【SIGAI综述】行人检测算法
其它机器学习、深度学习算法的全面系统讲解可以阅读《机器学习-原理、算法与应用》,清华大学出版社,雷明著,由SIGAI公众号作者倾力打造。
- 书的购买链接
- 书的勘误,优化,源代码资源
本文为SIGAI原创文章,仅供个人学习使用,未经允许,不能用于商业目的。
欢迎搜索关注微信公众号SIGAICN,获取更多原创干货

导言
行人检测是计算机视觉中的经典问题,也是长期以来难以解决的问题。和人脸检测问题相比,由于人体的姿态复杂,变形更大,附着物和遮挡等问题更严重,因此准确的检测处于各种场景下的行人具有很大的难度。在本文中,SIGAI将为大家回顾行人检测算法的发展历程。
问题描述
行人检测( Pedestrian Detection)一直是计算机视觉研究中的热点和难点。行人检测要解决的问题是:找出图像或视频帧中所有的行人,包括位置和大小,一般用矩形框表示,和人脸检测类似,这也是典型的目标检测问题。
行人检测技术有很强的使用价值,它可以与行人跟踪,行人重识别等技术结合,应用于汽车无人驾驶系统(ADAS),智能机器人,智能视频监控,人体行为分析,客流统计系统,智能交通等领域。
由于人体具有相当的柔性,因此会有各种姿态和形状,其外观受穿着,姿态,视角等影响非常大,另外还面临着遮挡 、光照等因素的影响,这使得行人检测成为计算机视觉领域中一个极具挑战性的课题。行人检测要解决的主要难题是:
外观差异大。包括视角,姿态,服饰和附着物,光照,成像距离等。从不同的角度看过去,行人的外观是很不一样的。处于不同姿态的行人,外观差异也很大。由于人穿的衣服不同,以及打伞、戴帽子、戴围巾、提行李等附着物的影响,外观差异也非常大。光照的差异也导致了一些困难。远距离的人体和近距离的人体,在外观上差别也非常大。
遮挡问题。在很多应用场景中,行人非常密集,存在严重的遮挡,我们只能看到人体的一部分,这对检测算法带来了严重的挑战。
背景复杂。无论是室内还是室外,行人检测一般面临的背景都非常复杂,有些物体的外观和形状、颜色、纹理很像人体,导致算法无法准确的区分。
检测速度。行人检测一般采用了复杂的模型,运算量相当大,要达到实时非常困难,一般需要大量的优化。
从下面这张图就可以看出行人检测算法所面临的挑战:

早期的算法使用了图像处理,模式识别中的一些简单方法,准确率低。随着训练样本规模的增大,如INRIA数据库、Caltech数据库和TUD行人数据库等的出现,出现了精度越来越高的算法,另一方面,算法的运行速度也被不断提升。按照实现原理,我们可以将这些算法可以分为基于运动检测的算法和基于机器学习的算法两大类,接下来分别进行介绍。
基于运动检测的算法
如果摄像机静止不动,则可以利用背景建模算法提取出运动的前景目标,然后利用分类器对运动目标进行分类,判断是否包含行人。常用的背景建模算法有:
高斯混合模型,Mixture of Gaussian model[1]
ViBe算法[2]
帧差分算法
SACON,样本一致性建模算法[3]
PBAS算法[4]
这些背景建模算法的思路是通过前面的帧学习得到一个背景模型,然后用当前帧与背景帧进行比较,得到运动的目标,即图像中变化的区域。

限于篇幅,我们不在这里介绍每一种背景建模算法的原理,如果有机会,SIGAI会在后续的文章中专门介绍这一问题。
背景建模算法实现简单,速度快,但存在下列问题:
1.只能检测运动的目标,对于静止的目标无法处理
2.受光照变化、阴影的影响很大
3.如果目标的颜色和背景很接近,会造成漏检和断裂
4.容易受到恶劣天气如雨雪,以及树叶晃动等干扰物的影响
5.如果多个目标粘连,重叠,则无法处理
究其原因,是因为这些背景建模算法只利用了像素级的信息,没有利用图像中更高层的语义信息。
基于机器学习的方法
基于机器学习的方法是现阶段行人检测算法的主流,在这里我们先介绍人工特征+分类器的方案,基于深度学习的算法在下一节中单独给出。
人体有自身的外观特征,我们可以手工设计出特征,然后用这种特征来训练分类器用于区分行人和背景。这些特征包括颜色,边缘,纹理等机器学习中常用的特征,采用的分类器有神经网络,SVM,AdaBoost,随机森林等计算机视觉领域常用的算法。由于是检测问题,因此一般采用滑动窗口的技术,这在SIGAI之前的公众号文章“人脸检测算法综述”,“基于深度学习的目标检测算法综述”中已经介绍过了。
HOG+SVM
行人检测第一个有里程碑意义的成果是Navneet Dalal在2005的CVPR中提出的基于HOG + SVM的行人检测算法[5]。Navneet Dalal是行人检测中之前经常使用的INRIA数据集的缔造者。
梯度方向直方图(HOG)是一种边缘特征,它利用了边缘的朝向和强度信息,后来被广泛应用于车辆检测,车牌检测等视觉目标检测问题。HOG的做法是固定大小的图像先计算梯度,然后进行网格划分,计算每个点处的梯度朝向和强度,然后形成网格内的所有像素的梯度方向分分布直方图,最后汇总起来,形成整个直方图特征。
这一特征很好的描述了行人的形状、外观信息,比Haar特征更为强大,另外,该特征对光照变化和小量的空间平移不敏感。下图为用HOG特征进行行人检测的流程:

得到候选区域的HOG特征后,需要利用分类器对该区域进行分类,确定是行人还是背景区域。在实现时,使用了线性支持向量机,这是因为采用非线性核的支持向量机在预测时的计算量太大,与支持向量的个数成正比。如果读者对这一问题感兴趣,可以阅读SIGAI之前关于SVM的文章。
目前OpenCV中的行人检测算法支持HOG+SVM以及HOG+Cascade两种,二者都采用了滑动窗口技术,用固定大小的窗口扫描整个图像,然后对每一个窗口进行前景和背景的二分类。为了检测不同大小的行人,还需要对图像进行缩放。
下面是提取出的行人的HOG特征:

HOG+AdaBoost
由于HOG + SVM的方案计算量太大,为了提高速度,后面有研究者参考了VJ[6]在人脸检测中的分类器设计思路,将AdaBoost分类器级联的策略应用到了人体检测中,只是将Haar特征替换成HOG特征,因为Haar特征过于简单,无法描述人体这种复杂形状的目标。下图为基于级联Cascade分类器的检测流程:
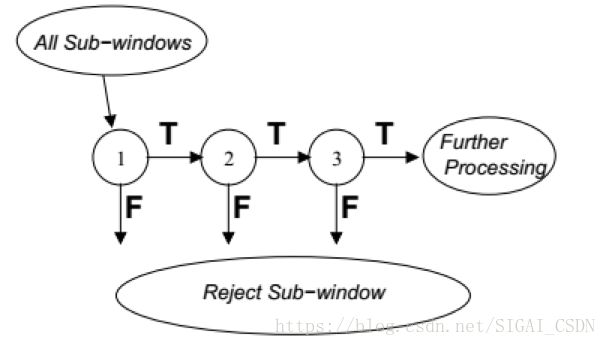
图中每一级中的分类器都是利用AdaBoost算法学习到的一个强分类器,处于前面的几个强分类器由于在分类器训练的时候会优先选择弱分类器,可以把最好的几个弱分类器进行集成,所有只需要很少的几个就可以达到预期效果,计算会非常简单,速度很快,大部分背景窗口很快会被排除掉,剩下很少一部分候选区域或通过后续的几级分类器进行判别,最终整体的检测速度有了很大的提升,相同条件下的预测时间只有基于SVM方法的十分之一。
ICF+AdaBoost
HOG特征只关注了物体的边缘和形状信息,对目标的表观信息并没有有效记录,所以很难处理遮挡问题,而且由于梯度的性质,该特征对噪点敏感。针对这些问题后面有人提出了积分通道特征(ICF)[7],积分通道特征包括10个通道:
6 个方向的梯度直方图,3 个LUV 颜色通道和1 梯度幅值,见下图,这些通道可以高效计算并且捕获输入图像不同的信息。
在这篇文章里,AdaBoost分类器采用了soft cascade的级联方式。为了检测不同大小的行人,作者并没有进行图像缩放然后用固定大小的分类器扫描,而是训练了几个典型尺度大小的分类器,对于其他尺度大小的行人,采用这些典型尺度分类器的预测结果进行插值来逼近,这样就不用对图像进行缩放。因为近处的行人和远处的行人在外观上有很大的差异,因此这样做比直接对图像进行缩放精度更高。这一思想在后面的文章中还得到了借鉴。通过用GPU加速,这一算法达到了实时,并且有很高的精度,是当时的巅峰之作。

DPM+ latent SVM
行人检测中的一大难题是遮挡问题,为了解决这一问题,出现了采用部件检测的方法,把人体分为头肩,躯干,四肢等部分,对这些部分分别进行检测,然后将结果组合起来,使用的典型特征依然是HOG,采用的分类器有SVM和AdaBoost。针对密集和遮挡场景下的行人检测算法可以阅读文献[15]。
DPM(Deformable Parts Models)算法在SIGAI在之前的文章“基于深度学习的目标检测算法综述”已经提到过。这是是一种基于组件的检测算法,DPM检测中使用的特征是HOG,针对目标物不同部位的组建进行独立建模。DPM中根模型和部分模型的作用,根模型(Root-Filter)主要是对物体潜在区域进行定位,获取可能存在物体的位置,但是是否真的存在我们期望的物体,还需要结合组件模型(Part-Filter)进行计算后进一步确认,DPM的算法流程如下:
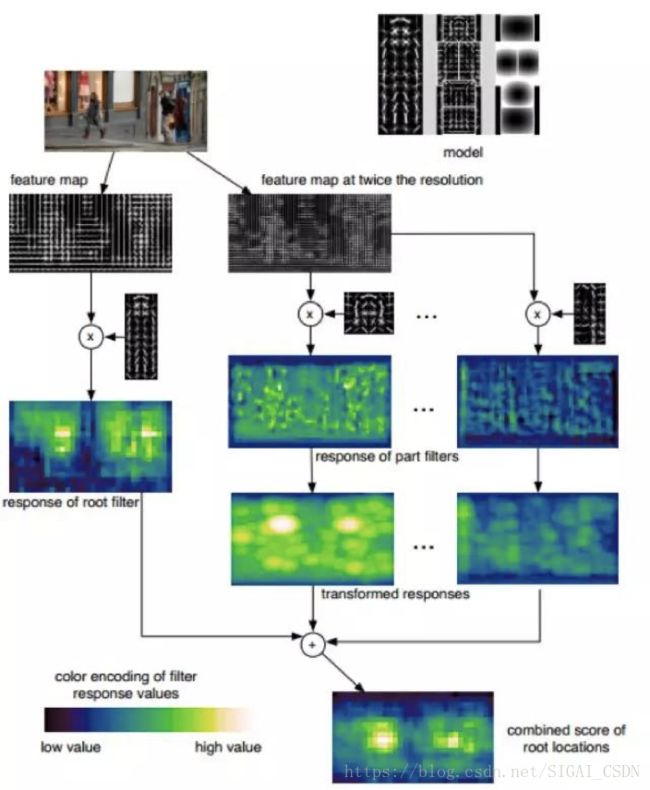
DPM算法在人体检测中取得取得了很好的效果,主要得益于以下几个原因:
1.基于方向梯度直方图(HOG)的低级特征(具有较强的描述能力)
2.基于可变形组件模型的高效匹配算法
3.采用了鉴别能力很强的latent-SVM分类器
DPM算法同时存在明显的局限性,首先,DPM特征计算复杂,计算速度慢(论文[8]中针对DPM提出了多个加速的策略,有兴趣的读者可以参考);其次,人工特征对于旋转、拉伸、视角变化的物体检测效果差。这些弊端很大程度上限制了算法的应用场景,这一点也是基于人工特征+分类器的通病。
采用经典机器学习的算法虽然取得了不错的成绩,但依然存在下面的问题:
1.对于外观,视角,姿态各异的行人检测精度还是不高
2.提取的特征在特征空间中的分布不够紧凑
3.分类器的性能受训练样本的影响较大
4.离线训练时的负样本无法涵盖所有真实应用场景的情况
基于机器学习的更多方法以参考综述文章[10][18][19]。文献[10]对常见的16种行人检测算法进行了简单描述,并在6个公开测试库上进行测试,给出了各种方法的优缺点及适用情况。
文献[18]提出了Caltech数据集,相比之前的数据集,它的规模大了2个数量级。作者在这个数据集上比较了当时的主要算法,分析了一些失败的的原因,为后续的研究指出了方向。
文献[19]也比较了10年以来的行人检测算法,总结了各种改进措施,并支持了以后的研究方向。
基于深度学习的算法
基于背景建模和机器学习的方法在特定条件下可能取得较好的行人检测效率或精确度,但还不能满足实际应用中的要求。自从2012年深度学习技术被应用到大规模图像分类以来[9],研究人员发现基于深度学习学到的特征具有很强层次表达能力和很好的鲁棒性,可以更好的解决一些视觉问题。因此,深度卷积神经网络被用于行人检测问题是顺理成章的事情。
SIGAI之前的文章“基于深度学习的目标检测算法综述”全面介绍了基于深度学习的通用目标检测框架,如Faster-RCNN、SSD、FPN、YOLO等,这些方法都可以直接应用到行人检测的任务中,以作者实际经验,相比之前的SVM和AdaBoost分类器,精度有显著的提升。小编根据Caltech行人数据集的测评指标[11],选取了几种专门针对行人问题的深度学习解决方案进行介绍。

从上图可以看出,行人检测主要的方法是使用人工特征+分类器的方案,以及深度学习方案两种类型。使用的分类器有线性支持向量机,AdaBoost,随机森林。接下来我们重点介绍基于卷积网络的方案。
Cascade CNN
如果直接用卷积网络进行滑动窗口检测,将面临计算量太大的问题,因此必须采用优化策略。文献[22]提出了一种用级联的卷积网络进行行人检测的方案,这借鉴了AdaBoost分类器级联的思想。前面的卷积网络简单,可以快速排除掉大部分背景区域:

后面的卷积网络更复杂,用于精确的判断一个候选窗口是否为行人,网络结构如下图所示:

通过这种组合,在保证检测精度的同时极大的提高了检测速度。这种做法和人脸检测中的Cascade CNN类似。
JointDeep
在文献[12]中,作者使用了一种混合的策略,以Caltech行人数据库训练一个卷积神经网络的行人分类器。该分类器是作用在行人检测的最后的一级,即对最终的候选区域做最后一关的筛选,因为这个过程的效率不足以支撑滑动窗口这样的穷举遍历检测。
作者用HOG+CSS+SVM作为第一级检测器,进行预过滤,把它的检测结果再使用卷积神经网络来进一步判断,这是一种由粗到精的策略,下图将基于JointDeep的方法和DPM方法做了一一对应比较。
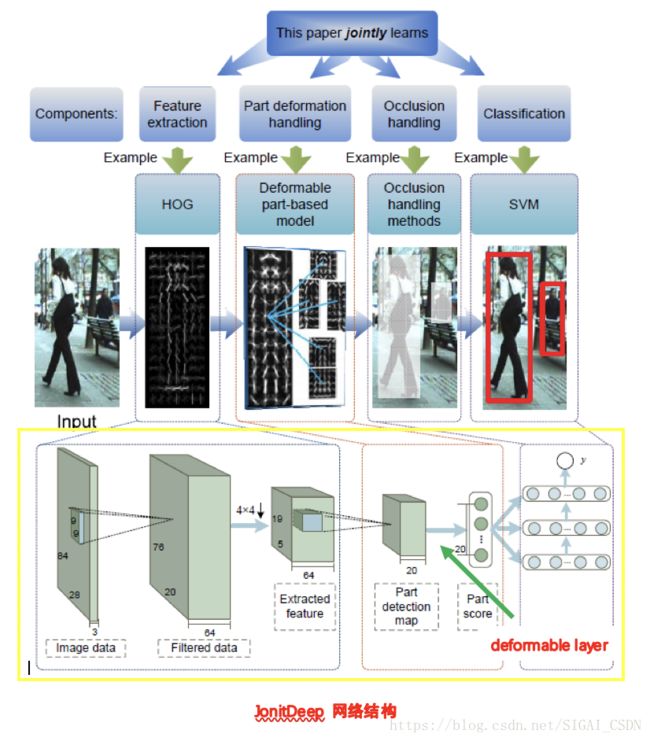
卷积网络的输入并不是RGB通道的图像,而是作者实验给出的三个通道,第一个通道是原图的YUV中的Y通道,第二个通道被均分为四个block,行优先时分别是U通道,V通道,Y通道和全0;第三个通道是利用Sobel算子计算的第二个通道的边缘。
另外还采用了部件检测的策略,由于人体的每个部件大小不一,所以作者针对不同的部件设计了大小不一的卷积核尺寸,如下图a所示,Level1针对比较小的部件,Level2针对中等大小的部件,Level3针对大部件。由于遮挡的存在,作者同时设计了几种遮挡的模式。
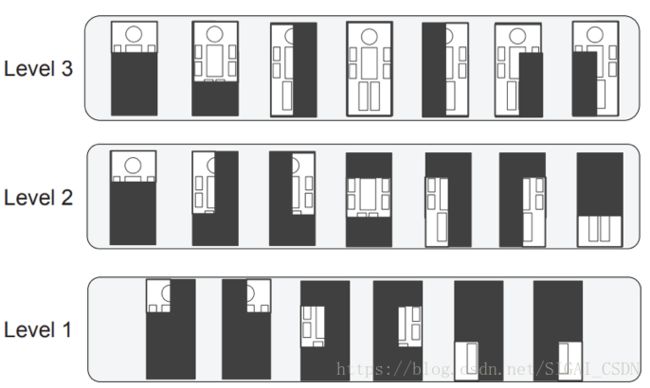
(a)
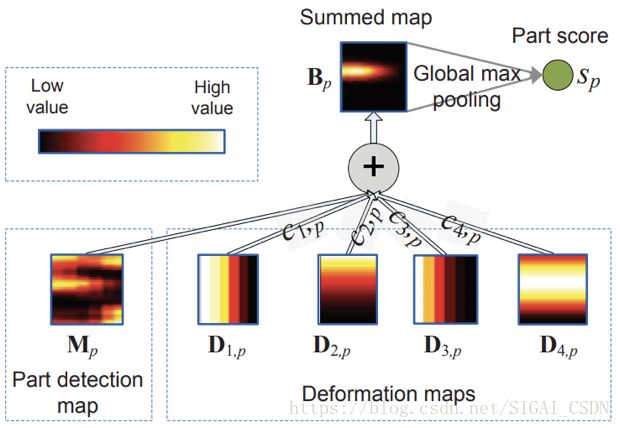
(b)
SA-FastRCNN
文献[13]提出了一种称为SA-FastRCNN的方法,作者分析了Caltech行人检测数据库中的数据分布,提出了以下两个问题:
1.行人尺度问题是待解决的一个问题
2.行人检测中有许多的小尺度物体, 与大尺度物体实例在外观特点上非常不同
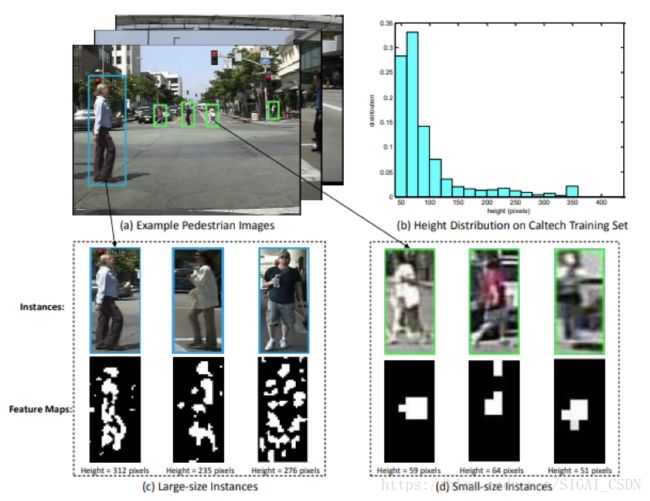
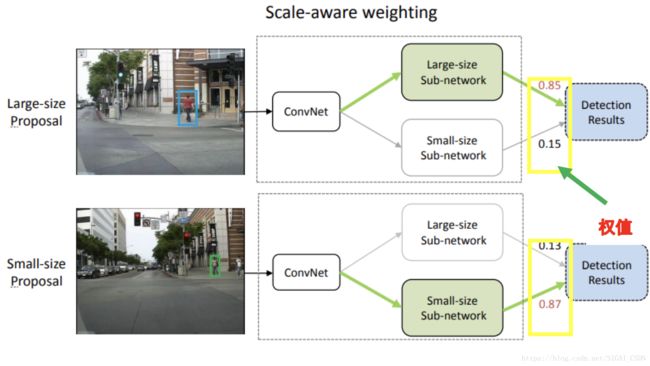
作者针对行人检测的特点对Fast R-CNN进行了改进,由于大尺寸和小尺寸行人提取的特征显示出显着差异,作者分别针对大尺寸和小尺寸行人设计了2个子网络分别进行检测。利用训练阶段得到的scale-aware权值将一个大尺度子网络和小尺度子网络合并到统一的框架中,利用候选区域高度估计这两个子网络的scale-aware权值,论文中使用的候选区域生成方法是利用ACF检测器提取的候选区域,总体设计思路如下图所示:
SA-FastRCNN的架构如下图所示:
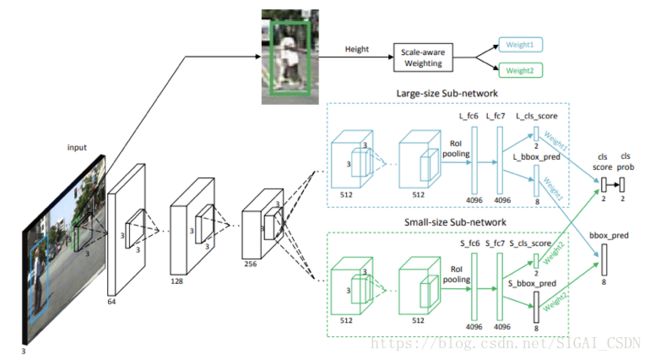
这种scale-aware加权机制可以被认为是两个子网络的soft-activation,并且最终结果总是可以通过适合当前输入尺寸的子网络提升。
Faster R-CNN
文献[16]分析了Faster R-CNN在行人检测问题上的表现,结果表明,直接使用这种算法进行行人检测效果并不满意。作者发现,Faster R-CNN中的RPN网络对提取行人候选区域是相当有效的,而下游的检测网络表现的不好。作者指出了其中的两个原因:对于小目标,卷积层给出的特征图像太小了,无法有效的描述目标;另外,也缺乏难分的负样本挖掘机制。作者在这里采用了一种混合的策略,用RPN提取出候选区域,然后用随机森林对候选区域进行分类。这一结构如下图所示:
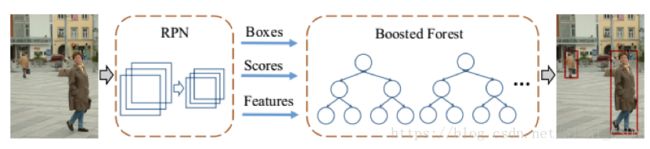
DeepParts
文献[21]提出了一种基于部件的检测方案,称为DeepParts,致力于解决遮挡问题。这种方案将人体划分成多个部位,分别进行检测,然后将结果组合起来。部位划分方案如下图所示:
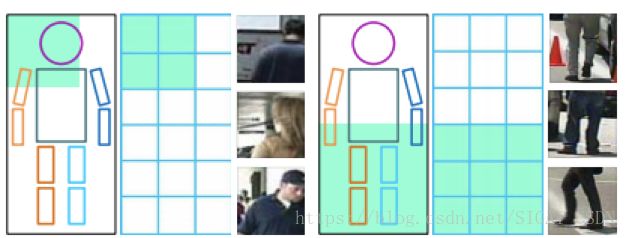
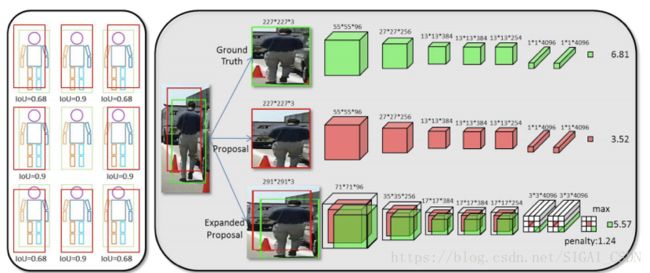
整个系统的结构如下图所示:
RepLoss
RepLoss[14]由face++提出,主要目标是解决遮挡问题。行人检测中,密集人群的人体检测一直是一个难题。物体遮挡问题可以分为类内遮挡和类间遮挡两类。类内遮挡指同类物体间相互遮挡,在行人检测中,这种遮挡在所占比例更大,严重影响着行人检测器的性能。
针对这个问题,作者设计也一种称为RepLoss的损失函数,这是一种具有排斥力的损失函数,下图为RepLoss示意图:
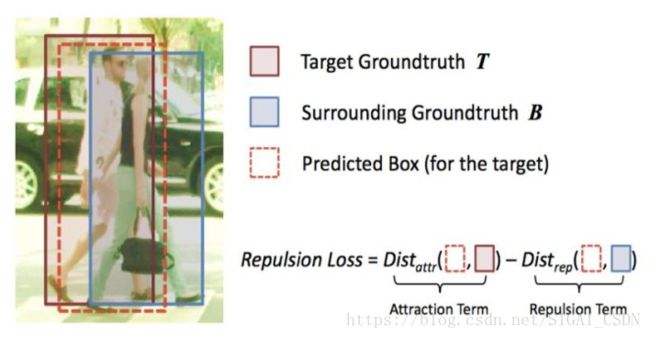
RepLoss 的组成包括 3 部分,表示为:
![]()
其中L_Attr 是吸引项,需要预测框靠近其指定目标;L_RepGT 和 L_RepBox 是排斥项,分别需要当前预测框远离周围其它的真实物体和该目标其它的预测框。系数充当权重以平衡辅助损失。
HyperLearner
文献[25]提出了一种称为HyperLearner的行人检测算法,改进自Faster R-CNN。在文中,作者分析了行人检测的困难之处:行人与背景的区分度低,在拥挤的场景中,准确的定义一个行人非常困难。
作者使用了一些额外的特征来解决这些问题。这些特征包括:
apparent-to-semantic channels
temporal channels
depth channels
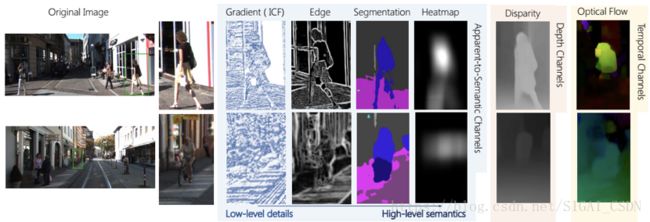
为了将这些额外的特征也送入卷积网络进行处理,作者在VGG网络的基础上增加了一个分支网络,与主体网络的特征一起送入RPN进行处理:
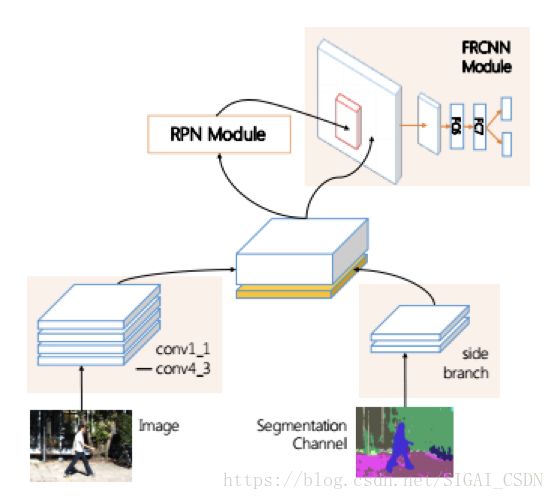
其他的基本上遵循了Faster R-CNN框架的处理流程,只是将anchor参数做了改动。在实验中,这种算法相比Faster R-CNN有了精度上的提升。
从上面的回顾也可以看出,与人脸检测相比,行人检测难度要大很多,目前还远称不上已经解决,遮挡、复杂背景下的检测问题还没有解决,要因此还需要学术界和工业界的持续努力。
参考文献
[1]P. KaewTraKulPong and R. Bowden. An improved adaptive background mixture model for real-time tracking with shadow detection. in European Workshop on Advanced Video Based Surveillance Systems,(London, UK), September 2001.
[2]Barnich O, Van Droogenbroeck M. ViBe:a universal background subtraction algorithm for video sequences. IEEE Transactions on Image Processing, 2011, 20(6):1709-1724.
[3]H. Wang and D. Suter. A consensus-based method for tracking: Modelling background scenario and foreground appearance. Pattern Recognition, vol. 40, pp. 1091–1105, March 2007.
[4]M. Hofmann. Background segmentation with feedback: The pixelbased adaptive segmenter. In IEEE Workshop on Change Detection, 2012. 6, 7, 8
[5]N. Dalal, B. Triggs. Histograms of oriented gradients for human detection. in: Computer Vision and Pattern Recognition, San Diego, CA, June 20–25, 2005.
[6]M.Jones, P.Viola. Fast Multi-View Face Detection. Mitsubishi Electric Research Laboratories, Technical Report: MERL-2003-96, July 2003.
[7]P. Dolla´r, Z. Tu, P. Perona, and S. Belongie, “Integral Channel Features,” Proc. British Machine Vision Conf., 2009.
[8]J. Yan, Z. Lei, L. Wen, and S. Z. Li. The fastest deformable part model for object detection. In Computer Vision and Pattern Recognition (CVPR), 2014 IEEE Conference on, pages 2497–2504. IEEE, 2014. 5, 6
[9]Krizhevsky, A., Sutskever, I., and Hinton, G. E. ImageNet classification with deep convolutional neural networks. In NIPS, pp. 1106–1114, 2012
[10]Piotr Dollar, Christian Wojek, Bernt Schiele, Pietro Perona. Pedestrian Detection: An Evaluation of the State of the Art. 2012, IEEE Transactions on Pattern Analysis and Machine Intelligence.
[11]http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/files/algorithms.pdf
[12]W. Ouyang and X. Wang. Joint deep learning for pedestrian detection. In ICCV, 2013. 3
[13]Jianan Li, Xiaodan Liang, ShengMei Shen, Tingfa Xu, and Shuicheng Yan. Scaleaware fast r-cnn for pedestrian detection. arXiv preprint arXiv:1510.08160, 2015.
[14]Xinlong Wang, Tete Xiao, Yuning Jiang, Shuai Shao, Jian Sun, Chunhua Shen. Repulsion Loss: Detecting Pedestrians in a Crowd.
[15]Bastian Leibe, Edgar Seemann, Bernt Schiele. Pedestrian detection in crowded scenes.2005, computer vision and pattern recognition.
[16]Liliang Zhang, Liang Lin, Xiaodan Liang, Kaiming He. Is Faster R-CNN Doing Well for Pedestrian Detection? 2016, european conference on computer vision.
[17]Pierre Sermanet, Koray Kavukcuoglu, Soumith Chintala, Yann Lecun. Pedestrian Detection with Unsupervised Multi-stage Feature Learning. 2013, computer vision and pattern recognition.
[18]Piotr Dollar, Christian Wojek, Bernt Schiele, Pietro Perona. Pedestrian detection: A benchmark. 2009, computer vision and pattern recognition.
[19]Rodrigo Benenson, Mohamed Omran, Jan Hendrik Hosang, Bernt Schiele. Ten Years of Pedestrian Detection, What Have We Learned? 2014, european conference on computer vision.
[20]Denis Tome, Federico Monti, Luca Baroffio, Luca Bondi, Marco Tagliasacchi, Stefano Tubaro. Deep convolutional neural networks for pedestrian detection 2016,Signal Processing-image Communication.
[21]Yonglong Tian, Ping Luo, Xiaogang Wang, Xiaoou Tang. Deep Learning Strong Parts for Pedestrian Detection. 2015, international conference on computer vision.
[22]A. Angelova, A. Krizhevsky, V. Vanhoucke, A. Ogale, and D. Ferguson
Real-Time Pedestrian Detection With Deep Network Cascades. BMVC 2015.
[23]P. Dollar, S. Belongie and P. Perona. The Fastest Pedestrian Detector in the West, BMVC 2010.
[24]Deep Learning Strong Parts for Pedestrian Detection. Yonglong Tian, Ping Luo, Xiaogang Wang, Xiaoou Tang. 2015, international conference on computer vision.
[25]Jiayuan Mao, Tete Xiao, Yuning Jiang, Zhimin Cao. What Can Help Pedestrian Detection? CVPR 2017.
[26]S Zhang, Rodrigo Benenson, Mohamed Omran, Jan Hendrik Hosang, Bernt Schiele.How Far are We from Solving Pedestrian Detection. 2016, computer vision and pattern recognition.
推荐阅读
1] 机器学习-波澜壮阔40年 SIGAI 2018.4.13.
[2] 学好机器学习需要哪些数学知识?SIGAI 2018.4.17.
[3] 人脸识别算法演化史 SIGAI 2018.4.20.
[4] 基于深度学习的目标检测算法综述 SIGAI 2018.4.24.
[5] 卷积神经网络为什么能够称霸计算机视觉领域? SIGAI 2018.4.26.
[6] 用一张图理解SVM的脉络 SIGAI 2018.4.28.
[7] 人脸检测算法综述 SIGAI 2018.5.3.
[8] 理解神经网络的激活函数 SIGAI 2018.5.5.
[9] 深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读 SIGAI 2018.5.8.
[10] 理解梯度下降法 SIGAI 2018.5.11.
[11] 循环神经网络综述—语音识别与自然语言处理的利器 SIGAI 2018.5.15
[12] 理解凸优化 SIGAI 2018.5.18
[13]【实验】理解SVM的核函数和参数 SIGAI 2018.5.22
原创声明 本文为 SIGAI 原创文章,仅供个人学习使用,未经允许,不能用于商业目的。