AutoML很火,过度吹捧的结果?
作者 | Denis Vorotyntsev
译者 | Shawnice
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导语】现在,很多企业都很关注AutoML领域,很多开发者也开始接触和从事AutoML相关的研究与应用工作,作者也是,在工作、比赛、调和主模型时都使用过AutoML。作者表示:“AutoML是一个出色的自动化建模工具,但我认为它的作用和价值现在被夸大了。在一些关键概念中,比如特征工程或用于超参数优化的元学习,AutoML的表现确实很有潜力,但目前购买集成AutoML只是浪费金钱”。广受关注的AUtoML究竟是否被过渡夸赞了呢?下面这篇文章和大家一起探讨。
什么是AutoML?
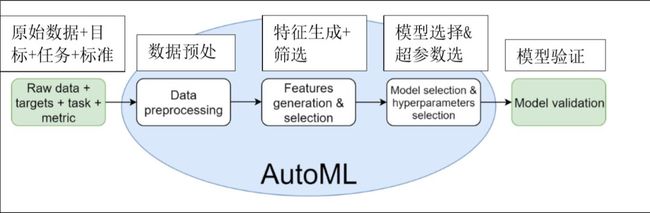
深入AutoML前,我们要先从一个数据科学项目的工作流讲起。
-
数据科学项目
任何数据科学项目都包含下面这4个基本步骤:
1. 根据业务进行问题分析(立项和项目成功的度量标准),
2. 收集数据(收集、清洗、分析探索),
3. 构建模型并评估其性能,
4. 在实际工程中部署模型并观察模型的表现

跨行业的数据挖掘标准流程
这个过程中的每一个步骤都项目是否成功起着至关重要的作用。然而,内行人会认为建模是最关键的部分,一个完善的ML模型能给企业带来很多价值。
数据科学家在建模阶段要进行优化任务:在给定的数据集和规定的指标下,最优化目标,然而实际上这个过程是非常复杂的,需要具备多项技能。作者分享了三个重要的观点:(1)特征工程不仅是一门科学,更是一门艺术;(2)超参数优化需要对算法和机器学习的核心概念有深刻的理解;(3)同时也需要软件工程师的技能让代码通俗易懂、易于部署。
而AutoML就是希望在这些方面能给开发者和数据科学家们提供帮助。
AutoML
AutoML输入的是数据和任务(分类,回归,推荐等),输出是可用于应用的模型,该模型能够预测未知数据。数据驱动流程中的每个决定都是一个超参数。AutoML的基本想法就是在相对短的时间里找到这样优质的超参数。
(1)AutoML选择了一种预处理数据的策略:如何处理不平衡的数据、如何填充缺失值、删除,替换或保留异常值、如何对类别和多类别列进行编码、如何避免目标泄漏、如何防止内存错误…等
(2)AutoML会生成新特征并选择其中有意义的
(3)AutoML可以选择模型(线性模型、K近邻法、梯度增强、神经网络…等)
(4)AutoML调整所选模型的超参数(例如,基于树的模型或体系结构的树数和子采样、神经网络的学习率和时期数)
(5)AutoML可以对模型进行稳定的集成以增加得分
AutoML的契机
AutoML将填补数据科学市场中“供应”与“需求”之间的空缺
如今,越来越多的公司开始收集数据或者至少意识到收集数据的重要性:他们都希望从中分一杯羹。另一方面,市场上缺乏拥有适当背景知识的数据科学家来满足需求,因此出现了人才缺口。AutoML可能会填补这一空缺。
但这个解决方案能给公司带来什么价值吗?在我看来答案是否定的。
很多公司需要的是一个“过程”,而AutoML提供的只是一个“工具”。先进的工具无法弥补战略上的不足。在使用AutoML前,或许可以考虑与咨询公司进行项目合作,这可以帮助公司首先完善数据科学战略。大多数AutoML解决方案提供商也提供咨询业务这一现象,并不是一个巧合。
-
AutoML可帮助数据科学小组节省时间
根据2018年Kaggle机器学习和数据科学调查,典型的数据科学项目中,大家有15-26%的时间都用于构建模型或模型选择。无论是工时本身还是时间成本,这都是一项艰巨的任务。如果目标或数据改变(如加入新特征),这个过程又要重复一遍。AutoML可以帮助公司或数据科学家节省很多时间,将更多的时间花在更有意义的事情上。
但是,如果建模环节不是数据科学团队最关键的任务,说明公司流程中存在非常明显的问题。通常,即使模型性能只提升了小小一点,公司也有可能为此赚取大量利益,在这种情况下耗费大量时间建造模型是没有意义的。
简单来说:
如果(从模型中的收益 > 数据科学小组花费的时间)= 不需要节省时间
如果(从模型中的收益 <= 数据科学小组花费的时间)= 你真的解决了问题吗?
为数据小组每天都必须做的任务编写脚本是一个很好节约时间的方法。我就为日常任务写了几个自动化脚本:自动生成特征、选择特征、模型训练和超参数调整,这些都是我每天必做的事项。
AutoML胜过普通数据科学家
不幸的是,除了“开源AutoML基准测试”之外,我们没有什么有效的基准。下面的基准测试是于2019年7月1日发布的,作者将几个AutoML库的性能与调整后的随机森林进行比对。
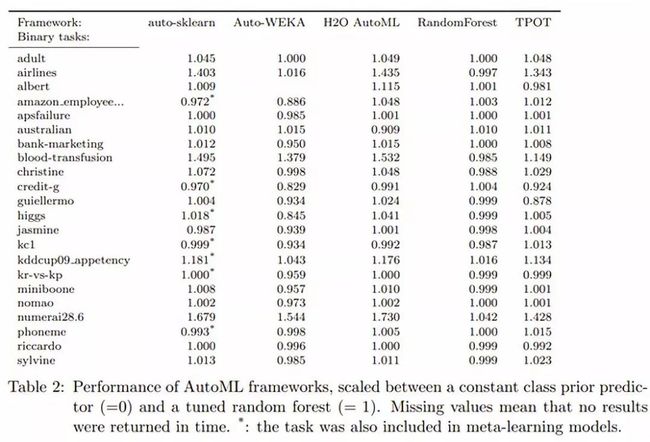
看到这个结果也吸引了我的好奇,我决定自己建立一个基准测试。我将自己做的性能表现与AutoML解决方案在二进制分类的三个数据集上的性能进行了对比:credit、KDD unspelling 和 mortgages。我把数据集区分成了训练集(占比60%)和测试集(占比40%)。
下面是我的基准解决方案,其实很简单,我没有深入挖掘数据也没有创建什么高级特征:
1. 5-分层 KFold
2. 用于分类列的 Catboost 编码器
3. 数学运算(+-*/),新特征限制在500
4. 模型:LightGBM,默认参数
5. 混合OOF
使用了两个标准库:H2O和TPOT。
按照几个时间间隔进行训练:从15分钟开始到6个小时。用以下基准,我得到了令人惊讶的结果:
Score = (ROC AUC / ROC AUC of my baseline) * 100%
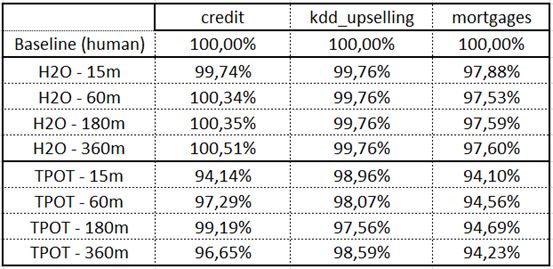
首先,在几乎所有情况下,我的基准都超过了AutoML。这让我有点伤心,因为我以为以后我能用AutoML来代替我完成工作,我就能休闲一下了。
其次,AutoML的得分并没有随着时间增涨。也就是说,不论我们等15分钟还是6个小时,AutoML的得分都一样低。
AutoML与高分无关。
总结
从企业技术应用与实践工程研发角度出发,作者总结了下面三点:
1. 如果你的公司是第一次处理数据,考虑雇佣一名顾问吧
2. 尽量让工作自动化
3. 从分数看,集成式解决方案并不是个好选择
PS:引擎不是车
经过这些思考,作者通过这个例子与大家共勉,希望大家在关注热门、新技术的同时,不忘从大局出发,对整体更要有了解和把控。
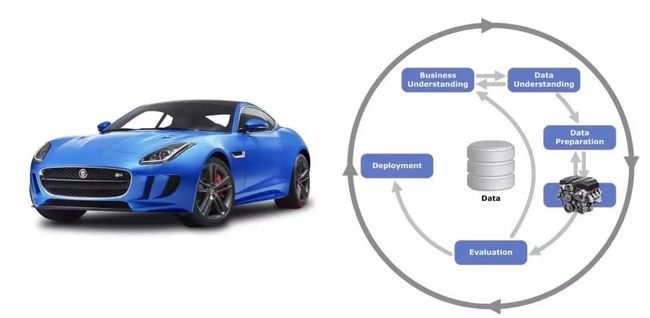
在之前的篇幅中,作者和大家一直在讨论 AutoML 工具,到这里他也提示大家,建模只是整个数据科学项目流程中的一小部分,如果把项目比作一辆车,建模(机器学习模型)输出就是一个引擎。毋庸置疑,引擎是一辆车最重要的部分,但引擎并不是一个完整的车。你可能花费了大量时间来设计完善又复杂的功能、选择神经网络或调整随机森林的参数来创造一个强大的引擎,但是如果忽略了车的其他部分组件,也是白费力。
可能模型本身性能已经非常好,但由于我们解决的问题不对(业务理解偏差)、数据偏见(这就需要重新探索数据了)、或者模型结构太复杂,你花费心思做的模型并不能投入生产,部署到产品线中。
最后就发现自己很傻,就像在经过数天或数周的艰难建模工作之后,你只是在骑一辆篮子里放着跑车引擎的自行车。
原文链接:https://towardsdatascience.com/automl-is-overhyped-1b5511ded65f
(*本文为 AI科技大本营编译文章,
转
载请微
信联系 1092722531
)
◆
精彩推荐
◆
2019 中国大数据技术大会(BDTC)再度来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。
即日起,
限量 5 折票
开售,数量有限,扫码购买,先到先得!

推荐阅读
网红“AI大佬”被爆论文剽窃,Jeff Dean都看不下去了
AI大佬“互怼”:Bengio和Gary Marcus隔空对谈深度学习发展现状
有了这套模板,再不担心刷不动LeetCode了
Google图嵌入工业界最新大招,高效解决训练大规模深度图卷积神经网络问题
太鸡冻了!我用Python偷偷查到暗恋女生的名字
苹果 5G 芯片“难产”
【角度刁钻】如果把线程当作一个人来对待,秒懂
C 语言这么厉害,它自身是用什么语言写的?
一文了解超级账本DLT、库、开发工具有哪些, Hyperledger家族成员你认识几个?
你点的每个“在看”,我都认真当成了AI