最straight forward的方法,就是去设置大量规则,进行rule-based理解。不仅准确率高,而且特别好修改,哪里有错,直接改rule就好了。还不需要准备训练语料,和model-based比起来,真是不知道好用到哪里去了。
可是,毕竟基于规则的方法缺点也很明显:缺乏泛化能力。而且,从前次chat听众提问和评论来看,大家最感兴趣的,偏偏是model-based LU。
确实,model-based LU应用到了Machine Learning的技术,离炫酷的AI最近。虽然在实际当中,用最小代价解决必要问题的方法就是最好的方法,选技术应该选对的,而不是“贵”的。但是,既然大家就喜欢“贵“的,那我们就专门来讲讲它。
在讲具体算法模型之前,我们先来看看NLP。
二、NLP是怎么回事
我们今天要讲的语言理解,是理解人类的自然语言(Natural Language)。这部分工作可以算作自然语言处理(Natural Language Process/NLP)的一部分。
当然,现在也有人把自然语言理解(NLU)单独提出来,当作和NLP并列的另一个领域。不过我们没必要玩这种文字游戏。NLU也罢,NLP也好,都要让计算机“听懂”人类正常讲话时使用的语言,而不是几个英文关键字加一堆参数的格式化的指令。
我们人类是怎样理解语言呢?
举个例子,我说“苹果”这个词,你会想到什么?一种酸酸甜甜红红绿绿的球状水果,对吧。想起来的时候,或许脑子里会出现苹果的图像,或者会回味起它香甜的味道,或者想起和这种水果有关的什么事情。
我们人类理解语言的时候,是把一个抽象的词语和一个具体的事物关联起来,这个事物是我们头脑中知识库图谱里的一个节点,和周围若干节点直接相连,和更多节点间接相连……
计算机又如何理解语言呢?
我们用键盘敲出“苹果”两个字的时候,计算机并不会幻视出一个水果,也不会像人那样“意识到”这个单词的含义。
无论通过输出设备显示成什么样子,计算机所真正能够处理的,是各种各样的数值。要想让计算机理解人类的语言,就需要把人类的语言转化成它可以用来读取、存储、计算的数值形式。
当若干自然语言被转换为数值之后,计算机通过在这些数值之上的一系列运算来确定它们之间的关系,再根据一个全集之中个体之间的相互关系,来确定某个个体在整体(全集)中的位置。
这么说有点绕,还是回到例子上。很可能,我说“苹果”的时候,有些人首先想到的不是苹果,而是乔帮主创立的科技公司。
但是,我继续说:“苹果一定要生吃,蒸熟了再吃就不脆了。”——在这句话里,“苹果”一词确定无疑指的是水果,而不是公司。因为在我们的知识库里,都知道水果可以吃,但是公司不能吃。出现在同一句话中的 “吃”对“苹果”起到了限定作用——这是人类的理解。
对于计算机,当若干包含“苹果”一词的文档被输入进去的时候,“苹果”被转化为一个数值Va。经过计算,这个数值和对应“吃”的数值Ve产生了某种直接的关联,而同时和Ve产生关联的还有若干数值,它们对应的概念可能是“香蕉”(Vb)、“菠萝”(Vp)、“猕猴桃”(Vc)……那么据此,计算机就会发现Va,Vb,Vp,Vc之间的某些关联(怎么利用这些关联,就要看具体的处理需求了)。
总结一下,计算机处理自然语言必经由两个步骤:i)数值化和ii)计算。
NOTE 1: 说到数值,大家可能本能的想到int, double, float……但实际上,如果将一个语言要素对应成一个标量的话,太容易出现两个原本相差甚远的概念经过简单运算相等的情况。假设“苹果“被转化为2,而”香蕉“被转化为4,难道说两个苹果等于一个香蕉吗?
因此,一般在处理时会将自然语言转化成n维向量。只要转化方式合理,规避向量之间因为简单运算而引起歧义的情况还是比较容易的。
NOTE2:具体的转化方法有很多种(后面章节会详细介绍具体方法)。不过,既然要把“字”转化为“数”,有一个天然的数值就很容易被选中,这个数值就是:这个字的概率(在当前文档中,或者在所有文档中)。
由概率,我们又可以引出一个概念:信息熵。这个概念大家可以自行百度,先看一下它的计算公式:
其中P(xi)就是xi的概率。可见,只要已知集合中每个元素的概率,就可以求取集合的信息熵。
三、语言理解模型
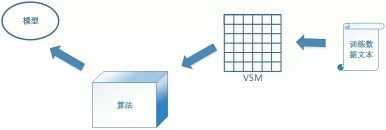
模型、算法、VSM
本文所说的LU 包括两大功能:意图识别和实体提取。
意图识别是一个典型的分类问题,而实体抽取则是一个Sequence-to-Sequence判别问题。因此我们需要构建一个分类模型和一个seq2seq判别模型。
我们先来说说模型是什么。
一个已经训练好的模型可以被理解成一个公式 y=f(x),我们把数据(对应其中的x)输入进去,得到输出结果(对应其中的y)。这个输出结果可能是一个数值,也可能是一个标签,它会告诉我们一些事情。
比如,我们把用户说的一句话输入识别用户意图的分类模型。模型经过 一番运算,吐出一个标签,这个标签,就是这句话的意图(intent)。
把这句话再输入到实体提取模型里面,模型会吐出一个List,其中每一个element都是一个实体,这个实体的信息包含:i)实体名:输入句子中一个的片段;ii)实体位置:该片段在输入句子中的位置和长度;iii)实体类型:该片段所对应的实体属于什么类型。
模型是怎么得到的?
模型是基于数据,经由训练得到的。训练又是怎么回事?
当我们把模型当做y=f(x)时,x就是其中的自变量,y是因变量。从x计算出y要看f(x)是一个具体什么样的公式,这个公式中还有哪些参数,这些参数的值都是什么。训练的过程就是得到具体的某个f(x),和其中各个参数的具体取值的过程。
在开始训练的时候,我们所有的是x的一些样本数据,这些样本本身即有自变量(特征)也有因变量(预期结果)。对应于y=f(x)中的x和y取值实例。这个时候,因为已经选定了模型类型,我们已经知道了f(x)的形制,比如是一个线性模型y=f(x)=ax^2+bx+c,但却不知道里面的参数a, b, c的值。
训练,就是要将已有样本经过依据某种章法的运算,得到那些参数的值,由此得到一个通用的f(x)。这些运算的章法,就叫做:算法。
说到算法,就涉及到了机器学习的内容,经过几十年的研究,已经有很多现成的算法可以用于获得不同类型的模型。关于生成分类模型和seq2seq判别模型的算法,我们下面有专门章节讨论。
要得到模型,算法固然重要,但往往更重要的是数据。
用于训练模型的数据有个专名的名称称呼它们:训练数据。训练数据的集合叫做训练集。
分类模型和seq2seq判别模型的训练都属于有监督学习,因此,所有的训练数据都是标注数据。
因此,在进入训练阶段前必须要经过一个步骤:人工标注。这部分已经在之前chat中讲过,不赘述。
标注的过程繁琐且工作量颇大。然而只要进行有监督学习,就无法跳过这一步。偏偏大量在实践中证明确实有效的模型都是有监督学习模型。因此,如果大家真的在工作中应用机器学习,标注就是无法逾越的脏活累活,是必经的pain。
这里需要提醒大家的是:人工标注的过程看似简单,但实际上,标注策略和质量对最终生成模型的质量有直接影响。而往往能够决定模型质量的不是高深的算法和精密的模型,而是高质量的标注数据。因此,对标注,切莫小歔。
此处有一点和之前NLP一节呼应,就是:任何算法的处理对象都是数值。
而我们要对其进行分类和识别的对象却是自然语言文本。因此需要一个步骤,把原始文字形式的训练数据转化为数值形式。
为了做到这一点,我们需要构建一个向量空间模型(Vector Space Model/VSM)。VSM负责将一个个自然语言文档转化为一个个向量。下面也会专门章节讲VSM的构建。
训练数据经过VSM转换之后,我们把这些转换成的向量输入给分类或识别算法,进入正式的训练过程。训练的输出结果,就是模型。
如何判别模型的优劣
通过训练得到模型后,我们需要用模型来对用户不断输入的语句进行预测(也就是把用户语句输入到模型中让模型吐出一个结果)。
预测肯定能出结果,至于这个预测结果是否是你想要的,就不一定了。一般来说,没有任何模型能百分百保证尽如人意,但我们总是追求尽量好。
什么样的模型算好呢?当然需要测试。当我们训练出了一个模型以后,为了确定它的质量,需要用一些知道预期预测结果的数据来对其进行测试。这些用于测试的数据的集合,叫做测试集。
一般而言,除了训练集和测试集,还会需要验证集:
训练集(Train Set)用来训练数据。
验证集(Validation Set)用来在训练的过程中优化模型(模型优化在下面也会单独讲)。
测试集(Test Set)用来检验最终得出的模型的性能。
训练集必须是独立的,和验证集、测试集都无关。验证集和测试集在个别情况下只有一份,不过当然最好还是分开。这三个集合可以从同一份标注数据中随机选取。三者的比例可以是训练集:验证集:测试集=2:1:1,也可以是7:1:2。总之,测试集占大头。
在用测试集做测试时,我们需要一些具体的评价指标来评判结果的优劣。对于分类和seq2seq识别模型而言,评价标准可以通用。最简单也是最常见的验证指标:精准率(Precision)和召回率(Recall),为了综合这两个指标并得出量化结果,又发明了F1Score。
对一个分类模型而言,给它一个输入,它就会输出一个标签,这个标签就是它预测的当前输入的类别。假设数据data1被模型预测的类别是Class_A。那么,对于data1就有两种可能性:data1本来就是Class_A(预测正确),data1本来不是Class_A(预测错误)。
当一个测试集全部被预测完之后,相对于Class_A,会有一些实际是Class_A的数据被预测为其他类,也会有一些其实不是Class_A的,被预测成Class_A,这样的话就导致了下面这个结果
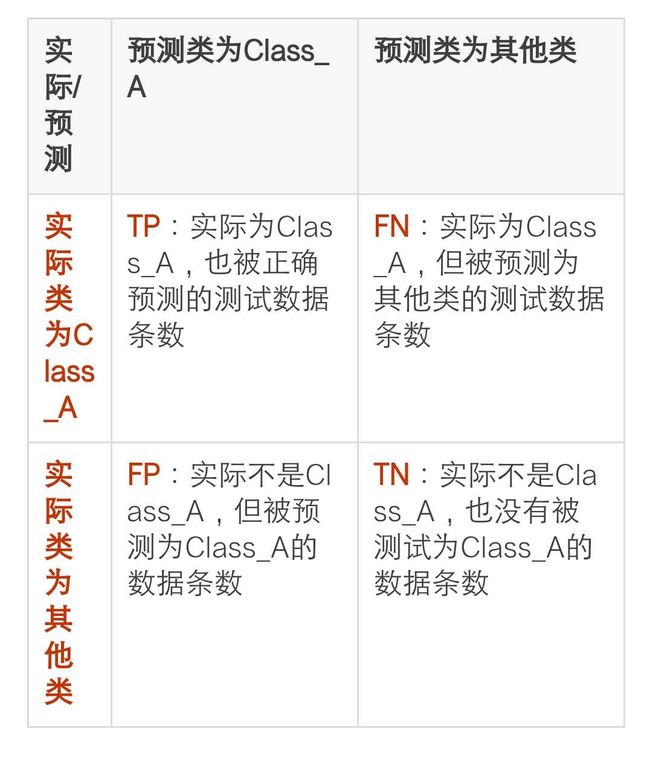
精准率:Precision=TP/(TP+FP),即在所有被预测为Class_A的测试数据中,预测正确的比率。
召回率:Recall=TP/(TP+FN),即在所有实际为Class_A的测试数据中,预测正确的比率。
F1Score = 2*(Precision * Recall)/(Precision + Recall)。
显然上面三个值都是越大越好,但往往在实际当中P和R是矛盾的,很难保证双高。
此处需要注意,P,R,F1Score在分类问题中都是对某一个类而言的。也就是说假设这个模型总共可以分10个类,那么对于每一个类都有一套独立的P,R,F1Score的值。衡量模型整体质量,要综合看所有10套指标,而不是只看一套。
同时,这套指标还和测试数据有关。同样的模型,换一套测试数据后,很可能P,R,F1Score会有变化,如果这种变化超过了一定幅度,就要考虑是否存在bias或者overfitting的情况。
seq2seq识别实际上可以看作是一种位置相关的分类。每一种实体类型都可以被看作一个类别,因此也就同样适用P,R,F1Score指标。
此外还有ROC曲线,PR曲线,AUC等评价指标,大家可以自行查询参考。
构建模型的步骤
笼统而言,为了构建一个模型,我们需要经历以下步骤:
收集语料(收集被标注的数据)
标注数据
将标注数据切分为训练集、验证集和测试集
构建VSM
选取算法
训练(期间要经历多次迭代优化,在验证集上达到最优)
测试
聊天机器人的语言理解需要两个模型,那么上面这套步骤就需要做两遍。
其中唯一有可能共享的,是第一步:收集语料。但并不是说两个模型只能用同一套语料。实践中,两份语料往往是有一部分overlap,但并不全相同。
语料来源何处?
有一些bot的开发目的是为了辅助或者部分替代已有的人工客服。这种情况下,往往之前人工客服和用户对话的log已经积累了很多。从中筛选出比较典型的用户提问语句,就可以用来做模型需要的语料。
如果是冷启动的bot,相对困难一点。可能需要在最开始的时候主动造一些语料。开发者想象自己是用户,把有可能提问的语句直接记录下来作为下面要用的语料。
如果是这样做的话,最好由多个人来共同构造语料。基本上构造语料的人越多,语料与真实环境的收集结果也就越接近。
其后的每一步,两个模型就都是自顾自了。标注部分,请参见上场chat。
四、构建VSM
之前提到了VSM,我们来看看具体怎么构造。
假设训练集中包含N个用户问题,我们把每个问题称为一个文档(document),你要把这N个文档转换成N个与之一一对应的向量。
再假设每个向量包含M维。那么最终,当全部转换完之后,整个训练集就构成了一个NxM的矩阵(Matrix),这就是向量空间模型(Vector Space Model,VSM)。
其中,M是你的全部训练集文本(所有N个文档)中包含的Term数。这个Term具体是一个字、一个词还是别的什么,实际是由VSM的构建者自己来确定。
对于中文而言,这个Term比较常见的有两种选择,一个是分词后的单个词语,另一个是n-gram方式提取的Term。
n-gram中的n和文档个数的N无关(此处特别用大小写来区分他们),这个n是一个由你确定的值,它指的是最长Term中包含的汉字的个数。一般情况下,我们选n=2就好了。当n==2时的n-gram又叫做bigram。n==1时叫unigram,n==3时叫trigram。
N个文档,设其中第i个文档的Term数为ci个(i 取值区间为[1, N])。那么这N个文档分别有:c1,c2...cn个Term。这些Term中肯定有些是重复的。我们对所有这些Term做一个去重操作,最后得出的无重复Term的个数就是M。
针对具体的一个文档,我们就可以构建一个M维的向量,其中每一维对应这M个Term中的一个。
每一个维度的值,都是一个实数(一般在计算机处理中是float或者double类型)。这个实数值,通常的情况下,取这一维度所对应Term在全部训练文档中的TF-IDF(请自行百度TF-IDF)。
假设我们一共处理了1万个文档(N == 10000),总共得出了2万个Term (M == 20000)。这样就得到了一个10000 x 20000的矩阵。其中,每个Vector都只有20多个维度有非零值,实在是太稀疏了。
这样稀疏的矩阵恐怕也不会有太好的运算效果。而且,一些区分度过大的Term(例如某一个Term仅仅只在一个或者极少的文档中出现),在经过运算之后往往会拥有过大的权重,导致之后只要一个文档包含这个Term就会被归到某一个类。这种情况显然是我们要避免的。
因此,我们最好先对所有的Term做一个筛选。此处讲两个特别简单和常见的Term筛选方法:
设定DF(DocumentFrequency)的下限。设定一个Threshold (e.g. DF_Threshold = 2),若一个Term的DF小于该Threshold,则将该Term弃之不用。
根据每个Term的信息熵对其进行筛选。
一个Term的信息熵(Entroy)表现了该Term在不同类别中的分布情况。一般来说,一个Term的Entropy越大,则说明它在各个类中均匀出现的概率越大,因此区分度就越小;反之,Entroy越小也就说明该Term的类别区分度越大。我们当然要选用Entroy尽量小的Term。具体选用多少,可以自己定义一个Threshold。
Entropy_Threshold可以是一个数字(例如8000),也可以是一个百分比(例如40%)。计算了所有Term的Entropy之后,按Entropy从小到大排序,选取不大于Entropy_Threshold的前若干个,作为最终构建VSM的Term。
假设所有的训练样本一共被分为K类,则Entropy的计算方法如下(设tx表示某个具体的Term):Entropy(tx) = Sigmai -- i取值范围为[1,K]
其中,P(ci) 表示tx在第i个列别中的出现概率,具体计算方法采用softmax算法:
P(ci)= exp(y(ci)) /Sigmaj -- j取值范围为[1,K]
其中y(ci) 为tx在类别j中出现的次数。
经过筛选,M个Term缩减为M' 个,我们NxM' 矩阵变得更加精炼有效了。这也就是我们最终的VSM。
五、分类模型
分类模型是机器学习中最常用的一类模型,常用的分类模型就有:Naïve Bayes,Logistic Regression,Decision Tree,SVM等。今天我们在这里介绍其中的Logistic Regression。它也是之前我们介绍的LUIS(https://luis.ai)做意图识别时用到的模型。
LR模型的原理及目标函数
Logistic regression (LR,一般翻译为逻辑回归)是一种简单、高效的常用分类模型。它典型的应用是二分类问题上,也就是说,把所有的数据只分为两个类。当然,这并不是说LR不能处理多分类问题,它当然可以处理,具体方法稍后讲。我们先来看LR本身。
如前所述,模型可以被看做一个形式确定、参数值待定的函数。LR对应的这个函数,我们记作:y=h(x)。
其中自变量x是向量,物理意义是一系列特征,在bot LU的scenario之下,这些特征值就是用户问题经过VSM转换后得出的向量。
而最终计算出的因变量y,则是一个[0,1]区间之内的实数值。当y>0.5 时,x 被归类为阳性(Positive),否则当y <=0.5时,被归类为阴性(Negative)。
如果单纯看这个取值,是不是会有点担心,如果大量的输入得到的结果都在y=0.5附近,那岂不是很容易分错?说得极端一点,如果所有的输入数据得出的结果都在y=0.5附近,那岂不是没有什么分类意义了,和随机乱归类结果差不多?
这样的担心其实是不必要的,因为LR的模型对应公式是:
这个公式对应的分布是这样的:
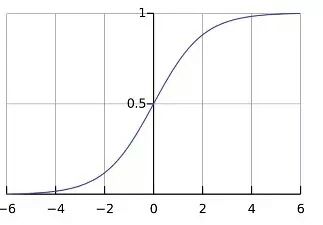
发现没有,此函数在y=0.5附近非常敏感,自变量取值稍有不同,因变量取值就会有很大差异,所以不用担心出现大量因细微特征差异而被归错类的情况。
上述的h(x) 是我们要通过训练得出来的最终结果,但是在最开始的时候,我们是不知道其中的参数theta的,我们所有的只是若干的x和与其对应的y(训练集合)。
怎么通过训练数据中已知的x和y来求未知的theta呢?
首先要么要设定一个目标:我们希望这个最终得出的theta达到一个什么样的效果——我们当然是希望得出来的这个theta,能够让训练数据中被归为阳性的数据预测结果为阳,本来被分为阴性的预测结果为阴。
而从公式本身的角度来看,h(x)实际上是x为阳性的分布概率,所以,才会在h(x) > 0.5时将x归于阳性。也就是说h(x) = P(y=1)。反之,样例是阴性的概率P(y=0) = 1 - h(x)。
当我们把测试数据带入其中的时候,P(y=1)和P(y=0)就都有了先决条件,它们为训练数据的x所限定。因此P(y=1|x) = h(x); P(y=0|x) = 1- h(x)。
根据二项分布公式,可得出P(y|x) = h(x) ^y*(1- h(x))^(1-y)。
假设我们的训练集一共有m个数据,那么这m个数据的联合概率就是:
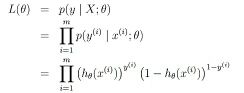
我们求取theta的结果,就是让这个L(theta)达到最大。上面这个函数就叫做LR的似然函数。为了好计算,我们对它求对数。得到对数似然函数:
我们要做的就是求出让l(theta) 能够得到最大值的theta。l(theta) 就是LR的目标函数。
NOTE:目标函数是机器学习的核心。机器学习要做的最关键的事情就是将一个实际问题抽象为数学模型,将解决这个问题的方法抽象问一个能够以某种确定性手段(最大化、最小化)使其达到最优的目标函数。
在此,我们已经得到了LR的目标函数l(theta),并且优化目标是最大化它。为了获得l(theta)的最大值,我们要对它求导:
因为l(theta)为凸函数,因此当其导数函数为0时原函数达到最大值。所以,我们要求取的,就是上述公式为0时的theta,其中的y(i)和x(i)都是已知的。
LR的算法
上面是LR的基本原理和公式。在上述目标函数的导函数中,如果求解theta呢?具体方法有很多,我们在此仅介绍最常见最基础的梯度下降算法。
我们已经知道l(theta)函数是有极值的,那么如何去找到这个极值呢?
我们可以试,即先找到这个函数上的一点p1,算出它的函数值,然后沿着该点导数方向前进一步,跨到p2点,再计算出p2点所对应的函数值,然后不断迭代,直到找到函数值收敛的点为止:
Set initial value: theta(0), alpha
while (not convergence)
{
}
其中,参数α叫学习率,就是每一步的步长。步长的大小很关键,如果步长过大,很可能会跨过极值点,总也无法达到收敛。步长太小,则需要的迭代次数太多,训练速度过慢。可以尝试在早期的若干轮迭代中设置一个较大的步长,之后再缩小步长继续迭代。
具体判断收敛的方式可以是判断两次迭代之间的差值小于某个阈值ϵ(即比阈值小就停止)。有时候,在实际应用中会强行规定一个迭代次数,到了这个次数无论收敛与否都先停止。具体推出迭代条件要按实际需要确定。
LR处理多分类问题
LR是用来做而分类的,我们的意图识别肯定不是只有两个意图啊,怎么能用LR?!
别急,LR一样可以做多分类,不过就是要做多次。
假设你一共有n个intent,也就是说可能的分类一共有n个。那么就构造n个LR分类模型,第一个模型用来区分intent_1和non-intent_1(即所有不属于intent_1的都归属到一类),第二个模型用来区分intent_2和non-intent_2,..., 第n个模型用来区分intent_n和non-intent_n。
使用的时候,每一个输入数据都被这n个模型同时预测。最后哪个模型得出了positive结果,就是该数据最终的结果。
如果有多个模型都得出了positive,那也没有关系。因为LR是一个回归模型,它直接预测的输出不仅是一个标签,还包括该标签正确的概率。那么对比几个positive结果的概率,选最高的一个就是了。
例如:有一个数据,第一和第二个模型都给出了positive结果,不过intent_1模型的预测值是0.95,而intent_2的结果是0.78,那么当然是选高的,结果就是intent_1。
六、seq2seq判别模型
seq2seq判别模型在一定程度上也有分类的意味。不同之处在于,seq2seq当中每一个被分类的片段,究竟最终被分为哪个类,除了与其自身相关,还与其前后片段的相互位置有关。
在文本处理当中,linear-chain CRF(线性链CRF)是最常用的一种seq2seq判别模型,也是LUIS在做实体提取时用到的模型。
上图显示了LR和线性链CRF的联系与区别。上图中的灰色节点为输入给模型的自变量(x1,x2,x3),而白色节点则是模型输出的结果。
可见,LR中,多个特征输入后得到了唯一的分类结果。而线性链CRF中,决定一个输出的除了和它对应的输入,还有排在它之前的那个输出。
举个例子:对“我要一张从北京到上海的机票。” 进行LR分类(意图识别)的时候,整句话都被分为”购买机票”意图。而当对其进行线性链CRF判别时,则会将”北京”抽取为出发地,”上海”抽取为到达地。
直观的来看,我们也不难发现,当运行线性链CRF时,“从”字在“北京”之前,“到”在“上海” 之前;而且,在判别到达地时,前面已经抽取出了出发地,这些都对当前的判别有所贡献。
线性链CRF模型的原理及目标函数
线性链条件随机场的定义是: 设X=(X1,X2,...,Xn), Y=(Y1,Y2,...,Yn)均为线性链表示的随机变量序列,若在给定随机变量序列X的条件下,随机变量序列Y的条件概率分布P(Y|X)满足马尔可夫性(请自行搜索马尔科夫性定义), 则称P(Y|X)为线性链条件随机场。
在实体提取问题中,X表示输入观测序列(用户问题),Y表示对应的输出标记序列(实体类型)。
线性链条件随机场的模型:
线性链CRF模型表示:给定输入序列x,对输出序列y进行预测的条件概率。
其中,上式右侧分母部分是规范化因子。
t(k) 是链状图中边的特征函数,称为转移特征(t for transition),依赖于当前和前一个位置,s(l)是图中节点的特征函数,称为状态特征(s for status),依赖于当前位置。无论哪种特征函数,都将当前可能的y(i)作为参数。它们都依赖于位置,是局部特征函数。
通常,特征函数t(k)和s(l)取值为1或0;当满足特征条件时取值为1,否则为0。lambda(k)和mu(l)是它们对应的权值。
为简便起见,将转移特征和状态特征及其权值用统一的符号表示。设有K1个转移特征,K2个状态特征,K=K1+K2,记作:
上式其实是对特征函数进行编码,编号的前K1个属于转移特征,后K2个属于状态特征。
然后,对转移与状态特征在各个位置i求和,记作:
其中虽然有4个参数的形式,但对状态特征函数而言,y(i-1)会被忽略掉。
用wk表示特征fk(y,x)的权值,即:
于是,线性链条件随机场模型可简化表示为:
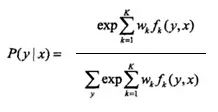
其中,右侧分母为归一化因子, wk为模型的参数, fk(x,y)为特征函数(feature function)。
线性链条件随机场模型实际上是定义在时序数据上的对数线形模型,其学习方法包括极大似然估计和正则化的极大似然估计。它的优化目标函数是:
其梯度函数是:
线性链CRF的算法
线性链CRF具体的优化实现算法有:改进的迭代尺度法IIS、梯度下降法以及拟牛顿法等。
其中应用较广的BFGS算法(属于拟牛顿法)如下:
Set initial value: w(0)
B(0)=I //positive definite matrix
K = 0
while(gk != 0)
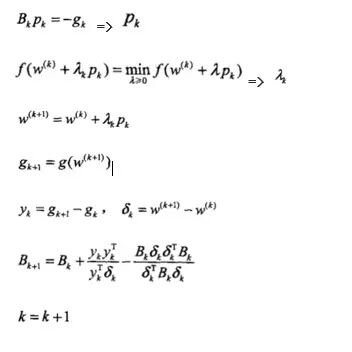
}
七、算法库
前面两节讲了LR和linear-chain CRF的原理、目标函数以及常见学习方法。如果大家非常有兴趣自己动手实现算法,确实可以develop your own machine learning library from scratch。
本着理解数学模型的目的,自己实现算法作为练习和复习,也是好的。不过,并不建议大家自己拿自己实现的算法在工作中实际应用。
这牵涉到投入和效率的问题,如果你看过Andrew Ng的Machine Learning公开课,就会知道,Andrew Ng是很反对自己写实际用到开发中的算法的。
自己开发算法难于保证质量是一个方面——让一个算法运行起来容易,bug free可就难了,关键是找到bug都非常不容易。除此之外还要保证性能问题,对计算资源、存储资源的管理和使用问题,这些问题和我们关注的模型、算法、数据都没有什么关系,非要自己投注精力,很可能和主要工作相互牵制,而非相辅相成。
另外,算法实现后和数据的接口也是一个问题。如果我们自己实现算法,让它支持某一种schema的输入数据容易,接收多种,就要花费很多精力时间在接口的实现和调试上。这些都是必不可少的,但却又和实际业务相去甚远。
如果应用机器学习的目的是为了解决实际问题,人家有好的工具,比自己写省时省力功能丰富还效率高,为什么要自己造轮子呢?还是选用已经得到证明的现成算法库吧。
现成的算法库品类繁多,各种语言基本都能找到通用的算法支持。目前机器学习领域最长用的语言是Python,Python 的Scikit-learn库中就有许多机器学习算法。
如果你想自己试试写算法,也推荐从Python入手。Numpy库中的许多函数让开发者可以在程序中实现复杂的科学计算。
CRF++模型是一个应用很广的CRF工具包,有Java,C++, Python,Ruby, Perl 等多种语言形式。以笔者所见,实践中使用CRF模型时,大部分开发者都会选用CRF++。
八、模型的优化
模型的优化可以从三个方面来进行:数据、算法和模型。
训练数据的扩充、清洗和预处理
机器学习的模型质量往往和训练数据有直接的关系。这种关系首先表现在数量上,同一个模型,在其他条件完全不变的情况下,用1,000条train data和100,000来训练,正常情况下,结果差异会非常明显。大量的高质量训练数据,是提高模型质量的最有效手段。
当然,对于有监督学习而言,标注是一个痛点,通常我们可以用来训练的数据量相当有限。在有限的数据上,我们能做些什么来尽量提高其质量呢?大概有如下手段:
对数据进行归一化(normalization), 正则化(regularization)等标准化操作。
采用bootstrap等采样方法处理有限的训练/测试数据,以达到更好的运算效果。
根据业务进行特征选取:从业务角度区分输入数据包含的特征,并认识到这些特征对结果的贡献。在文本处理中,这一点可以通过选取输入项来实现,也可以通过构建VSM实现。
调参
很多机器学习工程师被戏称为调参工程师。这是因为调参,是模型训练过程中必不可少又非常重要的一步。
大家已经知道,我们训练模型的目的就是为了得到模型对应公式中的若干参数。这些参数是训练过程的输出,并不需要我们来调。
除了这些参数外,还有一类被称为超参数的参数,例如用梯度下降方法学习LR模型时的步长(Alpha),用BFGS方法学习Linear-chain CRF时的权重(w)等。这些参数是需要模型训练者自己来设置和调整的。
调参本身有点像一个完整的project,需要经历:
制定目标
制定策略
执行
验证
调整策略-> 3.
这样一个完整的过程,其中3-5步往往要经由反复迭代。
调参有许多现成的方法可循,比如grid search,大家可以自行检索学习,应用这些方法,使得指定和调整策略有章可循,也可以减少许多工作量。
算法库本身对于各个算法的超参数也都有默认值,第一次上手尝试训练模型,可以从默认值开始,一般也能得出结果。
模型选择
有的时候,训练数据已经既定,而某个模型再怎么调参,都无法满足在某个特定指标上的要求。那就只好换个模型试试了。比如LR不行,还可以换Decision Tree或者SVM试试。
现在还有很多深度学习的模型也逐步投入使用。不过一般情况下,DL模型(CNN,DNN,RNN,LSTM等等)对于训练数据的需求比我们今天讲的统计学习模型要高至少一个量级。在训练数据不足的情况下,DL模型很可能性能更差。
而且DL模型的训练时间普遍较长,可解释性极弱,一旦出现问题,很难debug。因此再次建议大家:在应用场景下,不要迷信cutting edge technology,无论工具还是方法,选对的,别选贵的。
经验杂谈
之前在工作中开发Bot产品时,笔者也自己写过意图识别和实体提取的模型训练/预测程序。
具体做法是:构造VSM;导入语料将VSM的输出结果作为某一种特定算法(例如LR,DT,CNN等)的输入进行训练;得出模型后通过交叉验证调参;在当前算法下达到F1 Score最优后,再横向比较几种不同的模型,最后选出整体最优的模型。
在这样的过程中,所训练算法,不管是Logistics Regression还是Fast Tree(Decision Tree的一种),都是用的现成的Library,都没有自己写。
最开始自己构建VSM是为了控制feature的选择,比如是分词还是n-gram,切分gram之后是计算tf-idf还是信息熵,等等。
可是后来发现,对于一个模型好坏的影响,具体的feature选择比不上训练数据本身的质量的影响大。
LUIS(https://luis.ai)本身提供了非常友好的用户界面,可以很方便的进行数据标注,而且VSM的构建虽然针对性不强,但是融入了多任务学习等方法,使得generic model质量不差。虽然我们的产品,因为concurrency和lantency的要求比较高,最终还是没有选用LUIS,但是笔者相信,对于普通用户,在早期Bot开发中应用LUIS会是一个很好的选择。
GitChat 是一种全新的阅读/写作互动体验产品。一场 Chat 包含一篇文章和一场为文章的读者和作者定制的专属线上交流。本文出自 Chat 话题《聊天机器人语言理解模块开发实践》。