原生Hadoop集群搭建
作为小新,想搞一下大数据开发,那么首先要有大数据平台,本文将着手原生的Apache Hadoop集群搭建,从无到有的进行详细介绍,大神请略过~
一、安装VMWare Workstation 10
VMware Workstation(中文名“威睿工作站”)是一款功能强大的桌面虚拟计算机软件,提供用户可在单一的桌面上同时运行不同的操作系统,和进行开发、测试 、部署新的应用程序的最佳解决方案。
下载略过~
在软件包中找到“环境\VMware”目录并进入该目录,如下所示:

点击“VMware-workstation-full-10.0.0-1295980.exe”安装
 2
2
等待安装软件检测和解压以后,出现如下界面,直接单击下一步即可。

选择我同意选项,直接下一步。

典型安装和自定义安装,可根据自己的情况酌情选择。这里我们选择自定义安装。
 5
5
选择自定义以后,根据自己的情况选择自己需要的功能。这里我们选择全部。
 6
6
我们可以更改软件的安装路径,端口默认即可。
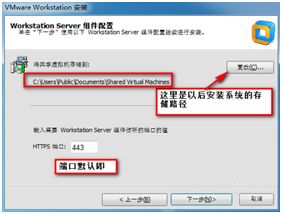 7
7
出现如下图的选择框框,一般不建议勾选 。
 8
8
出现下图提示选择默认的即可。
 9
9
单击下一步,即可安装。
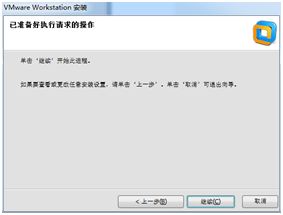
点击“继续”按钮
 10
10
软件安装成功,如下图所示。

安装完成后,要求输入注册码,打开压缩文件中的算号器

拷贝粘贴注册码
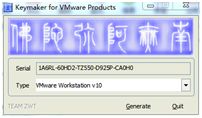
输入注册码:

点击输入后,出现:

点击完成,VMware安装过程结束。
二、VMware 10安装CentOS 6
准备好镜像文件
![]()
打开VMware Workstation 10

点击 文件->新建虚拟机

选择 典型(推荐)(T) 选项,点击“下一步(N) >”
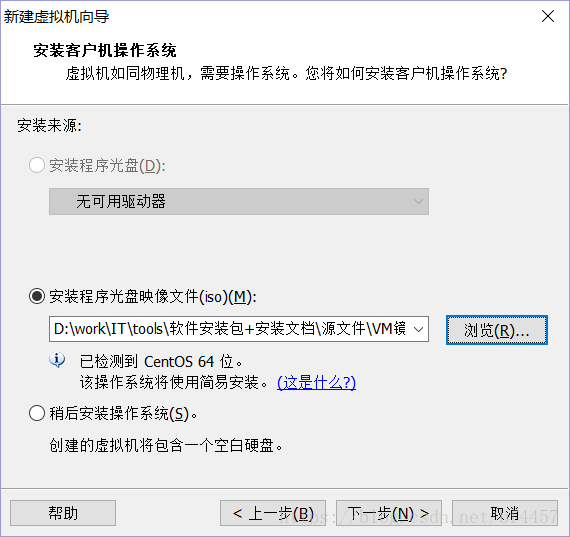
选择 安装程序光盘映像文件(iso)(M) ,选择指定的CentOS系统的.iso文件,点击“下一步(N) >”
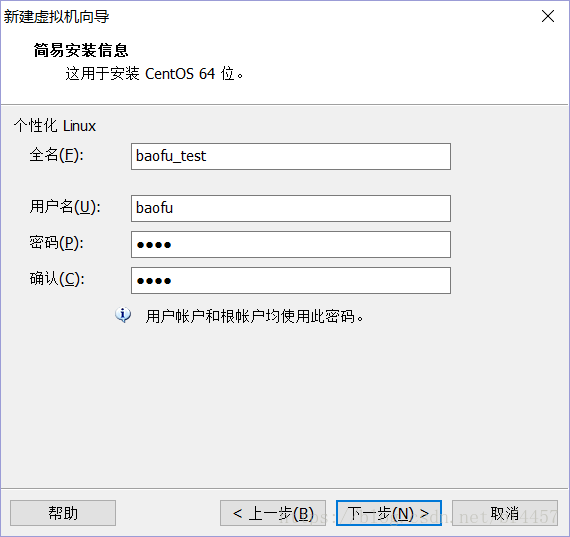
填写下面的信息,点击“下一步(N) >”,

虚拟机名称(V):baofu_test,选择安装位置,点击“下一步(N) >”

这里的磁盘大小不要直接使用默认值,要调大该值,设置为40.0,点击“下一步(N) >”
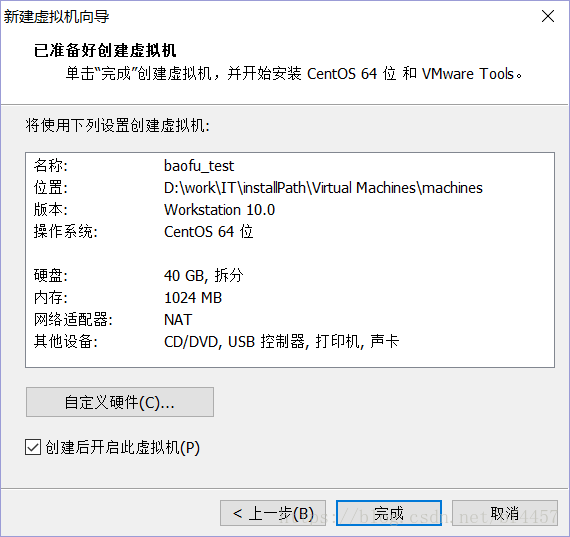
点击“完成”,正常情况下,安装CentOS6进入下面的界面:

这个时候鼠标就已经点击到Centos系统,如果想切换出来,同时按一下【Ctrl+Alt】,就可以把鼠标移到Windows。
直接等待安装完成,系统自动重启


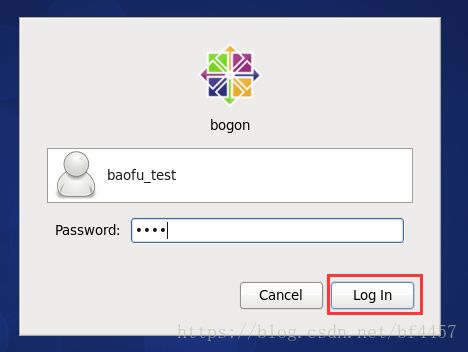
输入密码,登录进系统

至此,CentOS系统安装完毕。
【安装中的关键问题】
如果出现下面的界面,说明BIOS中没有打开VT-x功能,所以就不能用VT-x进行加速。
打开BIOS中的VT-x功能的操作如下:
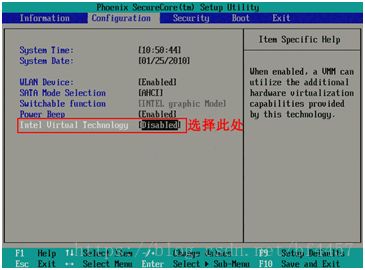
首先在开机自检Logo处按F2热键(不同品牌的电脑进入BIOS的热键不同,有的电脑是F1\F8\F12)进入BIOS,选择Configuration选项,选择Intel Virtual Technology并回车,如下图:
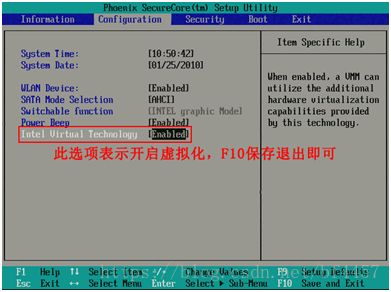
将光标移动至Enabled处,并回车确定,如下图:

此时该选项将变为Enabled,最后按F10热键保存并退出即可开启VT功能,如下图:
----------------------------------------------
Insyde BIOS机型的参考操作方法:(以Lenovo 3000 G460作为操作平台)
首先在开机自检Logo处按F2热键进入BIOS,选择Configuration选项,选择Intel Virtual Technology并回车,如下图:
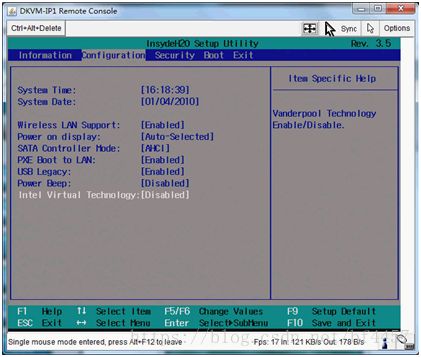
将光标移动至Enabled处,并回车确定,如下图:

此时该选项将变为Enabled,最后按F10热键保存并退出即可开启VT功能,如下图:
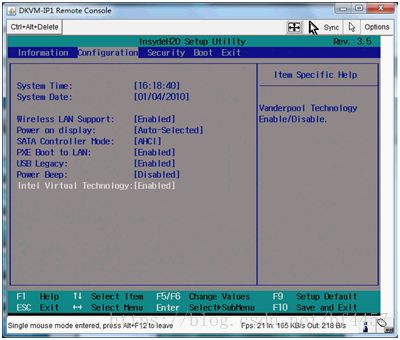
如果修改该BIOS选项之后,仍然出现提示VT-x没有打开的情况,需要重启电脑重试。
三、CentOS 6安装Hadoop
重复上边的第二步,再新建两台虚拟机我们选择其中一个作为主节点,另外两个作为从节点,自己要区分清楚。我这里用baofu3作为主节点,baofu4、baofu5作为从节点。
ps:集群节点的用户名要保持一致,这样可以同步命令
ps:建三台空的虚拟机是因为hadoop的zookeeper有选举机制,所以节点数量一定要是奇数个(hadoop2.0以后引入HA,但是两个或者更多个主节点,也只有一个在运行,其余的在备用,所以实际还是2n+1台节点在运行)
3.1启动三台虚拟客户机
打开VMware Workstation10,启动三台节点。

3.2 Linux系统配置
本节所有的命令操作都在终端环境,打开终端的过程如下图的Terminal菜单,终端打开后如下图中命令行窗口所示。
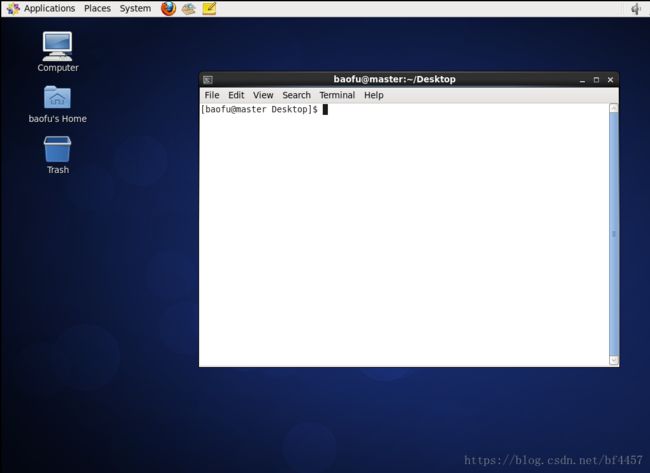
以下操作步骤需要三个节点上分别完整操作,都使用root用户,从当前用户切换root用户的命令如下:
[baofu@master ~]$ su root输入密码:root
3.2.1配置时钟同步
1、配置自动时钟同步
使用Linux命令配置
[root@master ~]$ crontab -e该命令是vi编辑命令,按i进入插入模式,按Esc,然后键入:wq保存退出
键入下面的一行代码,输入i,进入插入模式(星号之间和前后都有空格)
0 1 * * * /usr/sbin/ntpdate cn.pool.ntp.org2、手动同步时间
直接在Terminal运行下面的命令:
[root@master ~]$/usr/sbin/ntpdate cn.pool.ntp.org3、直接右上角设置


remove原有的然后add新的
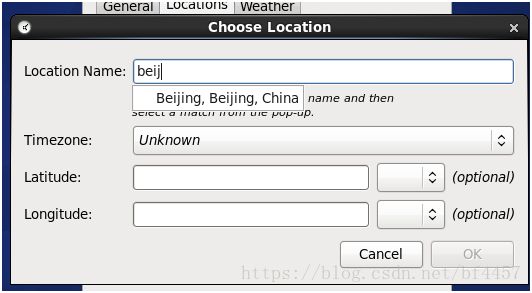
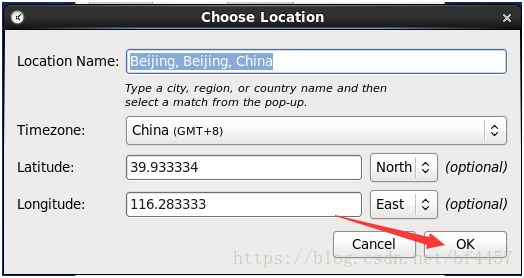
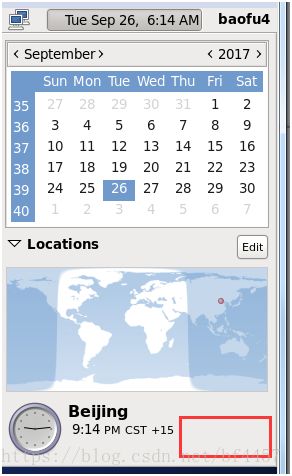
这个红框位置晃鼠标找到set单击,然后输当前用户密码,授权修改。
在另外两个节点配置时间。
3.2.2配置主机名
1、Master节点
使用gedit编辑主机名,如果不可以使用gedit,请直接使用vi编辑器(后面用到gedit的地方也同此处处理一致)。
[root@master ~]# vim /etc/sysconfig/network配置信息如下,如果已经存在则不修改,将Master节点的主机名改为master,即下面代码的第2行所示。
NETWORKING=yes #启动网络
HOSTNAME=master #主机名
确实修改生效命令(这里是临时修改,就不用重启了,之前修改的重启才会生效):
[root@master ~]#hostname master检测主机名是否修改成功命令如下,在操作之前需要关闭当前终端,重新打开一个终端:
[root@master ~]# hostname
执行完命令,会看到下图的打印输输出:

2、两个Slave节点
做同样操作,将两个slave节点的主机名改为slave1和slave2,修改完记得检查~


3.2.3使用setup 命令配置网络环境
在终端中执行下面的命令:
[root@master ~]# ifconfig如果看到下面的打印输出

如果看到出现红线标注部分出现,即存在内网IP、广播地址、子网掩码,说明该节点不需要配置网络,否则进行下面的步骤。
在终端中执行下面命令:
[root@master ~]# setup会出现下图中的内容:使用光标键移动选择“Network configuration”,回车进入该项

回车进入“Device configuration”
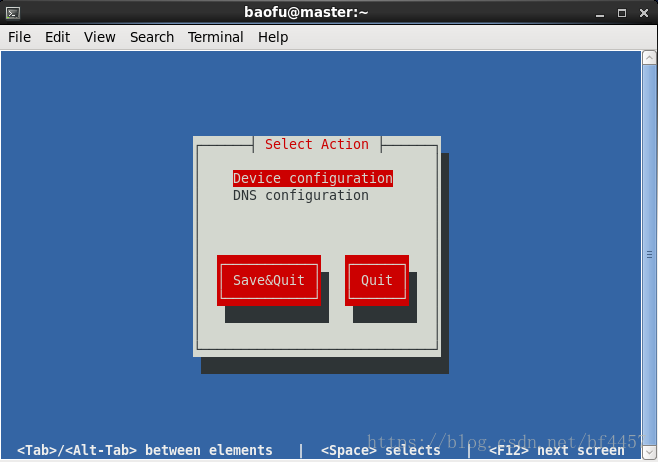
回车进入“eth0……”

按照图中的方式输入各项内容

保存退出:Ok-->Save-->Save&Quit-->Quit
重启网络服务
[root@master ~]# /sbin/service network restart检查是否修改成功:
[root@master ~]# ifconfig看到如下图的内容(IP不一定和下图相同,根据你之前的配置),说明配置成功,特别关注红线部分
在另外两个Slave节点配置网络。
3.2.4关闭防火墙
在终端中执行下面命令:
[root@master ~]# setup会出现下图中的内容:光标移动选择“Firewall configuration”选项,回车进入选项

如果【Enabled】前面有 [*] 标,则按一下空格键关闭防火墙,如下图所示,然后光标移动选择“OK”保存修改内容

选择OK-->yes-->quit
在两个Slave节点关闭防火墙。
3.2.5配置hosts列表
需要在root用户下编辑主机名列表,命令:
[root@master ~]# vim /etc/hosts将下面两行添加到/etc/hosts文件中:
192.168.232.128 master
192.168.232.129 slave1
192.168.232.130 slave2
注意:自己在做配置时,需要将IP地址改为你的master和slave对应的IP地址,不能照抄照搬。
查看IP地址使用下面的命令:
[root@master ~]# ifconfig验证是否配置成功,命令:
[root@master ~]# ping master
如果出现下图的信息表示配置成功:

ps:按【Ctrl+c】结束ping,不然会一直ping。
修改两个slave节点的/etc/hosts文件,之后三个节点分别互相ping通,进行下一步【免秘钥】。
如果出现下图的内容,表示配置失败:

ps:当你要ping的主机名不在/etc/hosts文件中,就会报【未知的主机】,细心检查即可,一般都不会错的
3.2.6免密钥登录配置
免秘钥的个人理解:a的authorized_keys在b的家里,a访问b就不用输密码了
该部分所有的操作都要在baofu用户下,切换回baofu,命令是:
[root@master ~]# su baofu
![]()
ps:root可以切换到任何用户,不需要密码。
ps:免秘钥登录是哪个用户配置哪个用户生效,使用过程中,基本不用root用户,而是根据实际开发使用对应的个人账户
ps:集群只需要master可以随意访问slave就够了
Master节点在终端生成密钥,命令如下
[baofu@master ~]$ ssh-keygen -t rsa(一路点击回车生成密钥)
生成的密钥在.ssh目录下如下图所示:

复制公钥文件生成authorized_keys,名字一定别写错
[baofu@master .ssh]$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys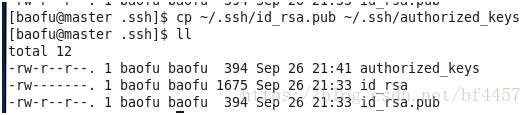
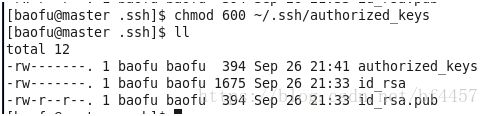
为了安全起见,修改authorized_keys文件的权限,命令如下:
[baofu@master .ssh]$ chmod 600 ~/.ssh/authorized_keys修改完权限后,文件列表情况如下:
将authorized_keys文件复制到两个slave节点,命令如下:
本机之间复制是cp,不同节点之间是scp
[baofu@master .ssh]$ scp ~/.ssh/authorized_keys baofu@slave1:~/
[baofu@master .ssh]$ scp ~/.ssh/authorized_keys baofu@slave2:~/如果提示输入yes/no的时候,输入yes,回车
密码是:root
两个slave生成秘钥
[baofu@slave1 ~]$ ssh-keygen -t rsa一定先有.ssh文件再移动,---ls -a,将authorized_keys文件移动到.ssh目录
[baofu@slave1 ~]$ mv authorized_keys ~/.ssh/slave2做同样处理,验证免秘钥登录,如果出现下图的内容表示免密钥配置成功:


ps:不行的话,重新登录两个用户
--------------------------------------------------到这里,基本准备就完成了,开始搭建环境--------------------------------------------------
3.2.7安装JDK
把jdk复制到Linux系统(直接拖动或者使用WinSCP工具)
![]()
新建文件夹/usr/java,然后移动压缩包,放到/usr/java目录下,然后将JDK文件解压,
[root@master ~]# mkdir /usr/java/
[root@master ~]# mv /home/baofu/Desktop/jdk-8u101-linux-x64.tar.gz /usr/java/
#最后的/一定不要丢
[root@master ~]# cd /usr/java/
[root@master java]# tar -xvf baofu/jdk-8u101-linux-x64.tar.gz
配置环境变量(先su切换回普通用户,因为profile文件只对当前用户有效)
[baofu@master ~]$ vim ~/.bash_profile复制粘贴以下内容添加到到.bash_profile文件中(ps:自己的路径要对应过来,jdk解压的路径):
export JAVA_HOME=/usr/java/jdk1.8.0_101
export PATH=$JAVA_HOME/bin:$PATH效果:

使改动生效命令:
[baofu@master ~]$ source ~/.bash_profile测试配置:
[baofu@master ~]$ java -version如果出现下图的信息,表示JDK安装成功:

从节点配置java(使用命令将java复制到Slave上,因为之前已经配置了免密钥登录,这里可以直接远程复制):
[baofu@master hadoop]$ cd
[baofu@master ~]$ scp -r /usr/java baofu@slave1:~/
[baofu@master ~]$ scp -r /usr/java baofu@slave2:~/再发送.bash_profile配置文件
[baofu@master ~]$ scp ~/.bash_profile baofu@slave1:~/
[baofu@master ~]$ scp ~/.bash_profile baofu@slave2:~/从节点上,先把收到的java放到/usr下边(切换到root用户)
[baofu@slave1 ~]$ su #输密码
[baofu@slave1 ~]$ mv /home/baofu/java /usr/
[baofu@slave1 ~]$ su baofu
[baofu@slave1 ~]$ source ~/.bash_profile #使配置文件生效
[baofu@slave1 ~]$ java -version #查看版本如果出现下图的信息,表示JDK安装成功:

slave2做同样处理~

----------------------------------------------------正题来啦,终于写到Hadoop部分了----------------------------------------------------
3.3 Hadoop配置部署
下面所有的操作都使用baofu用户,切换baofu用户的命令是:
[root@master baofu]# su baofu3.3.1 Hadoop安装包解压
把压缩包复制到Linux系统baofu用户的主目录下(直接拖动或者使用WinSCP工具)
![]()
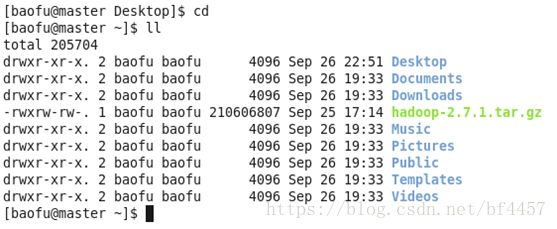
解压Hadoop安装包命令如下:
[baofu@master ~]$ tar -zxvf hadoop-2.7.1.tar.gzls -l看到如下图的内容,表示解压成功:

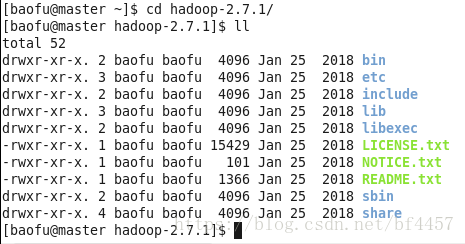
进入hadoop文件夹
[baofu@master ~]$ cd hadoop-2.7.1
[baofu@master hadoop-2.7.1]$ ll
看到如下图的内容,表示解压成功:
3.3.2配置环境变量hadoop-env.sh
(以下修改也可以用Notepad++远程连接修改,方便、视觉效果好)
改变路径找环境变量文件,只需要配置JDK的路径。
[baofu@master ~]$ cd hadoop-2.7.1/etc/hadoop/
[baofu@master hadoop]$ vim hadoop-env.sh 在文件的靠前的部分找到下面的一行代码:
export JAVA_HOME=${JAVA_HOME}将这行代码修改为下面的代码:
export JAVA_HOME=/usr/java/jdk1.8.0_101
然后保存文件(“Esc”退到命令行模式,输入“:wq” , 回车)。
3.3.3配置环境变量yarn-env.sh
环境变量文件中,只需要配置JDK的路径。
[baofu@master hadoop]$ vim yarn-env.sh在文件的靠前的部分找到下面的一行代码:第23行
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/将这行代码修改为下面的代码(将#号去掉):
export JAVA_HOME=/usr/java/jdk1.8.0_101然后保存文件。
3.3.4配置核心组件core-site.xml
使用vim编辑:
[baofu@master hadoop]$ vim core-site.xml注意
注意
修改内容如下:
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/home/baofu/hadoopdata
3.3.5配置文件系统hdfs-site.xml
(hdfs的副本数)
[baofu@master hadoop]$ vim hdfs-site.xml修改内容如下:
dfs.replication
1
3.3.6配置文件系统yarn-site.xml
看自己主机名是不是master
[baofu@master hadoop]$ vim yarn-site.xml修改内容如下:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
master:18040
yarn.resourcemanager.scheduler.address
master:18030
yarn.resourcemanager.resource-tracker.address
master:18025
yarn.resourcemanager.admin.address
master:18141
yarn.resourcemanager.webapp.address
master:18088
3.3.7配置计算框架mapred-site.xml
因为没有mapred-site-template.xml,所以得先复制
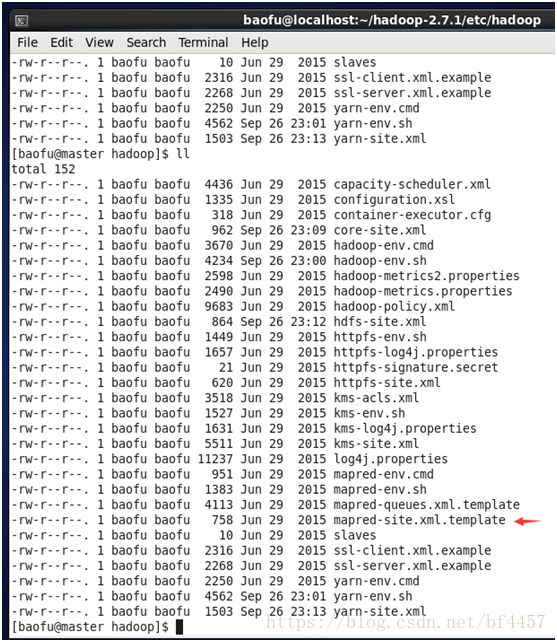
复制mapred-site-template.xml文件:
[baofu@master hadoop]$ cp mapred-site.xml.template mapred-site.xml
(ps:如果用notepad++编辑,需要刷新)
使用vim编辑:
[baofu@master hadoop]$ vim mapred-site.xml修改内容如下:
mapreduce.framework.name
yarn
3.3.8 在master节点配置slaves文件
使用vim编辑:
[baofu@master hadoop]$ vim slaves从节点的主机名,一行一个,多个回车换行写
注意 不能有空格和回车 单行单个回车会被认为是名为””的用户、“baofu “不是baofu用户,而是”baofu+空格”用户
用下面的代码替换slaves中的内容:
slave1
slave2ps:slave节点也配,依旧写从节点名称,这里编辑完一会儿直接复制,不需要再修改
3.3.9 复制到从节点
使用下面的命令将已经配置完成的Hadoop复制到从节点上:
[baofu@master hadoop]$ cd
[baofu@master ~]$ scp -r hadoop-2.7.1 baofu@slave1:~/
[baofu@master ~]$ scp -r hadoop-2.7.1 baofu@slave2:~/ps:因为之前已经配置了免密钥登录,这里可以直接远程复制。
3.4 启动Hadoop集群
下面所有的操作都使用baofu用户(su baofu):
3.4.1 配置Hadoop启动的系统环境变量
该节的配置需要同时在三个节点上进行操作,操作命令如下:
[baofu@master ~]$ vim ~/.bash_profile将下面的代码追加到.bash_profile末尾:
#HADOOP
export HADOOP_HOME=/home/baofu/hadoop-2.7.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH然后执行命令:
[baofu@master ~]$ source ~/.bash_profile3.4.2 启动Hadoop集群
1、格式化文件系统
ps:不论几个节点,只格式化master、只格式化master、只格式化master
[baofu@master ~]$ hdfs namenode -format看到下图的打印信息表示格式化成功,如果出现Exception/Error,则表示出问题:
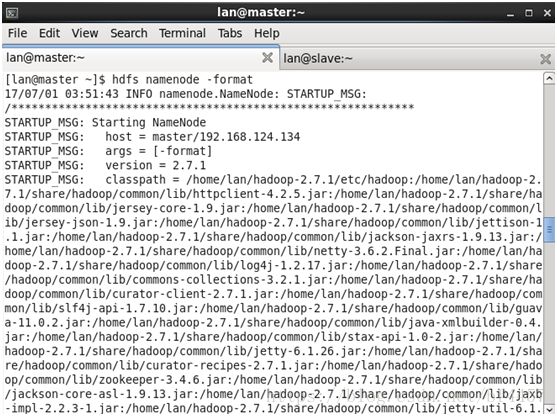
2、启动Hadoop
使用start-all.sh启动Hadoop集群,首先进入Hadoop安装主目录,然后执行启动命令:
[baofu@master ~]$ cd ~/hadoop-2.7.1
[baofu@master hadoop-2.7.1]$ sbin/start-all.sh执行命令后,提示出入yes/no时,输入yes。
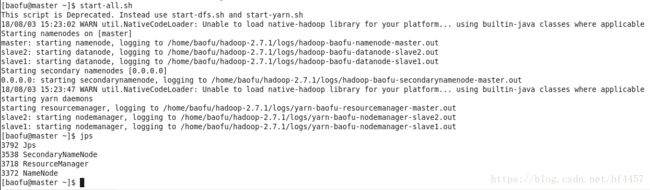
3、查看进程是否启动
在Master的终端执行jps命令,在打印结果中会看到4个进程,分别是ResourceManager、Jps、NameNode和SecondaryNameNode,如下图所示。如果出现了这4个进程表示主节点进程启动成功。
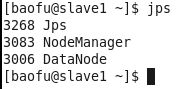
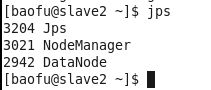
在Slave的终端执行jps命令,在打印结果中会看到3个进程,分别是NodeManager、DataNode和Jps,如下图所示。如果出现了这3个进程表示从节点进程启动成功。
假如DataNode进程没启动起来,可以尝试以下方式:
a)单进程启动
./hadoop-daemon.sh start datanode
b)终极方法,在实际开发中要慎用
./stop-all.sh 终止hadoop的进程
在用户目录下,通过rm -rf hadoopdata
将/home/tg/datas/hadoop路径下的logs目录删掉
rm -rf logs
重新格式化 hadoop namenode -format
格式化的目的,就的创建namenode的文件结构
格式化之后再重新启动,./start-all.sh
4、Web UI查看集群是否成功启动
在Master上启动Firefox浏览器,在浏览器地址栏中输入输入http://master:50070/,检查 namenode 和 datanode 是否正常。UI页面如下图所示。

在浏览器地址栏中输入输入http://master:18088/,检查 Yarn是否正常,页面如下图所示。

5、运行PI实例检查集群是否成功(运行时间不短,耐心等结果,内存小的电脑不要运行10 10,可以运行2 2,能出结果即可)
ps:此处是采用 Quasi-Monte Carlo 算法来估算PI的值,第一个10是指运行10次map任务,第二个10是指每个map要投掷10次。运行次数乘以每次投掷次数等于总次数,总次数越大越接近π的真实值。
[baofu@master ~]$ cd /home/baofu/hadoop-2.7.1/share/hadoop/mapreduce
[baofu@master mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.1.jar pi 10 10会看到如下的执行结果:

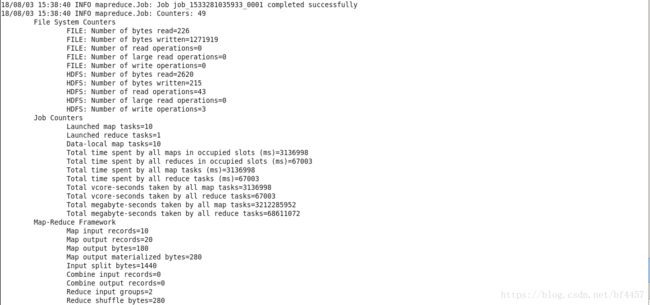

最后输出:
Estimated value of Pi is 3.20000000000000000000
如果以上的3个验证步骤都没有问题,说明集群正常启动。