EDVR工程代码调试+训练(详细版)
好的,受委托于一个朋友,小编在本文将会以第一人称详细记录EDVR的代码跑通过程。
1. 环境配置
基于virtualenv的虚拟环境配置见博文vid2vid 代码调试+训练+测试(debug+train+test)(一)测试篇。
2. 下载代码
$ git clone https://github.com/xinntao/EDVR.git
$ cd EDVR这之后我们会处于“…/EDVR/”目录下。
3. 准备数据集
在目录“.../EDVR/datasets/”下 有一个文件的文件名暗示我们将数据放在该目录下。
有一个文件的文件名暗示我们将数据放在该目录下。
假设我们现在要做的是DEBLUR((视频去模糊)的任务,这就要求训练数据(input与output)的分辨率是一样的。训练数据结构如下图_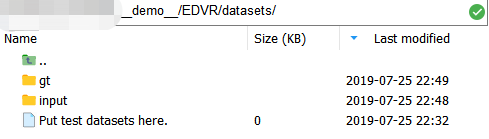
"""
datasets
|--input
|--000000 # clip
|--000000.jpg
|--000001.jpg
...
|--000029.jpg # 30 frames for each clip in our datasets
|--000001
|--000000.jpg
...
...
|--gt
|--000000 # clip
|--000000.jpg
|--000001.jpg
...
|--000029.jpg # 30 frames for each clip in our datasets
|--000001
|--000000.jpg
...
...
"""
** 这里我们的图片格式是.jpg;
** 视频片段(子文件夹)格式是:xxxxxx
** 帧的命名格式是:xxxxxx.jpg
** 图像大小是:高 480 x 宽 640
** 这些很重要,后面我们会修改代码。本工程对事先还对数据做了做了封装,这是因为,如果每一次iteration(注意训练的时候我们是有若干个epoch,每次epoch中有多次iteration即迭代,迭代次数与数据集大小和选用的batch size有关,一般num of iterations = size of datasets / batch size)从磁盘读入图片数据会很慢!因此,使用lmdb库,这是一种数据库,一般是直接装载在内存,所以读取会飞快!
我们先看一下生成代码。
pip install lmdb
# 先安装对应的python库cd 进入目录“/__demo__/EDVR/codes/data_scripts/”, ,本项目原来面向的数据集有两个:1)用户视频超分辨率任务的vimeo90k,和2)用于视频帧去模糊REDS。
,本项目原来面向的数据集有两个:1)用户视频超分辨率任务的vimeo90k,和2)用于视频帧去模糊REDS。
小编这里数据的input与GT是同样分辨率的,因此应该是类似于REDS的视频去模糊任务;所以我们打算修改“greate_lmdb_mp.py”文件中对于REDS数据集生成lmdb格式的文件的代码。
总共有4个函数,我们修改第三个REDS。我们复制整个函数,然后重命名为OURS。
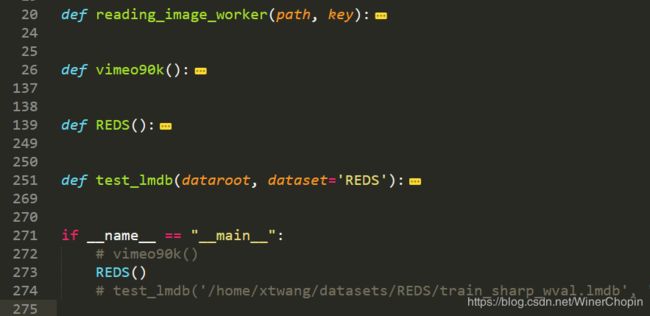
注意后边有注释“# **”就是修改的行与备注。
def OURS(mode="input"):
'''create lmdb for the REDS dataset, each image with fixed size
GT: [3, H, W], key: 000000_000000
LR: [3, H, W], key: 000000_000000
key: 000000_00000
** 记得前面我们的数据结构吗?{子目录名}_{图片名}
'''
#### configurations
mode = mode # ** 数据模式: input / gt
read_all_imgs = False # whether real all images to the memory. Set False with limited memory
BATCH = 5000 # After BATCH images, lmdb commits, if read_all_imgs = False
if mode == 'input':
img_folder = './../../datasets/train/input' # ** 使用相对路径指向我们的数据集的input
lmdb_save_path = './../../datasets/train_input_wval.lmdb' # ** 待会生成的lmdb文件存储的路径
'''原来使用全局路径,我们使用相对路径'''
H_dst, W_dst = 480, 640 # 帧的大小:H,W
elif mode == 'gt':
img_folder = './../../datasets/train/gt' # ** 使用相对路径指向我们的数据集的input
lmdb_save_path = './../../datasets/train_gt_wval.lmdb' # ** 待会生成的lmdb文件存储的路径
'''原来使用全局路径,我们使用相对路径'''
H_dst, W_dst = 480, 640 # 帧的大小:H,W
n_thread = 40
########################################################
if not lmdb_save_path.endswith('.lmdb'):
raise ValueError("lmdb_save_path must end with \'lmdb\'.") # 保存格式必须以“.lmdb”结尾
#### whether the lmdb file exist
if osp.exists(lmdb_save_path):
print('Folder [{:s}] already exists. Exit...'.format(lmdb_save_path)) # 文件是否已经存在
sys.exit(1)
#### read all the image paths to a list
print('Reading image path list ...')
all_img_list = data_util._get_paths_from_images(img_folder) # 获取input/gt下所有帧的完整路径名,作为list
keys = []
for img_path in all_img_list:
split_rlt = img_path.split('/')
# 取子文件夹名 xxxxxx
a = split_rlt[-2]
# 取帧的名字,出去文件后缀 xxxxxx
b = split_rlt[-1].split('.jpg')[0] # ** 我们的图像是".jpg"结尾的
keys.append(a + '_' + b)
if read_all_imgs: # read_all_images = False,所以这部分不管
#### read all images to memory (multiprocessing)
dataset = {} # store all image data. list cannot keep the order, use dict
print('Read images with multiprocessing, #thread: {} ...'.format(n_thread))
pbar = util.ProgressBar(len(all_img_list))
def mycallback(arg):
'''get the image data and update pbar'''
key = arg[0]
dataset[key] = arg[1]
pbar.update('Reading {}'.format(key))
pool = Pool(n_thread)
for path, key in zip(all_img_list, keys):
pool.apply_async(reading_image_worker, args=(path, key), callback=mycallback)
pool.close()
pool.join()
print('Finish reading {} images.\nWrite lmdb...'.format(len(all_img_list)))
#### create lmdb environment
data_size_per_img = cv2.imread(all_img_list[0], cv2.IMREAD_UNCHANGED).nbytes # 每帧图像大小(byte为单位)
if 'flow' in mode:
data_size_per_img = dataset['000_00000002_n1'].nbytes
print('data size per image is: ', data_size_per_img)
data_size = data_size_per_img * len(all_img_list) # 总的需要多少空间
env = lmdb.open(lmdb_save_path, map_size=data_size * 10) # 索取这么多的比特数
#### write data to lmdb
pbar = util.ProgressBar(len(all_img_list))
txn = env.begin(write=True)
idx = 1
for path, key in zip(all_img_list, keys):
idx = idx + 1
pbar.update('Write {}'.format(key))
key_byte = key.encode('ascii')
data = dataset[key] if read_all_imgs else cv2.imread(path, cv2.IMREAD_UNCHANGED)
if 'flow' in mode:
H, W = data.shape
assert H == H_dst and W == W_dst, 'different shape.'
else:
H, W, C = data.shape # fixed shape
assert H == H_dst and W == W_dst and C == 3, 'different shape.'
txn.put(key_byte, data)
if not read_all_imgs and idx % BATCH == 1:
txn.commit()
txn = env.begin(write=True)
txn.commit()
env.close()
print('Finish writing lmdb.')
#### create meta information # 存储元数据:名字(str)+分辨率(str)
meta_info = {}
meta_info['name'] = 'OURS_{}_wval'.format(mode) # ** 现在的数据集是OURS了
if 'flow' in mode:
meta_info['resolution'] = '{}_{}_{}'.format(1, H_dst, W_dst)
else:
meta_info['resolution'] = '{}_{}_{}'.format(3, H_dst, W_dst)
meta_info['keys'] = keys
pickle.dump(meta_info, open(osp.join(lmdb_save_path, 'meta_info.pkl'), "wb"))
print('Finish creating lmdb meta info.')顺带修改下面的“if __name__ == '__main__':”如下:
if __name__ == "__main__":
OURS(mode="input")
OURS(mode="gt")然后在当前目录下执行:
$ python create_lmdb_mp.py完了后我们就会看到datasets目录下多了两个lmdb文件: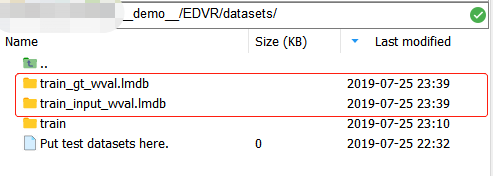 ,对实际上他们是文件夹!每个文件夹下包含
,对实际上他们是文件夹!每个文件夹下包含 ,其中:data.mdb包含的是图像数组的数据(以二进制形式存储),lock.mdb是数据库中防止读写冲突的锁,meta_info.pkl包括三部分,结构如下:
,其中:data.mdb包含的是图像数组的数据(以二进制形式存储),lock.mdb是数据库中防止读写冲突的锁,meta_info.pkl包括三部分,结构如下:
"""
{
'name': 'xxxxxxxxxxxx',
'resolution': '3_480_640',
'keys': ['000000_000000', '000000_000001', ...]
}
"""对,我们需要通过这些key去访问data.mdb中对应的图像数据!
现在,我们已经把数据准备好了,还差最后一步!显然,在datasets目录下新生的“train_input_wval.lmdb”与“train_gt_wval.lmdb”中的meta_info.pkl的内容是一样的!!!我们需要把其中一个复制到“EDVR/codes/data/”目录下,很重要,训练的时候需要用到!
$ cd ../
$ cp datasets/train_input_wval.lmdb/meta_info.pkl codes/data/好了,到这里数据就准备完成了!
4. 修改模型配置
现在我们来修改“/EDVR/codes/options/train/”下的训练配置文件 。我们先复制其中一个到相同目录,修改名字为“train_EDVR_OURS_M.yml”,然后修改如下——
。我们先复制其中一个到相同目录,修改名字为“train_EDVR_OURS_M.yml”,然后修改如下——
#### general settings
name: 001_EDVR_OURS # ** 实验名
use_tb_logger: true
model: VideoSR_base
distortion: sr
scale: 4
gpu_ids: [0] # ** 因为小编实验室比较羞涩,所以只能用一张卡训练哈~
#### datasets
datasets:
train:
name: REDS
mode: REDS
interval_list: [1] # 帧的采样频率,是: ..., t-2k, t-k, t, t+k, t+2k, ...
random_reverse: false
border_mode: false
dataroot_GT: ./../datasets/train_gt_wval.lmdb
dataroot_LQ: ./../datasets/train_input_wval.lmdb
# ** 修改训练数据的路径,指向上面我们生成的lmdb文件,因为这个命令是要给./EDVR/codes/train.py使用的,所以我们需要基于./EDVR/codes/去定义相对路径
cache_keys: meta_info.pkl # ** 前面我们复制的meta_info.pkl
N_frames: 5
use_shuffle: true
n_workers: 3 # per GPU
batch_size: 16 # ** batch size不要太大,不然一张卡吃不消,土豪实验室多卡分布请随意~
GT_size: 256
LQ_size: 256 # ** 注意在deblur任务中,输入与输出的size是一样的
use_flip: true
use_rot: true
color: RGB
#### network structures 网络结构
network_G:
which_model_G: EDVR
nf: 64
nframes: 5
groups: 8
front_RBs: 5
back_RBs: 10
predeblur: true # ** 是否使用一个预编码层,它的作用是对输入 HxW 经过下采样得到 H/4xW/4 的feature,以便符合后面的网络
HR_in: true # ** 很重要!!只要你的输入与输出是同样分辨率,就要求设置为true
w_TSA: true # ** 是否使用TSA模块
#### path
path:
pretrain_model_G: ~ # ~ 表示的是None
strict_load: true
resume_state: ~
#### training settings: learning rate scheme, loss
train:
lr_G: !!float 4e-4
lr_scheme: CosineAnnealingLR_Restart
beta1: 0.9
beta2: 0.99
niter: 600000
warmup_iter: -1 # -1: no warm up
T_period: [150000, 150000, 150000, 150000]
restarts: [150000, 300000, 450000]
restart_weights: [1, 1, 1]
eta_min: !!float 1e-7
pixel_criterion: cb
pixel_weight: 1.0
val_freq: !!float 2e3
manual_seed: 0
#### logger
logger:
print_freq: 10 # 每多少个iterations打印日志
save_checkpoint_freq: !!float 2e3 # 每多少个iterations保存模型完了后我们还有一处要修改,就是“./EDVR/codes/data/REDS_dataset.py”。
本项目读取数据的规则是:在前面部分将所有的数据封装成lmdb的形式,需要通过key(图片名,无后缀)进行读取;在dataset的__getitem__中,是先将所有的keys读入(就是前面我们需要自己准备的"meta_info.pkl"文件中的keys对应的值)),然后每次读取连续的几个keys,再经过_read_img_mc_BGR函数去获取图像数组
首先是45行附近的,
#### directly load image keys
if opt['cache_keys']:
# 这里获取了我们的meta_info.pkl,然后我们希望读入它
logger.info('Using cache keys: {}'.format(opt['cache_keys']))
cache_keys = opt['cache_keys']
else:
cache_keys = 'REDS_trainval_keys.pkl'
logger.info('Using cache keys - {}.'.format(cache_keys))
self.paths_GT = pickle.load(open('./data/{}'.format(cache_keys), 'rb'))["keys"]
# ** 在这里读入,但我们说了,我们的meta_info.pkl是一个字典,包含了
"""
name: "xxxxxxxxx",
resolution: "H_W_C"
keys: ["000000_000000", "000000_000001", ..., "000001_000000", "000001_000001", ...]
"""
# 所以最后我们只需要读入其中的keys对应的文件名列表就行下面小编将展示次工程比较不友好的一个地方。在函数__getitem__(self, index)中有一个坑,在大概158行附近。
...
#### get LQ images
LQ_size_tuple = (3, 180, 320) if self.LR_input else (3, 720, 1280)
img_LQ_l = []
for v in neighbor_list:
img_LQ_path = osp.join(self.LQ_root, name_a, '{:06d}.jpg'.format(v)) # ** 我们的数据格式是.jpg;同时图像命名是6位的xxxxxx格式
if self.data_type == 'mc':
if self.LR_input:
img_LQ = self._read_img_mc(img_LQ_path)
else:
img_LQ = self._read_img_mc_BGR(self.LQ_root, name_a, '{:06d}'.format(v)) # ** 图像命名是6位的xxxxxx格式
img_LQ = img_LQ.astype(np.float32) / 255.
elif self.data_type == 'lmdb':
img_LQ = util.read_img(self.LQ_env, '{}_{:06d}'.format(name_a, v), LQ_size_tuple) # ** 图像命名是6位的xxxxxx格式
else:
img_LQ = util.read_img(None, img_LQ_path)
img_LQ_l.append(img_LQ)
...其次则是在133行附近。
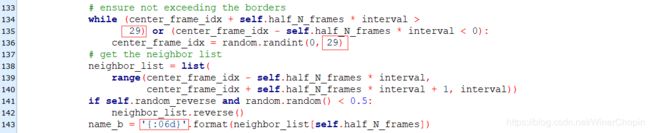
这里有几个数值我们需要修改:
1)上面的两个红框,原本的数值是99;这是因为作者用的训练数据每一个clip中含有100帧(xxxx_00000000, xxxx_00000001, ..., xxxx_00000099) ,为了保证不读取到两个clips的帧,需要对帧的索引做检查。我们准备的数据中每个clip的帧数是30,所以这里要设置成29.
2)假如读者使用与作者相同的命名格式:“xxxx_xxxxxxxx”,那么底下的框就不需要修改;但假如不是,像小编这里的命名是“xxxxxx_xxxxxx”,所以这里就需要改成“{:06d}”而不是原来的“{:08d}”。
这里最好奇的是,上面的“99”为什么不设置成一个超参数?
最后就是修改图像大小,在同样这个文件的以下地方——将图像大小改成我们自己数据的大小

5. 训练指令
训练的时候可能会发现数据编码的问题,注意代码中不能出现中文,Σ( ° △ °|||)︴!小编这里只是为了方便说明采用中文!
python -m torch.distributed.launch --nproc_per_node=2 --master_port=21688 train.py -opt options/train/train_EDVR_OURS_M.yml --launcher pytorch
## nproc_per_node 是指我们使用多少个子进程,这里是2,所以下图显示为2
## master_port 是主进程的pid,如果被占用了,就修改使用其他进程即可
好的,至此,训练完成。若有纰漏或错误,还请读者热情指出,十分感谢!