Kubernetes核心组件解析

众所周知,Kubernetes是目前最为火热的容器编排工具之一,其背后有如此多的追随者必然是有原因的。首先Kubernetes非常轻量,通常Kubernetes都是以容器作为载体,而容器本来就具有轻量级秒级部署的特点;再者Kubernetes有火热的开源社区,自从Kubernetes加入CNCF(Cloud Native Computing Foundation,云原生计算基金会)后,来自世界各地的许多容器开发者参与其中,其中不乏有像Redhat、IBM、华为等大厂的开发人员,因此良好的生态圈成为了最受关注的原因之一。
在Kubernetes中部署应用是一件容易的事,因其有着弹性伸缩,横向扩展的优势并同时提供负载均衡能力以及良好的自愈性(自动部署、自动重启、自动复制、自动扩展等),那么这些Kubernetes的优势在集群中又是如何被体现出来的呢?
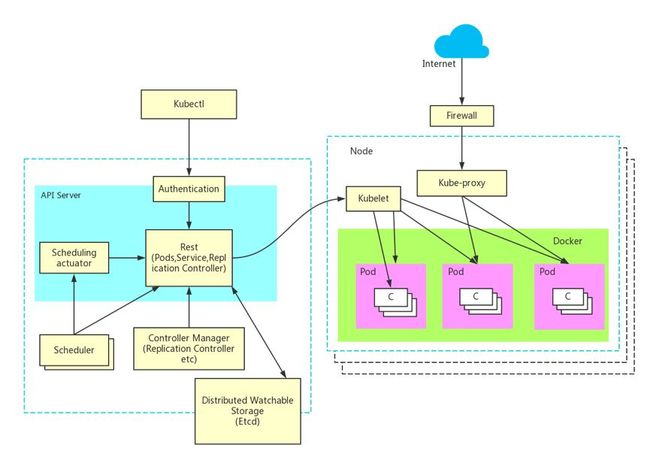
Kubernetes的架构分为Master和Node两部分,如图1所示。由上图可以看出这两部分由五种主要的组件构成,它们之间协同工作从而完成整个集群的管理,这五种组件分别为API Server、Controller Manager、Scheduler、Kubelet、etcd。本文主要从一个简单的Pod工作流出发,涉及到架构中的组件并深入讲解其工作机制,下面先简单介绍下Kubernetes中组件和资源对象的基本概念。
Pod:Kubernetes中运行应用或服务的最小单元,其设计理念是支持多个容器在一个Pod中共享网络地址和文件系统
Service:访问Pod的代理抽象服务,主要用于集群内部的服务发现和负载均衡
Replication Controller:用于伸缩Pod副本数量的组件
API Server:对以上1、2、3资源对象进行增、删、改、查的Rest API服务器
Scheduler:集群中资源对象的调度控制器
Controller Manager:负责集群中资源对象管理同步的组件
etcd:分布式键值对(k,v)存储服务,存储整个集群的状态信息
Kubelet:负责维护Pod容器的生命周期
Label:用于Service及Replication Controller 与Pod关联的标签
(1)提交请求:用户通常提交一个yaml文件,向API Server发送请求创建一个Pod, yaml文件含有此Pod的详细信息,包含此Pod运行副本数、镜像、Labels、名称,端口暴露情况等。API Server接收到请求后将yaml文件中的spec数据存入etcd中;
(2)资源状态同步:这一步涉及到Replication组件,Replication组件监控着数据库中的数据变化,对已有的Pod进行数量上的同步;
(3)资源分配:Scheduler会检查Etcd数据库中记录的没有被分配的Pod,将此类Pod分配至具有运行能力的Node节点中,并更新Etcd数据库中的Pod分配情况;
(4)新建容器:kubernetes集群节点中的Kubelet对Etcd数据库中的Pod部署状态进行同步,目标Node节点上的Kubelet将Pod相关yaml文件中的spec数据递给后面的容器运行时引擎(如Docker等),后者负责Pod容器的运行停止和更新;Kubelet会通过容器运行时引擎获取Pod的状态并将信息更新至API Server,最后写入etcd中;
(5)节点通讯:Kube-proxy负责各节点中Pod的网络通信,包括服务发现和负载均衡。
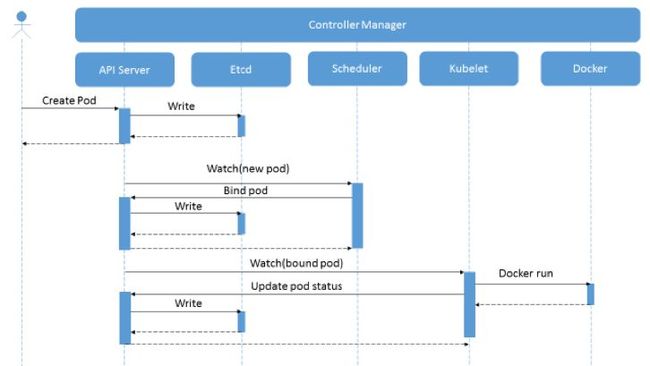
从以上Kubernetes工作流可看出,从客户端发送创建Pod请求到Pod最终部署至节点期间参与的主要组件有API Server、 Controller-Manager、 Scheduler、 Kubelet、etcd。
etcd组件在整个Pod工作流中主要为其它四个组件提供组件状态存储,不多做解释。下面将分别对其它四个组件的工作机制予以具体说明。
一、API Server
![]()
为整个Pod工作流提供了资源对象(Pod,Deployment,Service等)的增删改查以及用于集群管理的Rest API接口,集群管理主要包括认证授权,集群状态管理和数据校验等。
提供集群中各组件的通信以及交互的功能。
提供资源配额控制入口功能。
安全的访问控制机制。
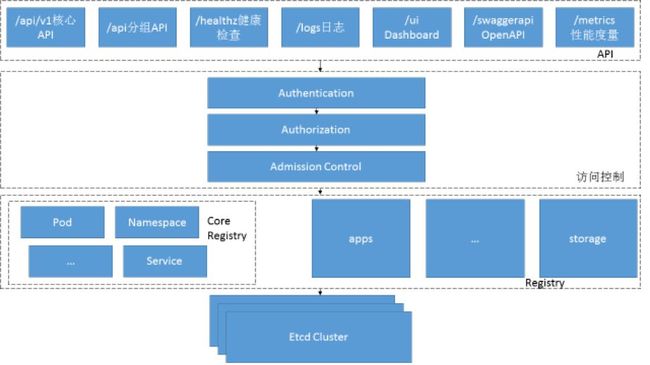
在Kubernetes集群中,API Server运行在Master节点上,默认开放两个端口,分别为本地端口8080(非认证或授权的http请求通过该端口访问API Server)和安全端口6443( 该端口用于接收https请求并且用于token文件或客户端证书及HTTP Basic的认证同时用于基于策略的授权),Kubernetes中默认为不启动https安全访问控制。
集群组件间通信
API Server在整个Pod工作流中主要负责各个组件间的通信,Scheduler,Controller Manager,Kubelet通过API Server将资源对象信息存入etcd中,当各组件需要这些数据时又通过API Server的Rest接口来实现信息交互,以下分别说明:
1、Kubelet与API Server
在Pod工作流中,位于集群中每个Node节点上的Kubelet会定期调用API Server的Rest接口去告知当前自身状态,API Sever接收到状态信息后,将其更新至etcd中,Kubelet也同时通过API Server的Watch接口去监听Pod信息,从而对各个Node节点上的Pod进行管理,主要监听信息如表1所示:
监听信息 |
Kubelet 执行 |
是否有新的Pod被绑定到Node节点 |
执行Pod对应容器的创建和启动 |
是否有Pod对象被删除 |
删除Node上相应Pod容器 |
是否有修改Pod信息 |
修改Node上Pod的信息 |
2、kube-controller-manager与API Server
Controller Manager包含许多控制器,例如Endpoint Controller、Replication Controller、Service Account Controller等, 具体会在后面Controller Manager部分说明,这些控制器通过API Server提供的接口去实时监控当前Kubernetes集群中每个资源对象的状态变化并将最新的信息保存在etcd中,当集群中发生各种故障导致系统发生变化时,各个控制器会从etcd中获取资源对象信息并尝试将系统状态修复至理想状态。
3、kube-scheduler与API Server
Scheduler通过API Server的Watch接口监听Master节点新建的Pod副本信息并检索所有符合该Pod要求的Node列表同时执行调度逻辑,成功后将Pod绑定在目标节点处。
由于在集群中各组件频繁对API Server进行访问,各组件采用了缓存机制来缓解请求量,各组件定时从API Server获取资源对象信息并将其保存在本地缓存中,所以组件大部分时间是通过访问缓存数据来获得信息的。
![]()
Controller Manager在Pod工作流中起着管理和控制整个集群的作用,主要对资源对象进行管理,当Node节点中运行的Pod对象或是Node自身发生意外或故障时,Controller Manager会及时发现并处理,以确保整个集群处于理想工作状态。
Controller Manager组成如图4所示:
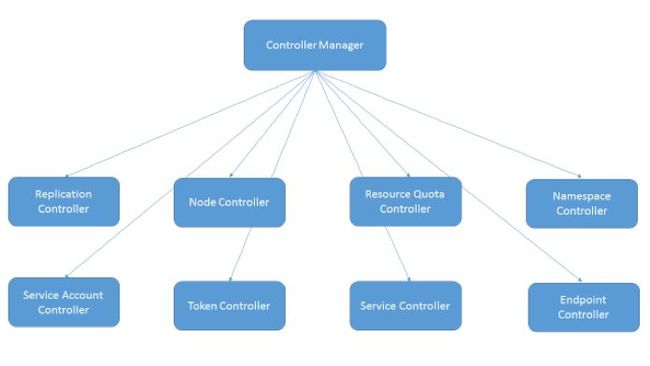
由图4我们可以看出Controller Manager由8个不同的控制器组成。以下主要对Replication Controller、Endpoint Controller予以说明。
1、Replication Controller
Replication Controller称为副本控制器,在Pod工作流中主要用于保证集群中Replication Controller所关联的Pod副本数始终保持在预期值,比如若发生节点故障的情况导致Pod被意外杀死,Replication Controller会重新调度保证集群仍然运行指定副本数,另外还可通过调整Replication Controller中spec.replicas属性值来实现扩容或缩容。
2、Endpoint Controller
Endpoint用来表示kubernetes集群中Service对应的后端Pod副本的访问地址,Endpoint Controller则是用来生成和维护Endpoints对象的控制器,其主要负责监听Service和对应Pod副本变化。如果监测到Service被删除,则删除和该Service同名的Endpoints对象;如果监测到新的Service被创建或是被修改,则根据该Service信息获得相关的Pod列表,然后创建或更新对应的Endpoints对象;如果监测到Pod的事件,则更新它对应的Service的Endpoints对象。图5所示为Service、Endpoint、Pod的关系:
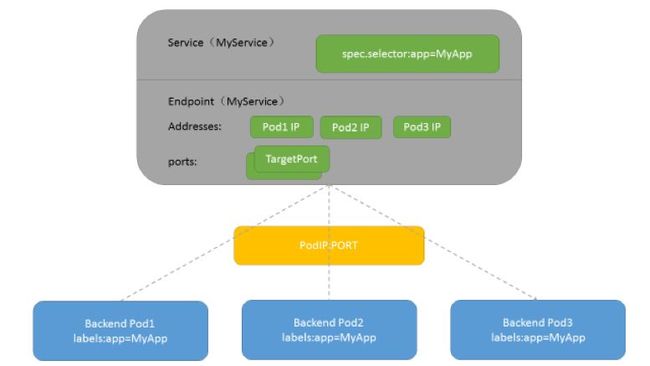
![]()
Scheduler在整个Pod工作流中负责调度Pod到具体的Node节点,Scheduler通过API Server监听Pod状态,如果有待调度的Pod,则根据Scheduler Controller中的预选策略和优选策略给各个预备Node节点打分排序,最后将Pod调度到分数最高的Node上,然后由Node中的Kubelet组件负责Pod的启停。当然如果部署的Pod指定了NodeName属性,Scheduler会根据NodeName属性值调度Pod到指定Node节点。
整个调度流程分为两步,如图6所示:

第一步预选策略(Predicates)
预选策略的主要工作机制是遍历所有当前Kubernetes集群中的Node,按照具体的预选策略选出符合要求的Node列表;如果没有符合的Node节点,则该Pod会被暂时挂起,直到有Node节点能满足条件。通用的预选策略筛选规则有:PodFitsResources、PodFitsHostPorts、HostName、MatchNodeSelector。
第二步优选策略(priorities)
有了第一步预选策略的筛选后,再根据优选策略给待选Node节点打分,最终选择一个分值最高的节点去部署Pod。Kubernetes用一组优先级函数处理每一个待选的主机。每一个优先级函数会返回一个0-10的分数,分数越高表示节点越适应需求,同时每一个函数也会对应一个表示权重的值。最终主机的得分用以下公式计算得出:
FinalScoreNode =(weight1 priorityFunc1)+(weight2 priorityFunc2)+ … +(weightn * priorityFuncn)
典型的优选策略规则
1、LeastRequestedPriority
如果新的 Pod 要分配一个Node节点,这个节点的优先级就由节点空闲的那部分与总容量的比值((总容量-节点上Pod的容量总和-新Pod的容量)/总容量)来决定。cpu和 memory权重相当,比值最大的Node节点得分最高。这个优先级函数起到了按照资源消耗来跨Node节点分配 Pods 的作用。计算公式如下:
FinalScoreNode = cpu((capacity – sum(requested))10 / capacity)+ memory((capacity – sum(requested))10 / capacity)/ 2
2、BalancedResourceAllocation
优先从备选节点列表中选择各项资源使用率最均衡的Node节点。BalancedResourceAllocation 必须和 LeastRequestedPriority同时使用而不能单独使用,它们分别计算主机上的cpu和memory的比重,Node节点分值由cpu比重和memory比重的“距离”决定。计算公式如下:
FinalScoreNode = 10 – abs(cpuFraction-memoryFraction)*10
3、SelectorSpreadPriority
对于属于同一个 Service、Replication Controller的Pod,尽量分散在不同的Node上。如调度一个Pod的时候,先查找Pod对应的Service或Replication Controller,然后查找Service或Replication Controller中已存在的Pod,Node节点上运行的已存在的Pod越少,Node的打分越高。
![]()
简而言之,Kubelet在Pod工作流中是为保证它所在的节点Pod能够正常工作,核心为监听API Server,当发现节点的Pod配置发生变化则根据最新的配置执行相应的动作,保证Pod在理想的预期状态,其中对Pod进行启停更新操作用到的是容器运行时(Docker、Rocket、LXD)。另外Kubelet也负责Volume(CVI)和网络(CNI)的管理。
在Pod工作流中,当Pod被分配至Node节点后Kubelet就去管理此Pod的生命周期,流程如下:
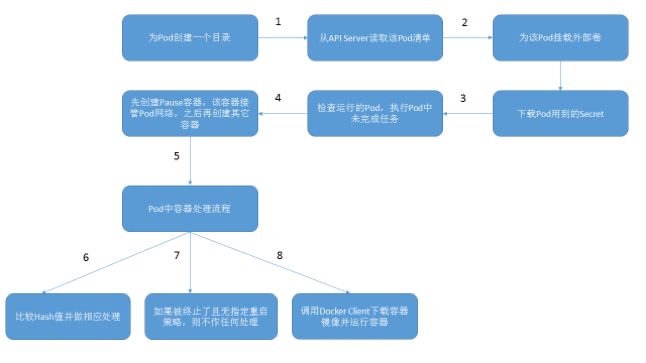
![]()
以上是对Kubernetes四个重要组件API Server、Controller Manager、Scheduler、Kubelet工作机制的解析,相信大家读完以后对这四种组件一定有了自己的见解,笔者建议在Kubernetes环境中部署应用前一定要理解kubernetes的组件架构,这样不仅有益于集群出现问题时的故障排查,也有助于个人理解Kubernetes机制。
Kubernetes版本迭代十分频繁,目前已更新到v 1.11,以上关于Kubernetes相关特性在之后的版本中可能会被弃用或更改,笔者的观点也只限于v1.11及之前的版本,希望感兴趣的同学们密切关注官方文档的更新状况以获取最新消息。
本文转载自公众号:绿盟科技研究通讯, 点击查看原文。
![]()
