基于大数据学习在Linux上环境的搭建(持续更新中)
1.准备阶段
虚拟机、CRT/Xshell(终端模拟软件)、WinSCP(两个不同系统之间传输文件)


2. 基础环境搭建
- 创建新的虚拟机
- 自定义
- 安装程序光盘映像文件(iso)(需要网上下载)
- 一直下一步,等待
- 选英文,日期shanghai,系统的网络与主机名,点开查看配置环境需要的信息,在关闭,开始安装
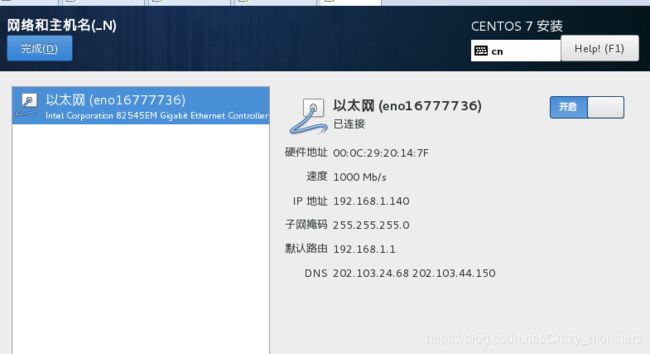
- 安装完成后,重启,输入账号密码

Linux配置网卡
命令:
vi /etc/sysconfig/network-scripts/ifcfg-e按下tab不全命令
如果进入的是一个空文件,命令写错了,直接:q退出
1.刚进入,是一般模式,不能编辑内容
2.按下i进入编辑模式
3.把配置都补充完整
修改:
BOOTPROTO=static
ONBOOT=yes
添加:
IPADDR=192.168.1.xx
NETMASK=255.255.255.0
GATEWAY=192.168.1.1
DNS1=202.103.24.68
DNS2=202.103.44.150
4.按Esc,重新回到一般模式
5.按:进入底部命令行,输入wq,按下回车
6.重启网卡,让配置生效
systemctl restart network
7.ip a
8.ping www.baidu.com
9.ctrl+c停止ping
2.2远程工具链接Linux(CRT/Xshell)
这里选择的是CRT
- 修改主机名为hadoop1。
断开连接重连后,@后面的名字改变。作用:当主机名和ip进行映射的时候就体现了。hostnamectl --static set-hostname hadoop1 - 修改主机名和ip地址的映射:修改/etc/hosts文件,在文件后面添加一行192.168.1.xx hadoop1,
作用:在Linux中,当需要输入ip地址的时候可以用名字代替,当需要修改的时候,只用改一个ip地址就行了(类似于java多态);ex:sshecho /etc/hosts >> 192.168.1.xx hadoop1 - windows上也可以配置主机名和ip的映射 C:\Windows\System32\drivers\etc\hosts文件,作用:在Window到Linux过程中,当需要输入ip地址的时候可以用名字代替;ex:使用CRT时
- 做这些都作用都是为了ssh免密登录,ssh可以远程登录到linux节点,公钥和私钥来配对,验证用户的身份,每个节点都会有一对公钥和私钥
- 每个节点使用命令
ssh-keygen 四下enter,生成自己的公钥和私钥 - 每个节点使用三次命令,对三个节点进行免密登录的配置
ssh-copy-id hadoop1/hadoop2/hadoop3(前提是/etc/hosts文件配置完成)
2.3Linux中java的安装
# 所有主机
# 首先将jdk包上传到/root目录下
cd /root
mkdir /usr/lib/java/
tar zxvf /root/jdk-8u25-linux-x64.tar.gz -C /usr/lib/java/
echo "export JAVA_HOME=/usr/lib/java/jdk1.8.0_25/" >>/etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin/' >>/etc/profile
source /etc/profile
java -version
rm -rf /root/jdk-8u25-linux-x64.tar.gz如果java -version 显示为openjdk,那就卸载掉openjdk
2.4安装MySql
# 在hadoop1上
# 安装mysql
yum -y install mariadb-server mariadb
# 启动并设置开机自启
systemctl start mariadb.service
systemctl enable mariadb.service
# 进入mysql 并设置密码,默认为空
mysql -u root -p2.5安装免密登录
ssh可以远程登录到linux节点
ssh: secure shell
公钥和私钥来配对,验证用户的身份
每个节点都会有一对公钥和私钥
1.每个节点使用命令
ssh-keygen 四下enter,生成自己的公钥和私钥
2.每个节点使用三次命令,对三个节点进行免密登录的配置
ssh-copy-id hadoop1/hadoop2/hadoop3(前提是/etc/hosts文件配置完成)
若是以后又要新加免密登录,只要在新的上面重复上面的步骤
查看免密登录的ip:/root/.ssh/konwn_hosts
2.6安装Hadoop
参考官网http://hadoop.apache.org/docs/r2.7.7/hadoop-project-dist/hadoop-common/SingleCluster.html(但是我觉得对于新手还是很难看懂。。。还是对着官网流程总结一下)
- 三种运行模式
- 本地模式 standalone
不需要启动任何服务,直接使用命令去运行任务 - 伪分布式模式
运行规则和分布式一样,但是只运行在一个节点上 - 分布式模式
Hadoop的分布式运行规则完全执行,运行在多个节点上,每个节点交互
- 本地模式 standalone
- 本地模式 standalone
不需要启动任何服务,直接使用命令去运行任务mkdir input cp etc/hadoop/*.xml input bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input output 'dfs[a-z.]+' cat output/*在hadoop-2.6.0下进行,作用是:分析单词出现的次数
-
伪分布式模式
运行规则和分布式一样,但是只运行在一个节点上
第一个要在配置文件core-site.xml里面加上下面的[root@hadoop1 hadoop]# pwd /opt/programs/hadoop-2.6.0/etc/hadoop [root@hadoop1 hadoop]# vi core-site.xml第二个要在配置文件hdfs-site.xml加上下面的代码
[root@hadoop1 hadoop]# vi hdfs-site.xml在格式化文件系统:
bin / hdfs namenode -format 启动服务 namenode:组长,hdfs的主节点 datanode:小弟,提供保存数据服务的节点 sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode jps看一下守护进程 namenode datanode 使用webUI查看服务状态 直接用浏览器访问地址 hadoop1:50070
分布式模式
Hadoop的分布式运行规则完全执行,运行在多个节点上,每个节点交互
以3个为例;hadoop1、hadoop2、hadoop3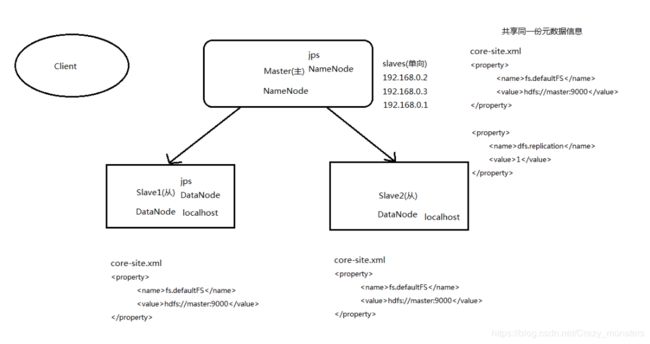
上图就是分布式的思路
把主节点的
[root@hadoop1 hadoop]# pwd
/opt/programs/hadoop-2.6.0/etc/hadoop/slaves加上2个从节点(DataNode)的ip就可以了,从节点加上自己的ip,一般在运用中是把所有的ip都写上去
[root@hadoop1 hadoop]# cat slaves
hadoop1
hadoop2
hadoop3hdfs-site.xml中的配置
dfs.replication
3
hadoop.tmp.dir
/opt/programs/hadoop-2.6.0/data/tmp
dfs.namenode.secondary.http-address
hadoop3:50090
core-site.xml中的配置
fs.defaultFS
hdfs://hadoop1:9000
yarn-site.xml中的配置
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop2
yarn.log-aggregation-enable
ture
yarn.log-aggregation.retain-seconds
604800
mapred-site.xml中的配置
因为这个配置项系统只自带一个mapred-site.xml.template,里面写东西是无效的,所以要复制一个mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.webapp.address
hadoop3:19888
2.7配置Hadoop-HA
2.7.1.hdfs-site.xml
dfs.nameservices
ns1
dfs.ha.namenodes.ns1
nn1,nn2
dfs.namenode.rpc-address.ns1.nn1
hadoop1:9000
dfs.namenode.rpc-address.ns1.nn2
hadoop3:9000
dfs.namenode.http-address.ns1.nn1
hadoop1:50070
dfs.namenode.http-address.ns1.nn2
hadoop3:50070
dfs.namenode.shared.edits.dir
qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/ns1
dfs.journalnode.edits.dir
/opt/programs/hadoop-2.6.0/data/tmp/dfs/jn
dfs.client.failover.proxy.provider.ns1
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
2.7.2.core-site.xml
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
fs.defaultFS
hdfs://ns1
2.7.3.安装必要的组件
yum -y install psmisc
psmisc包含fuser,killall,pstree三个程序,且出现上述问题是由于我们在安装centos7的时候选择了最小化安装,默认是不安装psmics。
fuser 显示使用指定文件或者文件系统的进程的PID。
killall 杀死某个名字的进程,它向运行指定命令的所有进程发出信号。
pstree 树型显示当前运行的进程。2.7.4.启动集群的方式
1.启动所有的journalnode
sbin/hadoop-daemon.sh start journalnode
2.nn1格式化并启动
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
3.在nn2上,同步nn1的元数据信息
bin/hdfs namenode -bootstrapStandby
4.启动nn2
sbin/hadoop-daemon.sh start namenode
5.启动datanode节点
sbin/hadoop-daemon.sh start datanode
6.把节点设置为active
bin/hdfs haadmin -transitionToActive nn12.7.5自动故障转移
hdfs-site.xml:
打开自动故障转移
dfs.ha.automatic-failover.enabled
true
core-site.xml:
添加zookeeper的服务
ha.zookeeper.quorum
hadoop1:2181,hadoop2:2181,hadoop3:2181
2.7.6zookeeper安装
单机模式:
修改conf/zoo.cfg下的datadir即可,表示的是存放数据的路径。
datadir=/opt/programs/zookeeper-3.4.12/data/zkData
启动
bin/zkServer.sh start
出现进程名为QuorumPeerMain即启动成功
bin/zkServer.sh status,此时查看状态为standalone
停止服务:bin/zkServer.sh stop
集群模式:
1.配置文件需要自己增加集群选项
表明集群有几台机器,并且指定和leader的端口号和参与投票的端口号
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
2.在每个节点上创建文件,表明本节点的编号,要和配置文件里面对应
在data/zkData下创建文件myid,里面表明自己是哪个编号即可
touch myid
3.传输到别的节点上,并修改myid为对应的编号
启动:
只能每个节点单独启动脚本
bin/zkServer.sh start
每个节点启动了之后,可以查看各节点的角色
bin/zkServer.sh status2.7.7启动集群
1.关闭所有hdfs服务,同步修改的文件
2.启动zookeeper集群
3.初始化HA在zookeeper中的状态
bin/hdfs zkfc -formatZK -force
4.启动hdfs服务
如果直接一起启动出现通信错误,造成namenode停止,则需要先启动journalnode,再启动其他
//启动zkfc,先在哪台节点启动zkfc,那么哪台就是active
sbin/hadoop-daemon.sh start zkfc2.8HBase环境配置
1.前提:zookeeper配置完成
2.正常解压
3.环境配置
hbase-site.xml 文件
hbase.rootdir
hdfs://hadoop1:9000/hbase
hbase.cluster.distributed
true
hbase.master.info.port
16010
hbase.regionserver.info.port
16030
hbase.zookeeper.quorum
hadoop1,hadoop2,hadoop3
hbase.coprocessor.abortonerror
false
配置hbase-env.sh
export JAVA_HOME=/usr/lib/java/jdk1.8.0_25
export HBASE_CLASSPATH=/opt/programs/hadoop-2.6.0/etc/hadoop
export HBASE_MANAGES_ZK=false
export TZ="Asia/Shanghai"配置regionservers
salve的ip
hadoop2
hadoop34.启动
start-hbase.shhbase shell进入
2.9Flume的环境配置
1.下载Flume的tar包下载地址,上传解压
2.环境配置
进入conf,复制flume-env.sh.template为flume-env.sh,进入flume-env.sh,添加JAVA_HOME的地址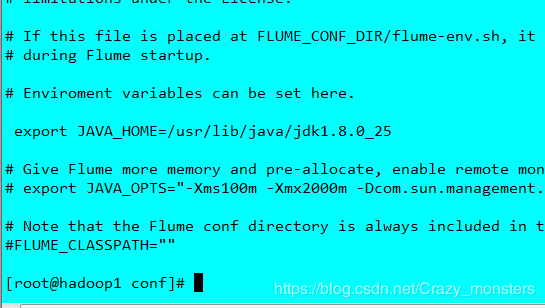
3.添加环境变量
vi /etc/profile
根据安装目录添加,添加完成后source
可以通过flume-ng version查看flume的版本信息
4.Flume的使用
conf目录下创建.conf文件
启动命令:flume-ng agent --conf conf --name a1 --conf-file avro.conf &(最好写绝对路径)
2.10.KAFKA的环境配置
1.下载tar包,上传解压
2.环境变量配置
vi /etc/profile
3.环境配置
config下的server.properties
//(1)、配置 broker 的ID
broker.id=1 //第一个kafka配置为 1,第二个配置为2,以此类推
//(2)、打开监听端口
listeners=PLAINTEXT://192.168.195.132:9092 //尽量写ip地址,以免造成错误
//(3)、修改 log 的目录、在指定的位置创建好文件夹logs
log.dirs=/usr/local/kafka/logs
//(4)、修改 zookeeper.connect
尽量写ip地址,以免造成错误
zookeeper.connect=master:2181,slave1:2181,slave2:2181,slave3:2181
//(5)、网络线程数量
num.network.threads=3
//(6)Zookeeper每6秒监视kafka是否还活着
zookeeper.connection.timeout.ms=6000 //(默认)
4.执行的命令
启动:kafka-server-start.sh $KAFKA_HOME/config/server.properties &
创建topic:kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
查看topic:kafka-topics.sh --list -zookeeper hadoop1:2181
生产者身份进行广播:kafka-console-producer.sh --broker-list 192.168.195.132:9092 --topic test
顾客身份进行访问:/kafka-console-consumer.sh --zookeeper 192.168.2.11:2181 --from-beginning --topic test
3.基础环境以外的一些重要的配置
3.1NTP的搭建
3.1.1什么是NTP?
NTP是网络时间协议,它是用来同步网络中各个计算机的时间的协议。采用C/S架构。
3.1.2NTP的搭建
-
直接yum下载yum -y install ntp - 修改主机配置
vi /etc/ntp.conf把如下四行代码注释掉
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst在下面再添加一行
server 127.127.1.0 iburst
启动ntp服务
systemctl start ntpd
开机自启
systemctl enable ntpd -
配置其他主机
vi /etc/ntp.conf#注释掉其他上游时间服务器
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
#配置上游时间服务器为本地的ntpd Server服务器
server 192.168.1.80
#配置允许上游时间服务器主动修改本机的时间
restrict 192.168.1.80 nomodify notrap noquery -
与本地ntpd Server同步一下
ntpdate -u 192.168.0.163
systemctl start ntpd
3.2计划任务
3.2.1计划任务安装
yum -y install crontabs3.2.2配置
vi /etc/crontab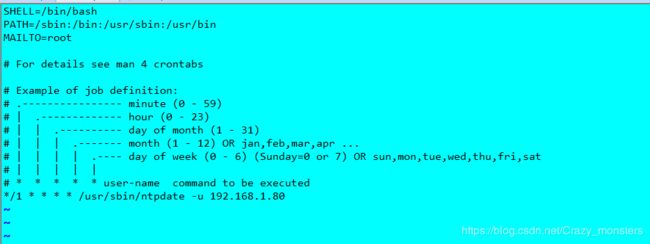
systemctl enable crond (设为开机启动)
systemctl start crond(启动crond服务)
systemctl status crond (查看状态)
crontab /etc/crontab 使的配置文件生效