
作者 | 邱戈川(了哥) 阿里云智能云原生应用平台部高级技术专家
本文根据云栖大会全面上云专场演讲内容整理,关注阿里巴巴云原生公众号,回复“迁移”获得本文 PPT
今天上午王坚博士讲了一句话我比较有感触,大家做系统的时候,一定要想下你的系统的数据是怎么流转,这些系统的数据是怎么形成闭环。我们在设计阿里云的 K8s 容器服务 ACK 的时候也是融入了这些思考。
容器迁云解决方案一览
首先是和大家先看一下整个容器上云的解决方案。首先因为你已经做过容器,所以当你容器上云的时候,实际上这个事情是非常简单的,我们只需要提供的相应的工具,帮助大家把容器镜像迁入阿里云同时通过工具把 K8s 的配置迁到阿里云,以及可以用 DTS 工具把数据库迁入到阿里云。这样我们就可以完成一个完整的容器化上云的过程。

所以这个过程其实非常简单,但是上完云之后,不是说我们的 K8s 原来怎么玩现在还是怎么玩。我们希望大家从上云的过程中有些收益,所以我们希望提供一些更高效敏捷的一些方式给到大家,包括怎么去做 DevOps,包括我们怎么去做安全的软件供应链,以及我们做灰度发布。
同时我们希望成本更优一点,关键是大家上完云之后的成本怎么去核算,以及怎么去节约。所以容器上云后我们怎么去做更好的弹性伸缩、做自动化的运维,这个是大家需要在上云的过程中去考虑的问题。同时我们需要更好的管理我们的系统,一定要做到更好的高可用,而且要做到一个全局的管理。包括现在很多的公司已经在做混合云管理,这个也是大家在上云的过程中需要考虑的问题。
阿里云的 K8s 容器服务 ACK 到底长什么样,给大家一个概览图:
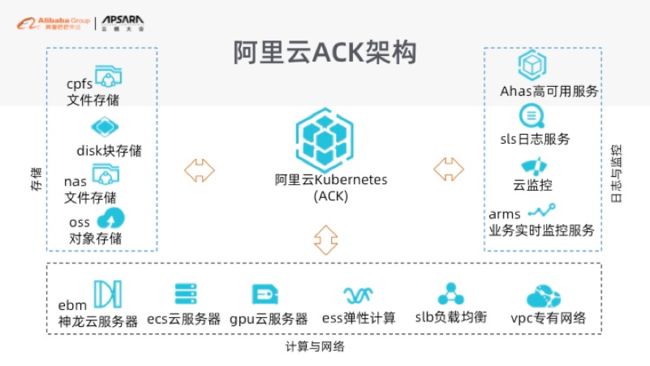
中间的 K8s 部分就跟大家去玩开源自建是一个道理,这个 K8s 没有什么本质上的区别。但是上了阿里云之后,我们希望给到大家的是一个完整的体系,而不是单单一个 K8s。所以我们会把底下的部分跟我们的 GPU 服务器、跟我们弹性计算 ECS、跟我们的网络 VPC、跟我们的 SLB 打通。这个在上完阿里云 ACK 之后,我们一键的方式把它全部集成好,所以大家不用再去关心阿里云的 IaaS 层应该怎么去做,我们希望给大家屏蔽掉这一层复杂性。
存储也是一样的道理。存储的话,就是所有的阿里云的存储我们全部都已经支持完了,但是现在我们还在做什么事情?我们在把阿里云的日志服务、阿里云的中间件服务,包括我们 APM 的 ARMS、我们云监控、以及我们高可用服务 Ahas 等全部对接在一起,让大家有一个更高可用的环境,以及一个更安全的环境。
我们给到大家一个 K8s 还是个原生态的 K8s,大家可能会问我们你的 K8s 跟我自己的 K8s 到底有什么区别,所以还是很简单的回答大家这个问题。首先我们在上云的过程中给到大家永远是一个非云厂商锁定的 K8s。就是你在线下怎么玩 K8s,在线上也可以怎么玩 K8s。如果你哪天你想下云的时候,你一样是可以下去的,所以这是我们很坚持的一个宗旨,就是我们不做任何的锁定。
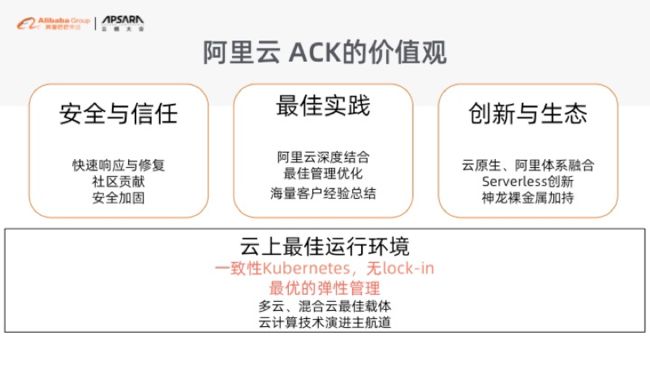
是我们会注重什么事情?
- 首先我们会去考虑怎么做好安全,就是当你的 K8s 有问题时,我们怎么做快速响应,做 CVE 快速修复,然后我们怎么去打补丁,我们怎么做安全加固;
- 第二就是我们跟阿里云的整个生态做结合。因为阿里云是我们更熟悉,所以我们跟阿里云的底层技术设施怎么打通,这个事情我们自己会做得更好一点。
我们现在也跟神龙服务器在一起,我们知道怎么让神龙服务器发挥更好的性能。同时我们还有很多创新,这样可以帮助大家更好的做好弹性。最重要的一点实际上是:我们做了那么久,已经积累了超过几千家的在线客户,这也是我们最大的优势。所以我们从几千家的客户里面浓缩回来大家所需要的最佳实践,我们收集完、整理完之后要返回给大家,帮助大家去用 K8s 上生产,这也是我们给客户最大的一个核心价值。
容器上云之“攻”
上完云之后,怎么用好 K8s?怎么提升你的整个管理能力、提升你的系统效率?这个是我们要讲的“进攻”的部分。我们主要分三个方面去讲:
- 第一个,怎么跟我们阿里云的裸金属服务器做结合;
- 第二个,我们会提供性能比较优化好的网络插件 Terway;
- 第三个,怎么做好灵活的弹性。
物理裸金属服务器神龙
神龙裸金属服务器已经跟我们的容器平台 ACK 做了无缝融合。它最大的好处是什么?在容器化的时代,我们不需要再去考虑虚拟化的问题。所以两者的融合基本上是一个零虚拟化的开销的方案,容器直接使用到物理上的资源。在我们的神龙服务器里面,给到大家的实际上是个真实的 Memory 以及真实的 CPU,但它因为使用了阿里云专有的 MoC 卡技术,所以它可以直接对接到阿里云的云盘、对接到阿里云的 VPC 网络。这样的话它的体验跟所有的 ECS 是一个道理。
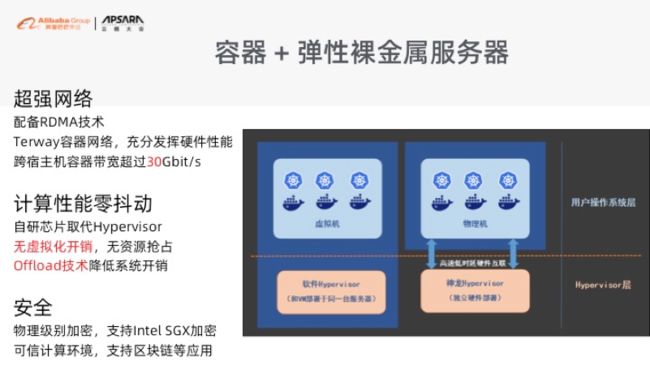
这样容器化去做资源切割的时候,我们就不会再受虚拟化的影响。同时,它带来了另外一个好处就是它有一个 offload 的技术。这样网卡的中断会下沉到下面的这张卡上去,当你的流量比较大的时候,它将处理所有的网卡中断的开销,并不开销你本身的 CPU,所以我们可以得到一个更极致的计算性能。
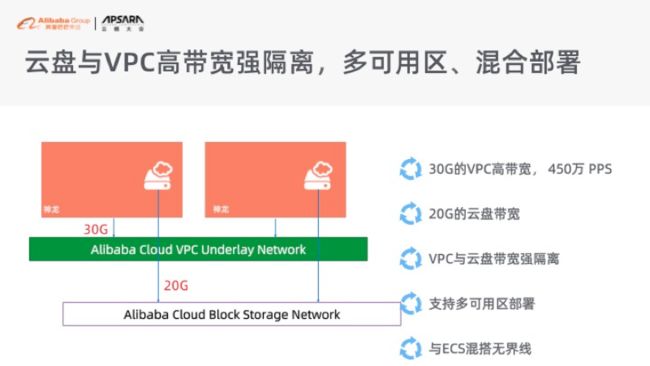
同时因为它的密度比较高,它基本上是个 96 核的机器,当它加入容器集群之后,这个集群的容器的密度相对来说会比较高,所以它成本节约会比较好一点。另外,它是整个阿里云弹性计算资源里面最高规格的网络带宽,单独给 30G 的网络带宽带给到 VPC,同时有 20G 的网络带宽留给云盘。这样大家可以比较好的去部署高密度的容器,同时它还是可以支持跟 ECS 是混搭组建集群的。这个特点在弹性场景里面特别高效。你日常的流量可以用到神龙服务器去构建,当你要去做动态伸缩的时候,你可以用 ECS。这样两种弹性资源一起使用会帮助大家把成本做到最优。
性能优化网络 Terway
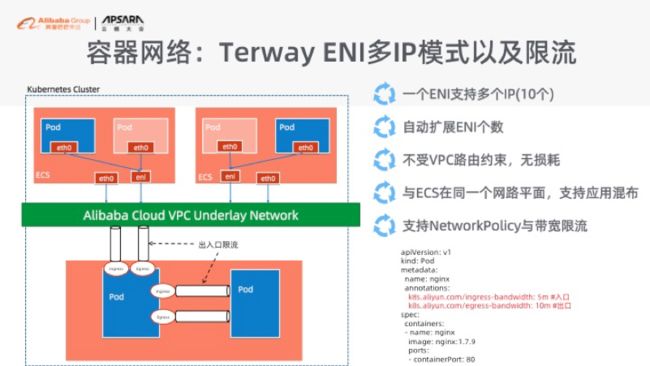
另外一个方面,就是网络支持的情况了。网络的话是由阿里云独创的 Terway 网卡的多 IP 方式。实际上我们利用了阿里云里面的 ENI 的弹性网卡来构建我们的容器的网络,这样的话我们可以用一个 ENI 来支持 10 个 IP,来构建我们的 POD 网络。它最大的好处就是它不会再受 VPC 路由表大小的约束。POD 跟你的 ECS 或者神龙服务器在同一个网络平面,所以它的网络中转开销是非常小的。
同时我们还支持了 Network Policy,就是 K8s 里面标准的 Network Policy,以及我们扩展了带宽限流。这样的话也是避免大家不知道怎么去做网络内部的 POD 跟 POD 之间的安全管控,以及去做 POD 之间的网卡的带宽的约束,避免一个 POD 可以打爆整个网卡,这样的话就会比较好的去保护你的网络。而这个只需要添加 annotation 就可以完成,不影响 K8s 的兼容性。
灵活弹性
最后一个就是我们要去做灵活的弹性。做 K8s 有个说法:你不做弹性基本上就相当于没玩 K8s。所以,我们给大家提供了一个完整弹性的体系,除了标准的 HPA 去做伸缩 POS 之外,我们实际上还提供了阿里云开源的 CronHPA,就是定时的方式来支持大家去伸缩 POD。我们还提供了额外的指标,来帮助大家按指标的方式来去做弹性伸缩。包括我们日服务 SLS 里面提供的 Ingress Dashboard,拿到你的 QPS 以及 Latency,或者从我们的 Arms、Ahas 拿到你的每一个 POD 流量的情况,每个 POD 延迟的情况来做对应的伸缩。
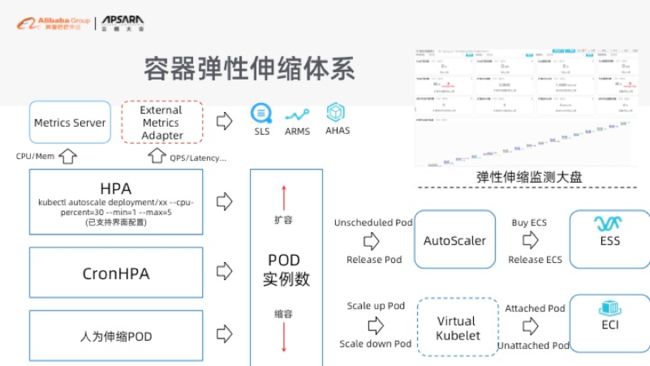
因为大家知道你的程序可能开发出来之后,不一定能那么好的完美地去适配 CPU。也就是说不是你所有的 POD 都能够按照 CPU 的方式来做伸缩,这个时候你就需要根据我们提供的额外指标的方式来做伸缩,这是公有云里面给大家一个比较好的弹性的方式。
另外一个问题就是,当你的资源不够的时候,你可能就需要买更多的机器来支持容量,这个时候我们提供了 Autoscaler,它会对接阿里云的 ESS 来帮助大家自动化的方式来够买机器,然后再重新扩容。通过这种方式,来帮助大家做好自动化的运维。
但是这里也有一个问题,你可能希望这个伸缩速度会更快。但是从购买台机器到冷启动再到加入 K8s 集群,然后再去扩容器这个时间会比较长,如果你的业务是一个突发业务的话,可能你等不及机器伸缩。为了适配这个场景,我们现在又融合了阿里云的 ECI,利用弹性容器实例来做这个事情,我们做了一个虚拟化的 Kubelet,来对接 ECI。这个时候大家不需要再去买机器,你可以直接用扩容的方式去做就好了。
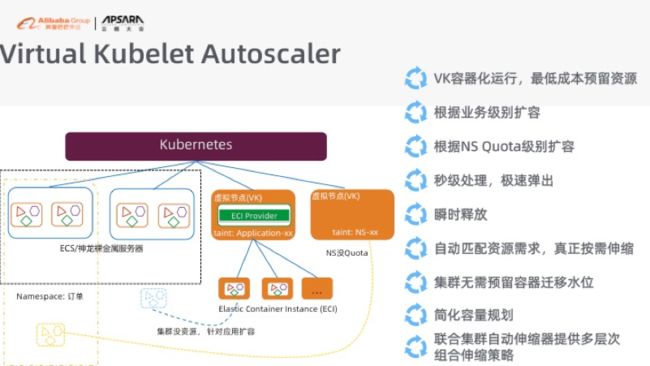
所以它最大的好处是什么?就是说你不需要额外买机器,你只需要根据你的业务的情况下,直接伸缩容器,它会到 ECI 的池子里面去找到对应的空闲容器,然后挂到你的集群里面去。当你不需要的时候,它更快,它直接就可以释放掉了。因为大家知道,如果你是普通的方式,你还要等那台机器所有的容器全释放才可以释放机器,这时还有一个时间差。
大家知道,弹性好最耗钱的地方就是时间。所以我们用最快的方式来帮大家去节约掉这个成本。同时大家如果用这样的方式,还可以不去做容量规划,因为很多时候很难去做容量规划。如果今天有 100QPS,明天又有 1000个QPS,我不知道这个容量怎么做,这个时候利用 ECI 的技术,大家就可以避免这个容量规划了。

当然我前面提到,阿里云 ACK 制定了很多自定义的指标,所以大家只需要去配置对应的定制指标,根据 QPS 也好,平均 Latency 也好,还是 P99、P999 这些相应的最大延迟指标,以及你的入口流量的指标,来做相应的伸缩。所以大家只需要根据这些指标来配置对应的 HPA 的扩容伸缩就可以了。这样的话,大家比较容易去找到适配你业务场景的方式。特别是对于电商场景来讲,如果大家比较有经验的话,大家很多时候根据 QPS 去做是比较合理的。
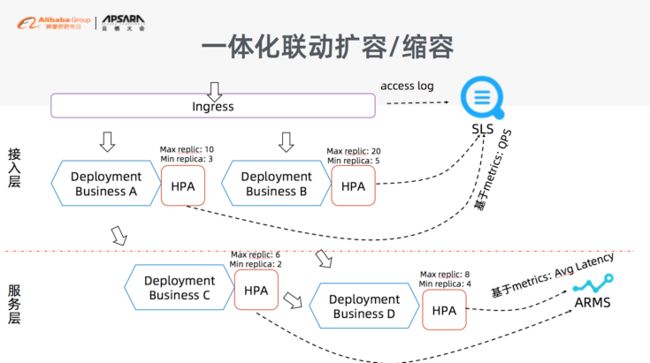
另外,伸缩不是做某一个业务/应用的伸缩。大家一定要记住一点就是:伸缩一定是一个一体化的联动性的伸缩,所以大家一定要从接入层到服务层同时考虑伸缩性。我们利用了 Ingress Dashboard 的指标(后面监控会提到),拿到了 QPS,可以伸缩我们的接入层,同时我们可以根据 APM 的系统,就是像阿里云的 ARMS 这样一个系统,拿到对应的 Latency 来伸缩我们服务层。这样的话,大家可以构造一个联动性的全局性的伸缩。不然很可能你在入口层面上做了一次伸缩,直接把流量倒了进来,最后打爆了你的服务层。
大家一定要考虑这一点,就是所有的伸缩一定是联动性、全局性的。
容器上云之“守”
前面讲了,我们怎么去更好地去做管理?以及我们有什么好的方式来提高我们的性能?第三部分的话给大家讲一下怎么去做防守,主要有三部分:
- 怎么做智能化运维;
- 怎么做安全体系;
- 怎么去做监控体系。
智能化运维

从管理角度来讲的话,大家不可或缺的点就是一定要去做灰度。从接触的情况来看,很多同学实际上并没有完全做到全灰度才上线。但在阿里云这个是强制要求,在 K8s 里面有方便的方式,大家可以用 Ingress 的方式来做灰度。其实比较简单,就是大家原来有一个旧的服务,那重新启动一个新的服务,都挂同一个 Ingress 上。那你在 Ingress 上面配置流量分割。可以是 90% 的流量割了旧服务,10% 的流量给到新的服务,这样的话,Ingress 会帮你做一个分流,这是比较简单的一个方式。
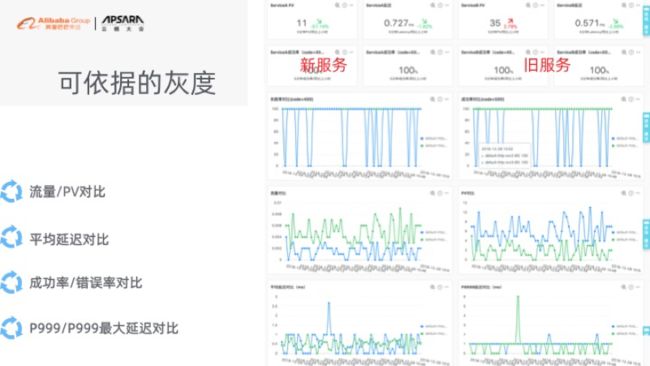
但是这里面还有个问题:大家怎么知道什么时候能不能把 90% 的流量再切割10%流量过去新服务,让 10% 变成 20%?这个是大家目前比较痛苦的一个地方。因为很多时候发现很多同学,他们最常见的方式是什么?就是找了一个测试同学过来,帮我测一下新的服务到底 OK 不 OK,如果 OK 它就直接将 90% 的流量下降到 80%,将 10% 的流量涨到 20%,但当它涨上去的时候你的系统立马出问题。
因为什么?因为你没有很好的依据去做这个流量的切割,你只是去看测试结果,只是看了当时那一刻到底对还是不对,而不是全局性的来看。所以在阿里云的 K8s 里面,我们会帮助大家集成好对应的灰度监控,然后帮助大家去做好可依据的灰度。我们会同时帮助大家去对比新的服务、旧的服务、当前的流量、平均的延迟、错误率、成功率、最大的延迟等等。通过这些去看新服务到底是不是已经满足你的真实的要求,以这个对比的依据来看,你流量的是否应该再继续切割。
就像刚才这例子一样,新服务 10% 要变成 20%,很可能你的延迟已经在增大、你的错误率已经在升高,这个时候你并不应该再去增加流量,而是要做回滚。大家一定要记住一点,就是我们在运维的过程中,一定要做到运维所有的动作一定要有依据。所以我们利用 Ingress Dashboard 给大家去做相关有依据的灰度。
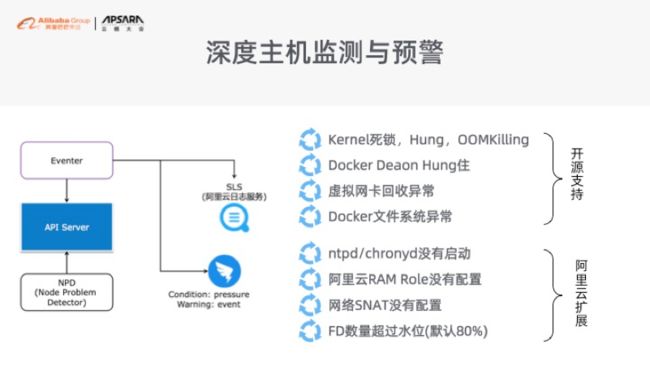
另外是给大家做好对应的主机上在容器层面上的对应的监测和预警。在开源体系里面有一个组件叫 NPD,然后我们阿里云又开一个事件告警器叫 Eventer。我们把这两个东西打成了一个 Helm 包,在应用目录里面提供给大家。大家可以做好相应的配置之后,当你发生 Docker 挂了、当你发现主机时间同步有问题,或者程序没开发好造成 FD 被打爆,这个时候我们会把相应的通知,通过钉钉的方式发给大家。
大家一定要记住在上完容器之后,你还在容器层面上的主机层的监控,跟你普通的非容器的主机监控是有区别的。所以大家接下来一定要想办法把容器层面的主机监控再重新补回去。
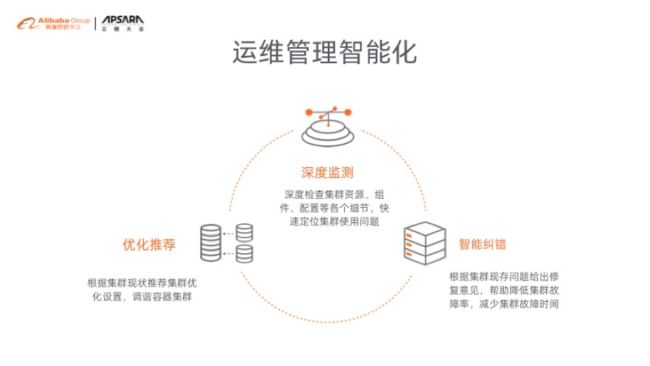
另外,我们还一直在深化去做一些智能化的运维。例如容器上云后还必须做一些相关优化的配置。大家知道,上云之后,K8s 应该用什么机器?用什么的 SLB?用什么网络?这些东西都需要做一个选优,根据你的业务场景去做选优,怎么去选呢?我们会做一些相关的优化的推荐,帮助大家去做一些相应的深度的监测,你到底有没有改过哪些配置,哪些配置被你改错了等等。
如果有一些错误的配置,智能运维会提醒你要去做一些纠错,减少大家后期发现错误的纠错高成本。这一块,我们还一直在深化中。
安全与信任

“防守”的第二件事情是要做安全。上云之后,大家会觉得就主机层面上的安全不一定够了。所以在容器管理层面上大家还需要去看看这个安全应该怎么做。安全的话,就是大家还是要记住一点就是安全一定要做全方位的安全,大家不要把安全认为是一个很小的事情,特别是很多公司是没有安全团队的,所以这个时候运维要承担好这个职责。
安全的话,我们主要是分三个方面来做安全。
- 第一就是“软性安全”,例如社区层面的合作,然后是阿里云安全团队来帮我们做相应的一些“加持”,同时我们也会给客户做一些定期的安全的赋能。
- 另外一块的话就是 IaaS 层的安全,我们会做一些 CVE 的修复。我们还有阿里云自己的 IaaS 加固,以及我们现在还有镜像漏洞扫描。阿里云的镜像仓库已经支持了镜像扫描,所以这里也提醒大家:每次上业务、上生产之前,务必做一次镜像扫描,所有的开源社区提供的镜像都可能有漏洞。所以怎么去做好这些漏洞的防护,大家一定要下好功夫。同时我们提供对应的磁盘的加密,这一块大家可以做好数据的加密。
- 在 K8s 运行层面的话,我们团队做的更多的是在 K8s 审计日志方向,我们过会儿讲一下。包括我们会有更严密的 K8s 的这种安全的配置,以及我们会去做容器运行时的实时安全监测。大家有兴趣的话,可以看看阿里云安全的产品,他们已经支持了安全运行态的这种实时检测。
同时我们还支持安全的管控,就是所有的安全配置我们都是双向认证。特别强调一点就是从管理层面上来讲的话,我们会做好对应的整个平台的安全管理,这里更多的是针对内控。大家知道,实际上真正能偷盗你数据那个人,最容易的那个人是你们公司运维里面最有权限的那个人。所以,这里面才是大家日常需要重点管控的一个地方。
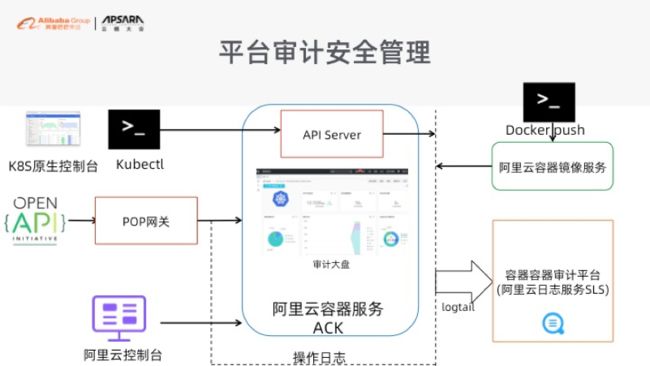
我们把所有能够接触到 K8s 的入口,都做了一层安全审计。除了安全审计落日志的同时,我们还提供了很多预置的安全的审计项来帮助大家做预警。这里举一个例子,就是假如你的 K8s 有安全性的入侵、有人进入你的容器,我们会给大家落审期日志,包括到底是哪个用户用了什么命令进入了哪个容器。同时大家可以去配一个钉钉告警,一分钟内我们会把这个告警给告出来,这样大家就可以知道有人进入你的容器环境了。
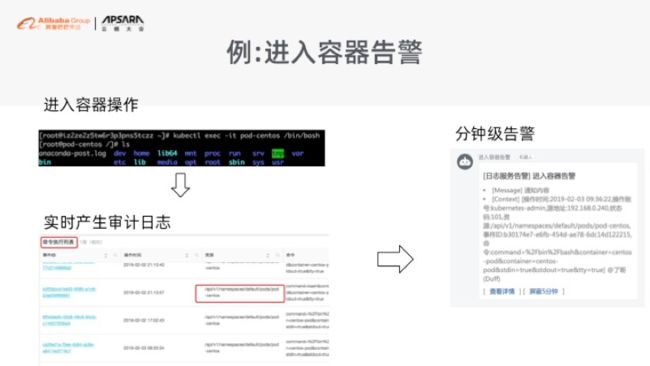
这样确保整个 K8s 环境足够的安全。原则上是这样的,就是大家去用 K8s 的时候,在生产系统里面不应该在有人能够进入容器,所以一定要提醒大家做一点防范。
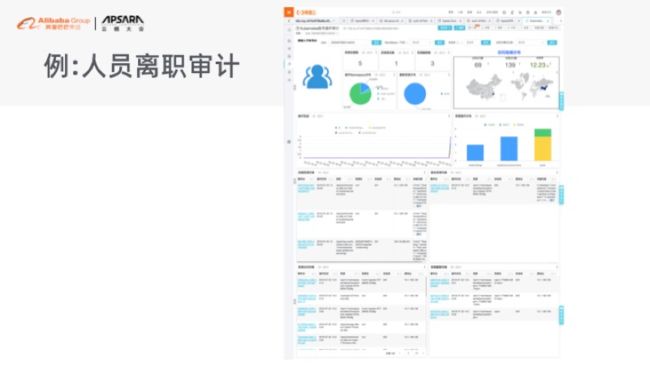
另外一点大家比较难做的地方就是人员的变动。人员变动之后,他这个人对系统在之前的时间内做过什么事情,大家有没有清楚?所以,同样的道理,我们会提供人员审计视图,根据人员子账户进行搜索审计的信息。这样的话,大家对内的安全管控是比较容易去做的,你只需要输入他使用的子账户名字,我们会帮助你把他所有 K8s 的操作都列出来。这样就避免有人偷你的数据到外面去了,而不是两三个月后你还不知道。所以这个是帮助大家去做好人员离职的管控。安全层面上的话,大家务必要把审计日制这个事情看得比较重。
一体化监控体系全链路分析与定位
最后给大家讲一下,我们怎么去做整个监控体系,以及整个链路分析体系。整个监控体系的话,是非常的庞大。因为大家知道,很多同学在 IDC 里面自建 K8s 也好、还是在云上玩也好,只会去考虑 Prometheus 监控架构为主。但实际上,在上完阿里云之后,我们会帮助大家做好整个 K8s 的监控体系以及链路分析。
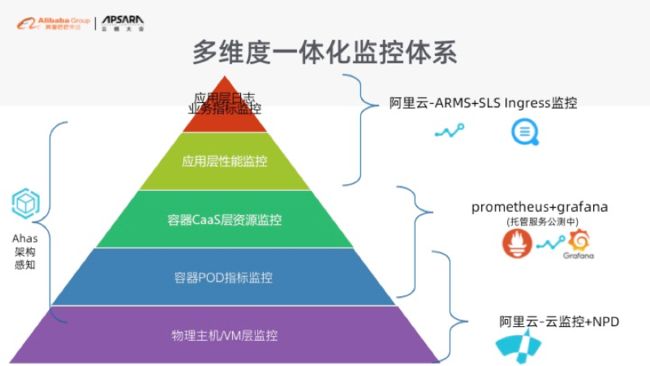
首先是我们从全局的角度来讲,会去给大家展示一下你整个 K8S 层面上,到底有多少个网络单元、有多少个 ECS、有多少个 SLB,然后你机器部署的情况什么样子。
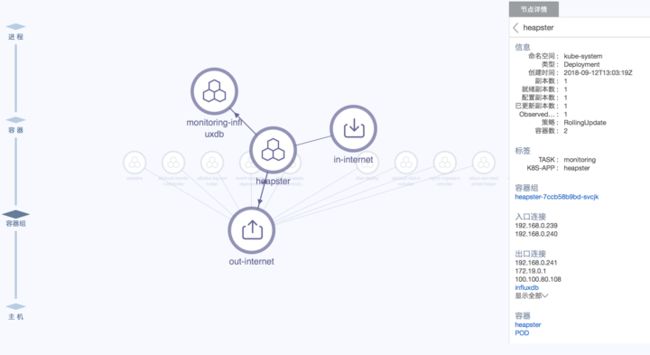
我们底层会依赖于阿里云的云监控,以及刚才说的 NPD 的组件。中间这层还是标准的 Prometheus 架构。但是这里 Prometheus 架构非常耗费资源,所以我们会把它剥离出来作为一个托管的服务来提供,避免大家在集群规模越来越大的时候,Prometheus 会把资源重新吃回去。
顶层的话,我们会给大家提供对应的 ARMS 以及 SLS 的 Ingress Dashboard 的监控。

我们细看一下整个流程应该如上图所示,大家一定要把所有的监控体系,以及链路分析体系构建完整。包括你从前端进来,到 Ingress 入口,然后到中间的 Prometheus,再到应用层的监控 Arms,最后落到代码层面上的执行效率还是错误。大家一定要把这个链路链条构建出来,这样能够帮助大家在出现问题的时候,立马找到问题根源。在互联网体系里面,大家的每一次的问题,解决所带来的时间开销,就是你的成本。

前面刚才提到了,在应用层面的话,我们给大家预置了日志服务 SLS 提供的 Ingress Dashboard。因为大家知道,从 Ingress 是全局的流量入口,大家通常的做法是:都去构建一个庞大的 ELK 系统做监控,这个成本是相当高的。我们会帮助大家只需要落盘到我们的阿里云的 SLS 的服务,就会把全部 Ingress 监控指标构建出来,包括你当天的 PV/UV;包括你现在延迟的情况;包括你上一周以及昨天的同时间的一个 PV/UV 的对比;包括你流量的 TOP 的省份、TOP 的城市;包括你最后错误的以及最高延迟的地方,有 500 错误发生的地方在 URL 是什么。我们把这些东西全部给大家做成一个大的 Dashboard,这样大家可以以成本最低的方式来看你的整个系统的运行情况。同时这个 Dashboard 是支持扩展的,目前这个也是现在上阿里云 ACK 的时候,大家非常喜欢的一个东西。

如果我们要对服务体系做监控的话,可能大家要去考虑怎么接入 APM 系统了。这一部分,我们之前发现很多同学最痛苦的地方在于:很多业务开发的同学其实并不喜欢做接入。因为他去做接入的时候,你要给他一个 jar 包,然后他要在程序里去引入这个 jar 包,重新打镜像才能上线,这个是其中一个繁琐的环节。
另外一个环节就是大家其实最讨厌的地方就是当你的 APM 系统升级的时候,你要求所有的业务人员全部更新换 jar 包,要重新打包镜像、重新上线,业务开发人员就是非常恼火了。所以在容器时代的时候,我们做了一个比较简单以及优雅的方案:我们提供一个应对的 helm 包给大家,做好相应的部署之后,只需要做一个事情:你在发布容器的时候打上两个 Annotation 我们就自动做好 APM 系统(阿里云 Arms)接入了。当你要做升级的时候,只需要把那个应用重新做一次发布,它自动用最新的 jar 包把那个旧包给换掉了。
所以在运维阶段,大家就可以去决定要不要接入 APM 系统,而不需要开发的参与,甚至我们连开发包都不需要给到开发。大家也可以用同样思路,在接入外部系统的时候,思考怎么做到一个无侵入的一个方式。
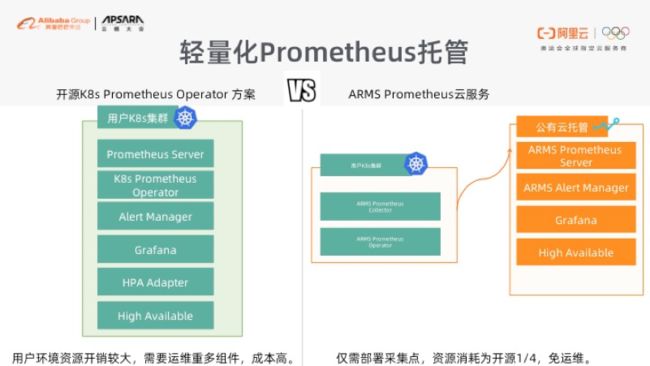
刚才提到了,我们实际上是支持了 Prometheus 的托管。原来大家在 K8s 里面去做 Prometheus 的话,需要构建一堆的组件,而这些组件是非常耗费资源的。所以我们现在的做法就是提供一个 Helm 包给到大家。这样的话,大家只需要简单的一键安装,就可以用到阿里运托管的 Prometheus 服务。然后通过托管的 Grafana 方式去看相应的数据、去做相应的告警。这些都是在后台做了,跟你整个集群没有任何关系,这样你的集群资源是最节约的也是最稳定的。
“ 阿里巴巴云原生微信公众号(ID:Alicloudnative)关注微服务、Serverless、容器、Service Mesh等技术领域、聚焦云原生流行技术趋势、云原生大规模的落地实践,做最懂云原生开发者的技术公众号。”