OReilly.Hands-On.Machine.Learning.with.Scikit-Learn.and.TensorFlow.翻译以及读书心得--p33-p40
机器学习步骤:
1. Look at the big picture.
2. Get the data.
3. Discover and visualize the data to gain insights.
4. Prepare the data for Machine Learning algorithms.
5. Select a model and train it.
6. Fine-tune your model.
7. Present your solution.
8. Launch, monitor, and maintain your system.
获取数据集的地方:
• Popular open data repositories:
—UC Irvine Machine Learning Repository
—Kaggle datasets
—Amazon’s AWS datasets
• Meta portals (they list open data repositories):
—http://dataportals.org/
—http://opendatamonitor.eu/
—http://quandl.com/
• Other pages listing many popular open data repositories:
—Wikipedia’s list of Machine Learning datasets
—Quora.com question
—Datasets subreddit
文章将通过1990年的加州房价来开始学习。
1. Look at the Big Picture

横纬竖经度右边是中等房子的价值。
Frame the Problem
首先要弄明白的事,要向你的Boss问清楚想从Model里获得到的好处。
Model并不是最终目的。盈利点才是最重要的,他关乎到你训练的算法的取舍,评估模型的方法的选择。

Piplelines的定义:
处理数据的组件里的一个队列,当一个组件坏了,可以将坏了的组件的输出传到下一个组件继续处理,使得结构更加稳定。
原文:
Pipelines
A sequence of data processing components is called a data pipeline. Pipelines are very
common in Machine Learning systems, since there is a lot of data to manipulate and
many data transformations to apply.
Components typically run asynchronously. Each component pulls in a large amount
of data, processes it, and spits out the result in another data store, and then some time
later the next component in the pipeline pulls this data and spits out its own output,
and so on. Each component is fairly self-contained: the interface between components
is simply the data store. This makes the system quite simple to grasp (with the help of
a data flow graph), and different teams can focus on different components. Moreover,
if a component breaks down, the downstream components can often continue to run
normally (at least for a while) by just using the last output from the broken component.
This makes the architecture quite robust.
On the other hand, a broken component can go unnoticed for some time if proper
monitoring is not implemented. The data gets stale and the overall system’s performance
drops.
下一个要问的问题是,你们老板目前得到处理这个项目(问题)的办法个成效。这样可以
作为一个参考。比如,你老板会说,这个是由很多专家提出的,错误率在15%/。接下来,你就可以开始设计你的系统了。考虑你的问题是,监督学习,还是无监督学习,亦或是用强化学习解决。问题是分类问题。还是回归问题,还是别的什么。甚至要考虑会不会用到batch learning or online learning techniques。
监督学习是使用已经被标记好期望输出的训练集,回归问题会被要求去预测一个具体的值。
注意:当你的数据量特别大的时候。可以考虑把数据分割,批量处理。后文会看到MapReduce
Root Mean Square Error (RMSE)是用于评估回归问题的好措施。它测量系统在其预测中所产生的标准偏差。(原文:It measures the standard deviation4 of the errors the system makes in its predictions)
RMSE等于50,000意味着系统预测的大约68%在实际价值的50,000美元之内,而95%的预测在实际价值的100,000美元之内。(其实就是高斯分布的二维形式--正太分布)

这个公式介绍了几个非常常见的机器学习符号,我们将在这本书中使用这些符号:
(1)m是您正在测量rmse的数据集中的实例数
例如,如果您正在对2,000个地区的验证集进行rmse评估,那么m=2,000
(2)X(I)是数据集中ith实例的所有特征值(不包括标签)的向量,y(I)是它的标签(该实例的期望输出值)。
例如,如果数据集中的第一个区位于经度-118.29°,纬度33.91°,有1 416名居民,中等收入为38,372美元,房屋价值中位数为156,400美元(目前不考虑其他特征),那么:

y 1 = 156, 400
(3)X是一个矩阵,包含数据集中所有实例的所有特征值(不包括标签)。每实例有一行,第1行等于x(I)的转置,

回想一下,Transspose(转置)操作符将列向量翻转为行向量(反之亦然)。(Recall that the transpose operator flips a column vector into a row vector (and vice versa).)
(4)h是系统的预测函数,也称为假设。当给系统一个实例的特征向量x(I)时,它为该实例输出一个预测值ŷ(I)=h(x(I))(ŷ发音为“y-hat”)。
例如,如果你的系统预测第一个地区的房价中值是158,400美元,那么ŷ(1)=h(x(1))=158,400。这个地区的预测误差是ŷ(1)-y(1)=2,000。(前文的Y是156400 差为2000)
(5)rmse(x,h)是使用您的假设h在一组示例上度量的损失函数
标准偏差,通常表示σ(希腊字母西格玛),是方差的平方根,即与平均值的平方偏差的平均值。(原文:The standard deviation, generally denoted σ (the Greek letter sigma), is the square root of the variance, which is the average of the squared deviation from the mean.)
当特征具有钟形正态分布(也称为高斯分布)时,“68-95-99.7”规则适用:约68%的值在平均值的1σ内,95%在2σ内,99.7%在3σ内。也就是3σ原则。
(原文:When a feature has a bell-shaped normal distribution (also called a Gaussian distribution), which is very common, the “68-95-99.7” rule applies: about 68% of the values fall within 1σ of the mean, 95% within 2σ, and
99.7% within 3σ.)
但是RMSE不一定是最好的评估方法,当有很多的Outline Distinct时,就可以使用Mean
Absolute Error(绝对平均误差)
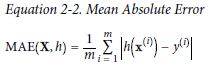
RMSE和MAE都是在判断两个向量的距离和目标值。
(1)计算平方和(Rmse)的根对应于欧几里得范数:它是你熟悉的距离概念(欧式几何距离),也称为ℓ2范数
(2)计算绝对值之和(MAE)对应于ℓ1范数,注意到∥·∥1。它有时被称为曼哈顿范数,因为它测量一个城市中两个点之间的距离,如果你只能沿着正交的城市街区旅行的话。
(3)更广泛地说,包含n个元素的向量v的ℓk范数定义为
![]()
只是给出了向量的基数(即元素数),ℓ∞给出了向量中的最大绝对值
(4)标准指数越高,它越关注大值而忽略小值。这就是为什么rmse对异常值比mae更敏感的原因。当离群点是指数罕见的(如钟形曲线),rmse表现非常好,通常是首选的
Check the Assumptions
最后,列出并验证(你或其他人)到目前为止所作的假设是很好的做法;这可能会在一开始就发现严重的问题。例如,你的系统输出的地区价格将被输入到下游机器学习系统中,我们假设这些价格将被用作补充。但是如果下游系统实际转换价格呢?分为类别(例如“廉价”、“中等”或“昂贵”),然后使用这些类别而不是价格本身?在这种情况下,完全正确的价格并不重要;您的系统只需要正确的类别。如果是这样,那么问题应该被定义为分类任务,而不是回归任务