reference:https://arxiv.org/abs/1612.08242
author: Joseph Redmon , Ali Farhadi
Abstract
提出了一些新的想法将YOLO改进成了YOLOv2,也想办法将物体检测和分类方法结合了起来。
Introduction
大多数物体检测算法的检测类别还不够多,用于物体检测的图片数据集没有分类的多。所以本文提出了一个新的方法来将这些数据集都运用起来。本文还提出了将物体检测和分类的过程结合在一起的算法。
Better
YOLO算法的召回率和局部错误率需要改进。本文也想办法化简了网络。
Batch Normalization
通过在YOLO中增加批量归一化,在mAP数值上增加了超过2%,而且也给模型提供了一些正则效果。在加入批量归一化之后,即使删除模型中的dropout也不会产生过拟合。
High Resolution Classifier
为了使网络对于高分辨率的输入图片产生好的结果,所以本文使用了在ImageNet上预训练过的以448*448分辨率为输入的网络
Convolutional With Anchor Boxes
本文参考了Faster-RCNN中的RPN网络,用Anchor Box来进行预判定。
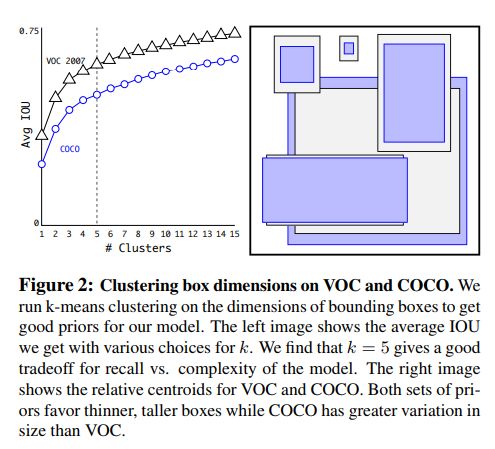
Dimension Cluster
YOLO的预选框是手工挑选的,所以如果能改用更好的预选框会对训练有帮助。本文使用k-means方法来挑选好的预选框。如图所示
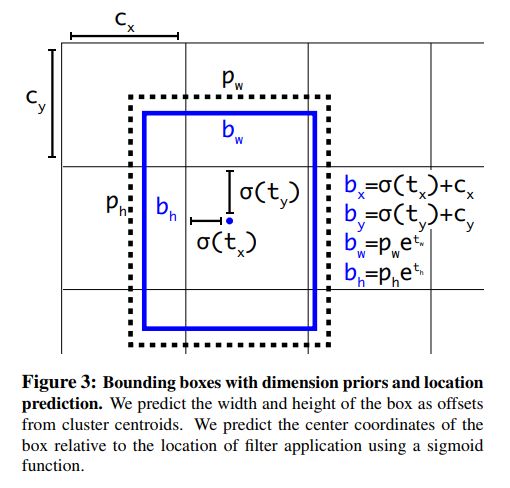
Direct location prediction
在引入anchor box的时候有第二个问题,模型不稳定,这种不稳定主要来自直接预测box的(x,y)值。所以,本文中直接预测相对于grid cell的坐标位置。如图所示
Fine-Grained Features
本文中通过添加一个passthrough层将高分辨率的特征图和低分辨率的特征图联结在了一起。
Multi-Scale Training
为了能让网络适应不同大小的输入图像,所以每过10个批次就换一个维度的图片作为输入来训练图片,最后的模型对低分辨率和高分辨率的图片都有很好的识别效果。具体表现如图
Further Experiments
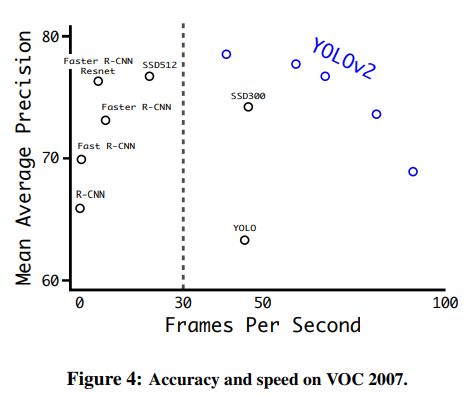
和其他算法的比较如图
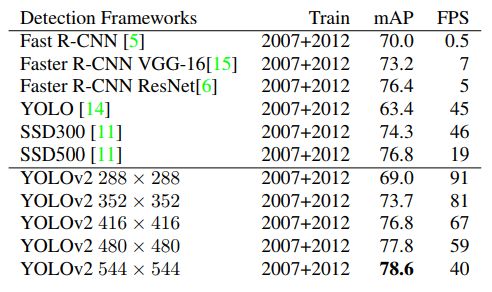
Faster
其他网络常用VGG-16作为特征抽取器,但是它计算量大,速度较慢,所以本文使用GoogleNet
YOLOv2在PASCAL VOC2012上的表现和COCO test-dev2015上的表现如下

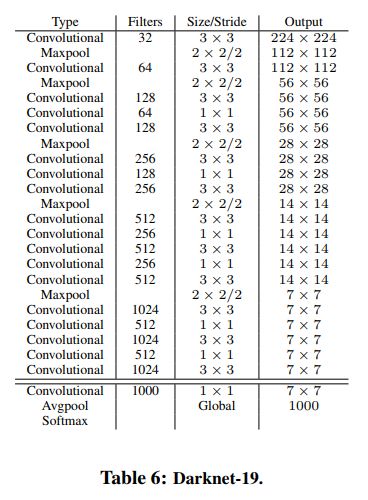
Darknet-19
运用了类似VGG模型的3*3卷积核,也运用了NIN,还有全局平均池化和1*1卷积核来压缩特征表示。也运用了批标准化来稳定训练,加速收敛,并对模型产生正则效果。最后,模型被称为DarkNet-19,有19个卷积层和5个最大池化层。架构如表6所示
Training for classification
在ImageNet 1000上进行了160轮的训练。使用的是随机梯度下降,初始学习率为0.1,权重衰减为0.0005,动量为0.9。在训练时还使用了标准的数据增强。
Training for detection
把网络修改了,去掉了最后一层卷积层,用1024个3*3的卷积核后跟1000(如果要分1000类)个1*1的卷积核。然后是一些训练的细节。
Stronger
在训练时将检测数据集和分类数据集的图片混合着作为输入。当训练检测的图片时,可以反向传播YOLOv2的损失函数。如果训练分类图片时,只反向传播分类结构的损失函数。
然后检测数据集和分类数据集的类别又不同,比如检测数据集中是"dog"而在分类数据集中有好多更细分类的标签,所以需要多标签模型。
Hierarchical classification
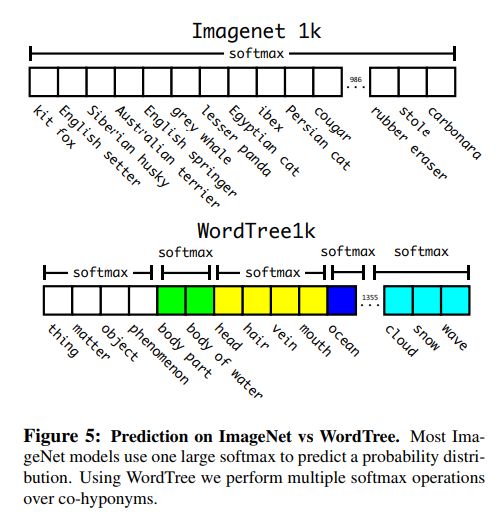
用WordNet这个数据库来对标签进行层级分类。WordNet是一个直连图,比如"dog"就和"canine"及"domestic animal"连在一起。为了避免使用全图结构,本文将这个图简化成层级树来使用,就像ImageNet中的用法。
为了运用这个分类树,本文在树的每个节点及其继续分类的条件概率。如果要计算一个特殊点的概率,那么直接按照树的连接就行了。如图

对某个标签,在训练时会追溯它的祖先标签,以及在计算softmax的时候,同一类的标签是分在一起的。如图
模型的鲁棒性不错,在分类时如果发现一张狗的图片,即使没有办法细分,它也会返回"dog"标签。
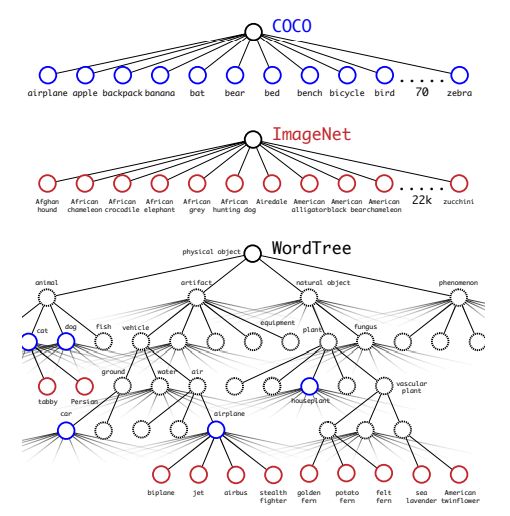
Dataset combination with WordTree
使用WordTree来进行数据集的合并,如图所示
Joint classification and detection
结果表现不错
Conclusion
本文介绍了YOLOv2和YOLO9000。YOLOv2是一个实时检测系统,在不同大小的图片上能很好的平衡速度和准确率。
YOLO9000是一个通过合并检测和分类,能检测超过9000类物体的实时系统。本文使用WordTree来合并ImageNet和COCO数据集。
然后吹了一下本文提出的方法也可以在其他领域使用。
本文表示未来准备研究将模型用在弱监督图片分割上,也考虑通过给分类数据集增加若标签来加强检测的结果。