如何使用Python模拟MySQL Slave,可以看看这个开源项目
这是学习笔记的第 2140 篇文章

在MySQL中通过Master向Slave推送binlog数据变化,从而实现主从复制的过程,是一件看似再正常不过的事情了。整个过程可以使用如下的流程图来表示。

毕竟这是MySQL体系内的实现,如果想要在这个基础上扩展,比如实现异构数据的流转,复制,或者情况糟糕一些,多个跨地域的MySQL之间要实现异步数据复制,这个时候原生的主从场景就会受到限制了。
如果要实现这种特殊的复制,需要具备两点,第一是可以正常连接到MySQL,并且具有Slave应该拥有的权限,第二是按照MySQL协议发送相关的数据包,让MySQL服务能够识别你是一个“Slave”,这样如果发生了数据变化,Master就可以源源不断的推送数据变化的信息过来。
在技术方向上已经有了很多的产品和组件,比如阿里的canal,Zendesk的Maxwell, Yelp的MySQLStreamer等,都可以模拟MySQL协议,在行业内也有一些实现场景,在特性完善方面各有差异。
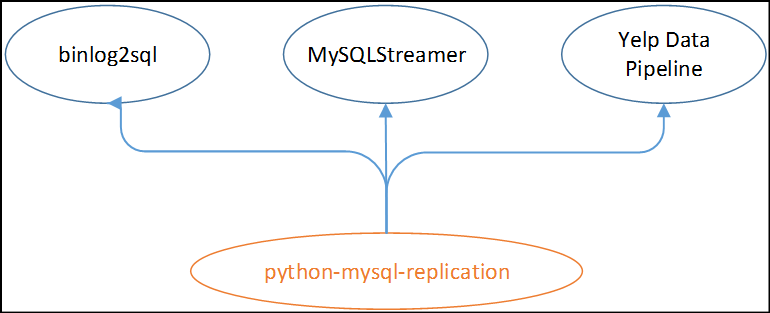
最近也做数据多活的一些方案调研,发现mysql-python-replication是一个很不错的开源项目,它和行业内知名的一些开源项目都有渊源,实现了底层的协议数据解析。
我们接下来看看mysql-python-replication的源码实现,做一些简单的解读。
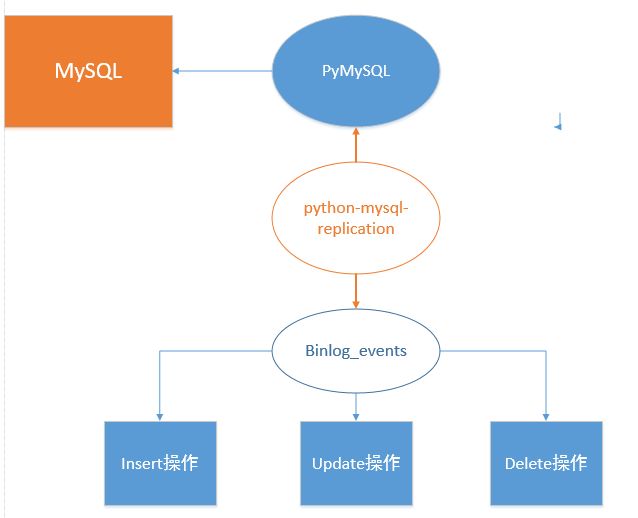
首先mysql-python-replication的整体实现思路如下,它其实是基于PyMySQL来连接MySQL,然后来模拟协议层的数据包,得到Master推送的数据之后,按照Binlog中的event类型解析为Insert,delete,update(分别对应insert,delete,update事件),当然Binlog中实际的事件要远远比这个多。
mysql-python-replication的源码很容易得到,在GitHub上搜索mysql-python-replication即可。
得到的源码结果如下,代码量其实远比想象的要少一些。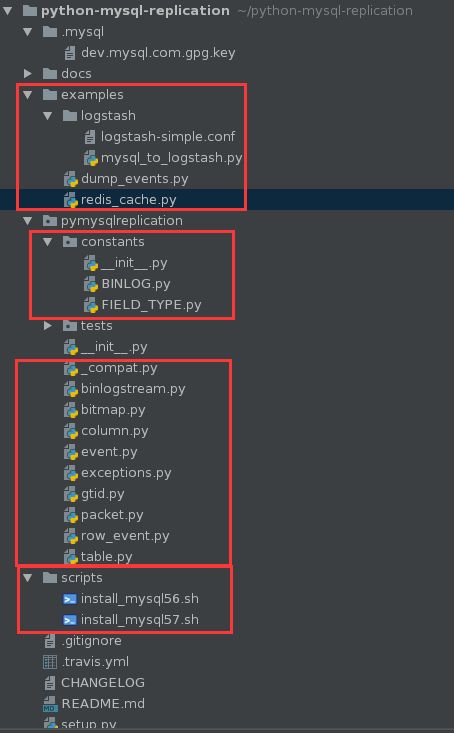
最后竟然还很贴心的给出了MySQL 5.6,5.7的安装部署脚本,在examples目录下提供了几个案例,我们今天要分析的主要是基于dump_events.py这个文件,它可以实现模拟Slave的整个过程。
整个实例程序很短,内容如下:
from pymysqlreplication import BinLogStreamReader
MYSQL_SETTINGS = {
"host": "127.0.0.1",
"port": 3306,
"user": "root",
"passwd": "xxxx"
}
def main():
# server_id is your slave identifier, it should be unique.
# set blocking to True if you want to block and wait for the next event at
# the end of the stream
stream = BinLogStreamReader(connection_settings=MYSQL_SETTINGS,
server_id=3,
blocking=True)
for binlogevent in stream:
binlogevent.dump()
stream.close()
if __name__ == "__main__":
main()
示例的Main方法内其实逻辑相对是比较简单的,初始化BinLogStreamReader对象,然后解析出event的信息。
这里的dump主要是基于BinLogEvent和RotateEvent,其他的大都是PyMySQL底层的实现了。
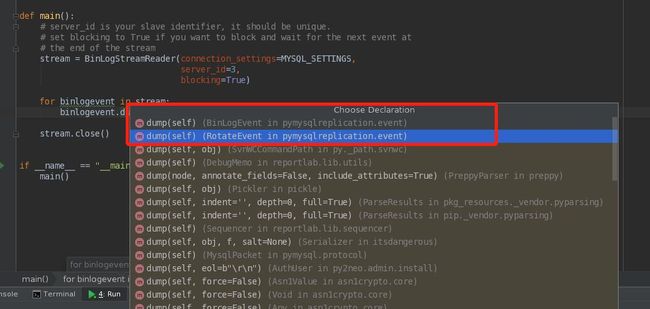
其实按照这个思路我们是很难读懂代码的,只能做一些基本的代码熟悉,一方面我们要不断的调试理解,另一方面我们需要抓住重点。
重点是什么呢, 其实就是模拟Slave的原理,我来具体解释一下。
MySQL Master向Slave推送数据,都是按照基础的协议来完成,就好比我们工作中常用的专业术语,在外行来看就是高深莫测的东西。在这里MySQL是定义了两个命令:COM_REGISTER_SLAVE和COM_BINLOG_DUMP,前者用于注册Slave,后者通知mysqld从指定binlog pos发送event。
如下是一个调试过程中得到的MySQL线程情况,可以看到相应的Binlog Dump线程,其实这个数据库是没有Slave的。

当然python-mysql-replication代码后端也会去information_schema中取一些元数据(其实主要是字段相关的元数据信息)。
我们在BinLogStreamReader中可以看到很多方法,其实是有关联调用的,其中目前我最关注的方法是register_slave
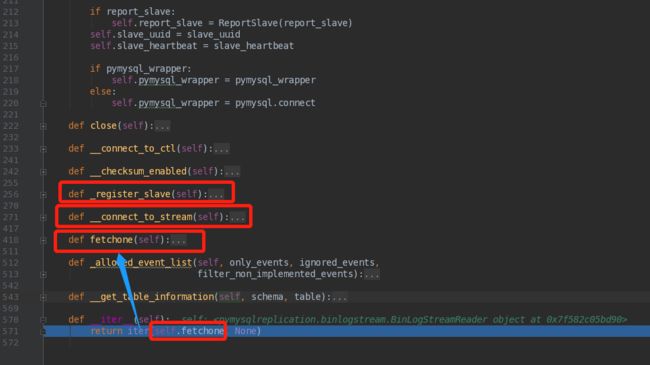
def _register_slave(self):
if not self.report_slave:
return
packet = self.report_slave.encoded(self.__server_id)
if pymysql.__version__ < "0.6":
self._stream_connection.wfile.write(packet)
self._stream_connection.wfile.flush()
self._stream_connection.read_packet()
else:
self._stream_connection._write_bytes(packet)
self._stream_connection._next_seq_id = 1
self._stream_connection._read_packet()
return (struct.pack('如果条件为:if not self.auto_position:即为偏移量同步模式,
后续发送COM_BINLOG_DUMP的实现逻辑为:
prelude = struct.pack('否则注册的是GTID相关的binlog_dump
gtid_set = GtidSet(self.auto_position)
encoded_data_size = gtid_set.encoded_length
header_size = (2 + # binlog_flags
4 + # server_id
4 + # binlog_name_info_size
4 + # empty binlog name
8 + # binlog_pos_info_size
4) # encoded_data_size
prelude = b'' + struct.pack('而这个过程中也会通过PyMySQL连接到数据库中,得到字段相关的一些信息。
SQL为:
SELECT
COLUMN_NAME, COLLATION_NAME, CHARACTER_SET_NAME,
COLUMN_COMMENT, COLUMN_TYPE, COLUMN_KEY, ORDINAL_POSITION
FROM
information_schema.columns
WHERE table_schema = %s AND table_name = %s
ORDER BY ORDINAL_POSITION通过代码调试可以看到这些明细的信息。

当然看到这里我们可能还是一知半解,不知道这个程序运行结果是怎么样的。我们来跑一个demo看看。
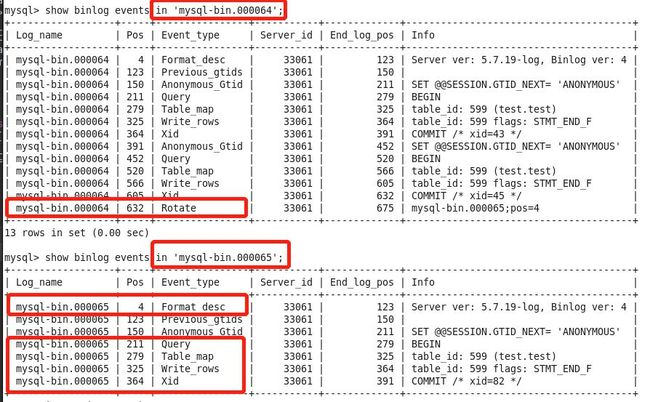
首先刷新下日志,对表test写入一行数据,看看解析的效果怎么样。
mysql> flush logs;
mysql> insert into test values(3,'cc');
Query OK, 1 row affected (0.07 sec)
mysql> show binary logs;
| mysql-bin.000064 | 675 |
| mysql-bin.000065 | 391 |
+------------------+-----------+
65 rows in set (0.00 sec)
在后端输出的日志内容为:
=== RotateEvent ===
Position: 4
Next binlog file: mysql-bin.000065
()
=== RotateEvent ===
Position: 4
Next binlog file: mysql-bin.000065
()
=== FormatDescriptionEvent ===
Date: 2019-10-23T10:51:41
Log position: 123
Event size: 100
Read bytes: 0
()
=== QueryEvent ===
Date: 2019-10-23T10:51:55
Log position: 279
Event size: 49
Read bytes: 49
Schema: test
Execution time: 0
Query: BEGIN
()
=== TableMapEvent ===
Date: 2019-10-23T10:51:55
Log position: 325
Event size: 27
Read bytes: 26
Table id: 599
Schema: test
Table: test
Columns: 2
()
=== WriteRowsEvent ===
Date: 2019-10-23T10:51:55
Log position: 364
Event size: 20
Read bytes: 12
Table: test.test
Affected columns: 2
Changed rows: 1
Values:
--
('*', u'id', ':', 3)
('*', u'name', ':', u'cc')
()
=== XidEvent ===
Date: 2019-10-23T10:51:55
Log position: 391
Event size: 8
Read bytes: 8
Transaction ID: 82
()
mysql> show slave hosts;
Empty set (0.00 sec)可以看到解析出了多个event,我们把binlog里面的事件和输出比对,会发现这些事件是匹配的。因为flush logs对最后的binlog做了切换,所以有Rotate相关事件。
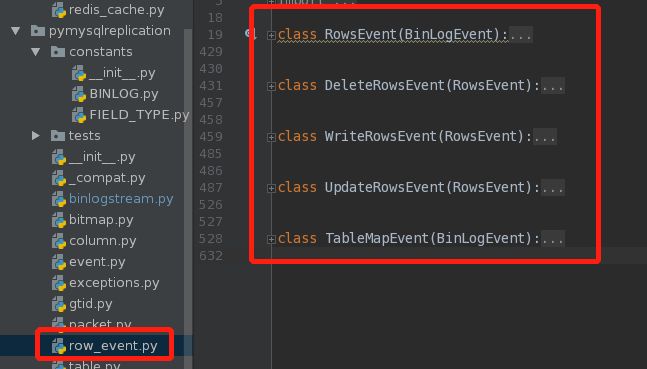
后续解析的内容是比较常规的部分。在代码中增删改的相关event主要放在了row_event.py中,而范围更大的一些事件在event.py里面。
近期热文:
个人新书 《MySQL DBA工作笔记》
个人公众号:jianrong-notes
QQ群号:763628645
QQ群二维码如下,个人微信号:jeanron100, 添加请注明:姓名+地区+职位,否则不予通过