CVPR18读文笔记:SINT++:Robust Visual Tracking via Adversarial Postive Instance Generation
CVPR18一共出现了3篇将Adersarial概念应用于tracking,解决正样本弱的问题。VITAL是用了GAN,惊为天人。本文国产,索然性能不是最优,但是VAE+DRL+SINT的集大成之作,还是足够significant。
- 本文主旨:
Improve the robustness of visual tracking through the generation of hard positive samples. Baseline tracker用的是SINT,即一个Siamese two-frame matching(learn a matching function to match DRs in new frame match to Trajs in last frame)。
- 文章概述:
针对online trained T-by-D tracker训练时(hard) 正样本(双重)匮乏(具有long-tail distribution的rare and uncommon positive samples)的问题,即1. 正样本总量少且在线密集重叠采样导致正样本之间overlap太大,不够diverse;2. Hard正样本(被遮挡和形变的)更少。这种训练数据的匮乏导致训练所得的classifier and tracker无法捕捉和适应目标在线发生的外观变化。
传统方法为了解决正样本总量少的问题,可采用暴力采集样本扩大数据集或者random geometric or appearance transformation的data augmentation。这两种方法1. 费时费力不智能;2. 依旧不能解决hard positive少的问题。
因此,为了填补Deep CNN对正样本的需求与跟踪本质上只能提供有限正样本的这个矛盾。本文1. 通过Adversarial Generation(VAE)的思想,补充增强正样本;2. 通过DRL学习用背景负样本图片遮挡正样本图片生成hard正样本。
总结来说,本文一共由三大核心模块组成,解决三个核心问题:
- Positive Sample Generation Network (PSGN):
假设所有目标样本都存在于一个manifold之上,因为用一个VAE(Variational Auto-Encoder)来decode生成大量与原encoding样本相似但又不完全一样的(with more diversity and degree of deformation and motion blur)正样本;解决正样本总量少的问题;
- Hard Positive Transformation Network (HPTN):
用Deep Reinforcement Learning的手段学习如何使用负样本图片遮挡正样本图片以产生被遮挡的hard positive samples;解决hard正样本少的问题;
- Two-stream Siamese Instance Search Network。
SINT(CVPR16)是一个offline trained matching function,no online model updating(后续帧一直与第一帧匹配),no occlusion detection,no combination of trackers,no geometric matching的tracker。SINT的几大特点如下:
- 类fast-rcnn的roi pooling加速设计:
Siamese的两路CNN都采用输入整图加多个bbox的input,前几层conv直接提取全图的feature(这样就节省了分别输入多个小patch多个pass的时间和计算),然后用roi pooling把bbox的feature map转换为固定长度的feature vector;
- 控制pooling的次数:
classification的任务更依赖于semantic information所以down-sampling损失掉resolution信息并不可怕。但是类似检测跟踪这一类localization的任务对像素级信息依赖,所以希望在resolution上尽量少degrade;
- CNN feature hierarchical:
顶层semantic information和底层spatial information的结合。
- Matching function的训练:
是一对儿图片外加一个label作为一个训练样本。

上图(a)描述了在一帧中estimated location周围按照IoU密集采集到的正样本基本相似,不够diverse;(b)描述了出现遮挡的hard positive很少;(3)左是PSGN中的VAE,右是HPTN中的DRL。
- 技术细节:
- 网络流程:
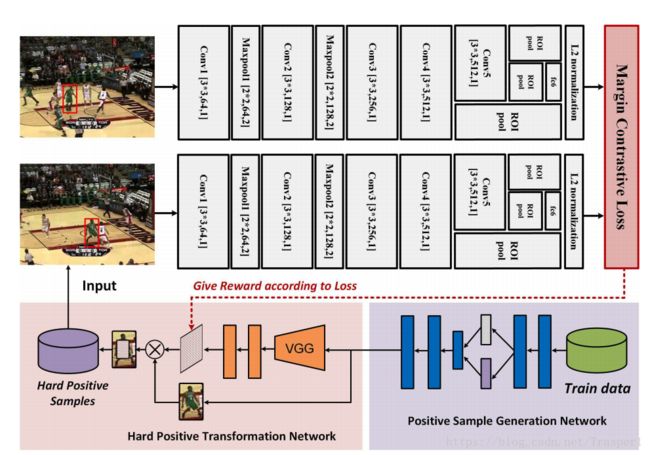
最上端的SINT是按照原文照搬的;SINT的input数据最先由PSGN的VAE生成reconstructed sample images,这些images输入HPTN然后将它们occlude,之后这些occluded image再输入SINT去训练一个matching function。基于这样造就的数据训练出来的matching function,对于遮挡等带来的形变更加鲁邦。
- PSGN:
- VAE理解:一个数据转换。将input图片通过encoder转换成一个latent variable vector,再由decoder转换回图像维,生成一张新图片。为了是这种转换受约束且有创造力,在encode的过程中约束latent variable必须服从Gaussian分布,这就是Variational中variation的来由。输出与输入图片在经历了一次数据转化之后产生的变化,来自于encode时对中间latent variable vector的高斯分布约束。

最初,仅仅是一个decoder,即从一个vector decode出一个图片,换言之,可以把一只猫的图片储存为一个【0,0,0,1】的向量,通过decoder来还原。
然而这样做的弊端是one-hot encoding的容量由位数直接限制。所以考虑如何把one-hot的向量转化成实数向量比如【4.3, 3.1, 3.2,5.6】来代表一只猫。
这样的向量如果通过随机初始化来获得,不理想。
那么,就外加一个encoder网络,来负责生成这种latent variable(即实数化的向量)。这就得到了一个如下的标准自编码器。

标准自编码器的能力是把一张图encode成一个latent向量来储存,但它并没有能力生成未曾见过的图片。而只是起到了一个图片到vector的翻译作用。
那么,为了能够使得AE网络能够生成与input图像不同的output图像,又不randomly地manipulate latent variable,那么最好的办法就是对encoder生成latent variable的过程加限制条件,即迫使encoder产生服从单位高斯分布的latent variable。具有这样特性的标准自编码器就进化为了VAE。
这时,要产生新的图片,只需要在单位高斯分布上采样得到一个latent variable,然后将其传给解码器decode出图像即可。
在训练时,计算重构图像与GT的loss就有两部分组成,一部分去计算图像的重构误差(MSE),另一部分去用KL-divergence度量latent variable distribution与单位高斯distribution的差异:

为了优化KL-divergence的计算,用到一个参数重构的技巧:不像标准自编码器那样直接产生实数值向量,VAE encoder两个数:产生单位高斯分布的mean和standard deviation vector,再由这两个值从其描述的Gaussian distribution上采样:

- PSGN中VAE的作用是利用中间的latent variable(其实就是2D,即一个Gaussian distribution的mean和std)map到一个manifold上,所有见到过的目标都落在这个manifold之上,因而在这个manifold上沿不同方向(可以得到不同的vector?)decode就能得到diverse的正样本,这样就解决了密集采样正样本不diverse的问题。这个VAE生成的reconstructed正样本,既包括与真实样本相似的样本,还包括不曾见过的样本,这些样本可以理解为帧间的变化。

这个VAE的输入将bbox resize到64*64*3再flatten之后的12288维向量。中间层latent variable的输出是2D,后接一个512D的FC。整个VAE是FC based,没有conv。注意,本文对每一段视频是单独训练这个VAE的,有点cheating啊!
- HPTN:一个标准的DQN网络训练。

Hard positive transformation就是做两件事:1. Decide which part to occlude;2. Decide use which part of background patch to occlude。这两件事合二为一就是选择一个image patch。这个在大图上选择一个小patch的过程,可以用deep reinforcement learning with 8 actions来做,转化为一个Markov Decision Process(MDP):

这里面不断在选择的patch是resized到224 * 224的patch,feature采自VGG的第八层conv。 Reward function如下:

其中s和s‘是连续的连个state(即有s进行一次action就得到s’),St是后面SINT给t这一MDP种时间节点产生的state(一张遮挡了的正样本图片)的打分,换言之,上式就是SINT给这个正样本的打分越低,reward越大,即这次action选择的state遮挡的越好越能迷惑SINT。
具体DQN的训练没看懂,需深究。。。
- 实验:
似乎SINT,PSGN,HPTN这三部分都是分开训练的,完全不是E2E。时效性与SINT相仿2fps左右,精确性只是超过SINT,但并不能与MDNet和ECO等抗衡。性能不堪但仍能够中稿CVPR,体现了本文VAE+DRL+SINT的集大成之优势。