Elasticsearch(二)elasticsearch索引数据与简单检索GET一个文档
本文参考elasticsearch权威指南。
是一个学习笔记,按照里面的示例进行学习,在此记录跟踪。
与elasticsearch交互的两种方式
JAVA API
如果你和我一样,使用java,在代码中你可以使用 Elasticsearch 内置的两个客户端:
节点客户端(Node client)
节点客户端作为一个非数据节点加入到本地集群中。换句话说,它本身不保存任何数据,但是它知道数据在集群中的哪个节点中,并且可以把请求转发到正确的节点。
传输客户端(Transport client)
轻量级的传输客户端可以可以将请求发送到远程集群。它本身不加入集群,但是它可以将请求转发到集群中的一个节点上。
两个 Java 客户端都是通过 9300 端口并使用本地 Elasticsearch 传输 协议和集群交互。集群中的节点通过端口 9300 彼此通信。如果这个端口没有打开,节点将无法形成一个集群。
PS:Java 客户端作为节点必须和 Elasticsearch 有相同的 主要 版本;否则,它们之前将无法互相理解。即客户端使用的版本要与服务器相对应。
推荐使用传输客户端,下面是一个连接客户端的小例子:
Settings settings = Settings.builder().put("cluster.name", "bdrg")//集群名称
.put("client.transport.sniff", true)//sniff功能
.put("client.transport.ping_timeout","100s")//连接超时
.build();
TransportClient client = new PreBuiltTransportClient(settings).addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9300));//连接IP和PORT
RESTFUL API WITH JSON OVER HTTP
所有其他语言可以使用 RESTful API 通过端口 9200 和 Elasticsearch 进行通信,你可以用你最喜爱的 web 客户端访问 Elasticsearch 。事实上,正如你所看到的,你甚至可以使用 curl 命令来和 Elasticsearch 交互。
Elasticsearch 为以下语言提供了官方客户端 –Groovy、JavaScript、.NET、 PHP、 Perl、 Python 和 Ruby–还有很多社区提供的客户端和插件,所有这些都可以在 Elasticsearch Clients 中找到。
一个 Elasticsearch 请求和任何 HTTP 请求一样由若干相同的部件组成:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'被 < > 标记的部件:
VERB :
适当的 HTTP 方法 或 谓词 : GET、POST、PUT、HEAD 或者 DELETE。
PROTOCOL:
http 或者 https(如果你在 Elasticsearch 前面有一个https 代理)
HOST :
Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点。
PORT :
运行 Elasticsearch HTTP 服务的端口号,默认是 9200 。
PATH :
API 的终端路径(例如 _count 将返回集群中文档数量)。Path 可能包含多个组件,例如:_cluster/stats 和 _nodes/stats/jvm 。
QUERY_STRING :
任意可选的查询字符串参数 (例如 ?pretty 将格式化地输出 JSON 返回值,使其更容易阅读)
BODY :
一个 JSON 格式的请求体 (如果请求需要的话)
例如,计算集群中文档的数量,我们可以用这个:
curl -XGET 'http://localhost:9200/_count?pretty' -d '
{
"query": {
"match_all": {}
}
}
Elasticsearch 返回一个 HTTP 状态码(例如:200 OK)和(除HEAD请求)一个 JSON 格式的返回值。前面的curl 请求将返回一个像下面一样的 JSON 体:
{
"count" : 0,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
}
}
在返回结果中没有看到 HTTP 头信息是因为我们没有要求curl显示它们。想要看到头信息,需要结合-i 参数来使用 curl 命令:
curl -i -XGET 'localhost:9200/'面向文档
假如一个User对象其中包含了另一个地址对象,关系型数据库不能放在一个地方,需要放在另一张表中。elasticsearch却吧User包含的地址也放在User当中,因为它根据文档来索引数据。
对文档进行索引、检索、排序和过滤–而不是对行列数据。这是一种完全不同的思考数据的方式,也是 Elasticsearch 能支持复杂全文检索的原因。
例如一个JSON 文档,它代表了一个 user 对象:
{
"email": "[email protected]",
"first_name": "John",
"last_name": "Smith",
"info": {
"bio": "Eco-warrior and defender of the weak",
"age": 25,
"interests": [ "dolphins", "whales" ]
},
"join_date": "2014/05/01"
}
虽然原始的 user 对象很复杂,但这个对象的结构和含义在 JSON 版本中都得到了体现和保留。在 Elasticsearch 中将对象转化为 JSON 并做索引要比在一个扁平的表结构中做相同的事情简单的多。
几乎所有的语言都有相应的模块可以将任意的数据结构或对象 转化成 JSON 格式,只是细节各不相同。具体请查看 serialization 或者 marshalling 这两个 处理 JSON 的模块。官方 Elasticsearch 客户端 自动为您提供 JSON 转化。
下面是一个elasticsearch自动提供json转化的示例:
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.field("vehicleId", "BCAAAD0005")
.endObject();
String json4 = builder.string();
System.out.println(json4);
显示如下:
{"vehicleId":"BCAAAD0005"}接下来我们学习怎样操作数据,以一个雇员目录为例:
我们受雇于 Megacorp 公司,作为 HR 部门新的 “热爱无人机” (“We love our drones!”)激励项目的一部分,我们的任务是为此创建一个雇员目录。该目录应当能培养雇员认同感及支持实时、高效、动态协作,因此有一些业务需求:
• 支持包含多值标签、数值、以及全文本的数据
• 检索任一雇员的完整信息
• 允许结构化搜索,比如查询 30 岁以上的员工
• 允许简单的全文搜索以及较复杂的短语搜索
• 支持在匹配文档内容中高亮显示搜索片段
• 支持基于数据创建和管理分析仪表盘
创建雇员文档
也称索引雇员文档。
第一个业务需求就是存储雇员数据。 这将会以 雇员文档 的形式存储:一个文档代表一个雇员。存储数据到 Elasticsearch 的行为叫做 索引 ,但在索引一个文档之前,需要确定将文档存储在哪里。
一个 Elasticsearch 集群可以 包含多个 索引(类比数据库) ,相应的每个索引可以包含多个 类型 (类比表)。 这些不同的类型存储着多个 文档 (类比数据),每个文档又有 多个 属性 (类比字段)。
对于雇员目录,我们将做如下操作:
• 每个雇员索引一个文档,包含该雇员的所有信息。
• 每个文档都将是 employee 类型 。
• 该类型位于 索引 megacorp 内。
• 该索引保存在我们的 Elasticsearch 集群中。
实践中这非常简单(尽管看起来有很多步骤),我们可以通过一条命令完成所有这些动作:
PUT /megacorp/employee/1
{
“first_name” : “John”,
“last_name” : “Smith”,
“age” : 25,
“about” : “I love to go rock climbing”,
“interests”: [ “sports”, “music” ]
}
注意,路径 /megacorp/employee/1 包含了三部分的信息:
megacorp 索引名称
employee 类型名称
1 特定雇员的ID
请求体 —— JSON 文档 —— 包含了这位员工的所有详细信息,他的名字叫 John Smith ,今年 25 岁,喜欢攀岩。
很简单!无需进行执行管理任务,如创建一个索引或指定每个属性的数据类型之类的,可以直接只索引一个文档。Elasticsearch 默认地完成其他一切,因此所有必需的管理任务都在后台使用默认设置完成。
进行下一步前,让我们增加更多的员工信息到目录中:
PUT /megacorp/employee/2
{
“first_name” : “Jane”,
“last_name” : “Smith”,
“age” : 32,
“about” : “I like to collect rock albums”,
“interests”: [ “music” ]
}
PUT /megacorp/employee/3
{
“first_name” : “Douglas”,
“last_name” : “Fir”,
“age” : 35,
“about”: “I like to build cabinets”,
“interests”: [ “forestry” ]
}
用客户端连接的方式完成以上操作的示例
POM文件
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>3.8.1version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>transportartifactId>
<version>5.3.0version>
dependency>
<dependency>
<groupId>org.apache.logging.log4jgroupId>
<artifactId>log4j-coreartifactId>
<version>2.9.1version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-coreartifactId>
<version>2.8.6version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-databindartifactId>
<version>2.8.6version>
dependency>
<dependency>
<groupId>com.fasterxml.jackson.coregroupId>
<artifactId>jackson-annotationsartifactId>
<version>2.8.6version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.8version>
dependency>
dependencies>
其中如果你的elasticsearch服务器没有对应的客户端传输org.elasticsearch.client,请使用类似于2.0.0版本的依赖。
initData.java–客户端连接
public class InitialData {
private static Logger logger = (Logger) LogManager.getLogger(InitialData.class);
/**
* 获得连接
* @param clusterName 集群名称
* @param sniff 是否增加嗅探功能
* @param time 设定超时时间
* @param ip 连接IP
* @param port 连接port,传输端口一般都是9300
* @return
* @throws UnknownHostException
*/
public static Client connect(String clusterName,boolean sniff,int time,String ip,int port) throws UnknownHostException {
//集群名称 -- 默认"elasticsearch"
String cluster = null;
if(null == clusterName || ("").equals(clusterName.trim())) {
cluster = "elasticsearch";
}else {
cluster = clusterName;
}
//是否增加嗅探功能
//连接超时时间 -- 最小5s
if(time < 5) {
time = 5;
}
Settings settings = Settings.builder().put("cluster.name", cluster)//集群名称
.put("client.transport.sniff", sniff)//sniff功能
.put("client.transport.ping_timeout",time+"s")//连接超时时限
.build();
TransportClient client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(ip),port));//连接IP和PORT
logger.info("连接成功...");
return client;
}
}
ClientDemo2 .java–模拟雇员示例
public class ClientDemo2 {
/*
* 索引雇员文档,相当于我们传统数据库的insert操作
* 对于雇员目录,我们将做如下操作:
每个雇员索引一个文档,包含该雇员的所有信息。 --doc
每个文档都将是 employee 类型 。 --type
该类型位于 索引 megacorp 内。 --index
该索引保存在我们的 Elasticsearch 集群中。
*/
private static void insertEmployee (Client client) throws Exception{
//1.插入第一个员工,员工id为1,插在当前集群下的megacorp索引(类比数据库)employee类型(类比表)下
IndexResponse response = client.prepareIndex("megacorp","employee","1")//index type id(表特定雇员)
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("first_name","John")
.field("last_name","Smith")
.field("age",25)
.field("about","I love to go rock climbing")
.array("interests", new String[] {"sports","music"})
.endObject()).get();
//索引名称
String _index = response.getIndex();
//键入名称
String _type = response.getType();
//文件ID(生成与否)
String _id = response.getId();
//版本(如果这是您首次索引此文档,您将获得:1)--- 每次执行版本数都会+1
long _version = response.getVersion();
// status has stored current instance statement。
RestStatus status = response.status();
System.out.println("index:"+_index+";type:"+_type+";id:"+_id+";version:"+_version+";status:"+status);//
System.out.println(response.getResult().toString());//第一次执行是CREATED,同一个id第二次开始是UPDATED
//2.插入第二个员工
//你也可以手工写入自己的json
String json ="{"+
"\"first_name\":\"Jane\","+
"\"last_name\":\"Smith\","+
"\"age\":\"32\","+
"\"about\":\"I like to collect rock albums\","+
"\"interests\":[\"music\"]"+
"}";
IndexResponse response2 = client.prepareIndex("megacorp","employee","2")
.setSource(json,XContentType.JSON)
.get();
System.out.println(response2.getResult().toString());//CREATED
//3.插入第三个员工,不想获得结果可以直接调用
client.prepareIndex("megacorp","employee","3")//index type id(表特定雇员)
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("first_name","Douglas")
.field("last_name","Fir")
.field("age",35)
.field("about","I like to build cabinets")
.array("interests", "forestry")
.endObject()).get();
}
public static void main(String[] args) {
// 获得客户端连接
Client client = null;
try {
client = InitialData.connect("bdrg", true, 100, "127.0.0.1", 9300);
// 1.索引雇员文档
insertEmployee (client);
} catch (UnknownHostException e) {
System.out.println("服务器地址错误:"+e.getMessage());
} catch (Exception e) {
System.out.println("客户端操作错误:"+e.getMessage());
e.printStackTrace();
} finally {
// 关闭客户端
if(null != client) {
client.close();
}
}
}
}
可以多次执行,插入操作第一次会执行插入,第二次或以上会执行为更新操作。
结果显示:
no modules loaded
loaded plugin [org.elasticsearch.index.reindex.ReindexPlugin]
loaded plugin [org.elasticsearch.percolator.PercolatorPlugin]
loaded plugin [org.elasticsearch.script.mustache.MustachePlugin]
loaded plugin [org.elasticsearch.transport.Netty3Plugin]
loaded plugin [org.elasticsearch.transport.Netty4Plugin]
连接成功…
index:megacorp;type:employee;id:1;version:5;status:OK
UPDATED
UPDATED
Head插件操作示例
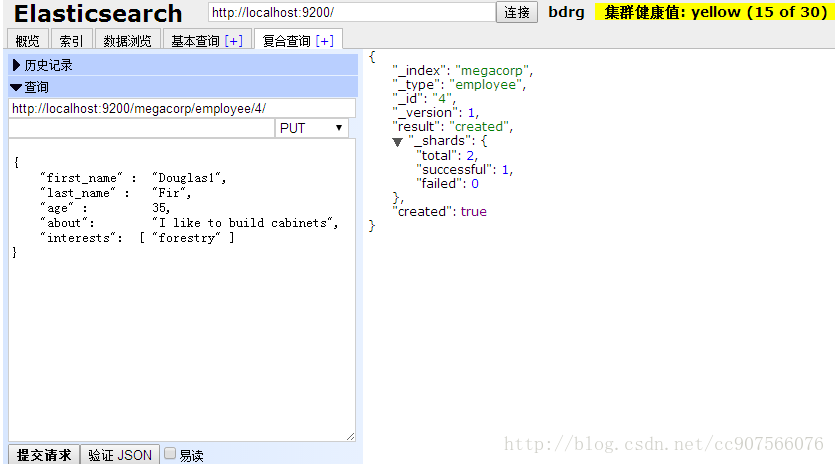
再次点击:
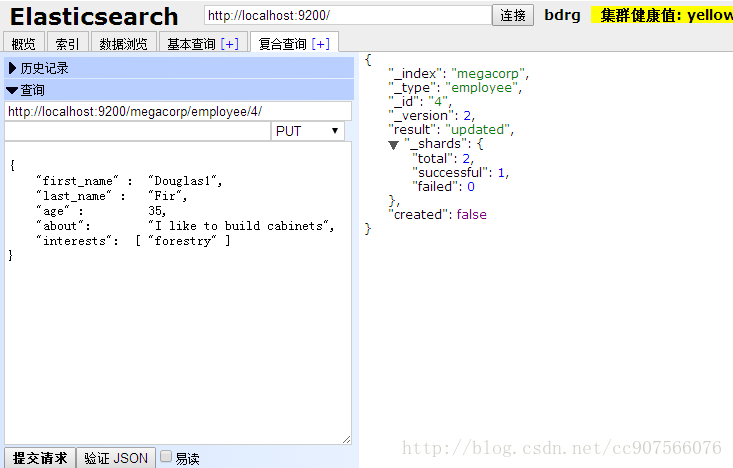
看我们索引中的数据:
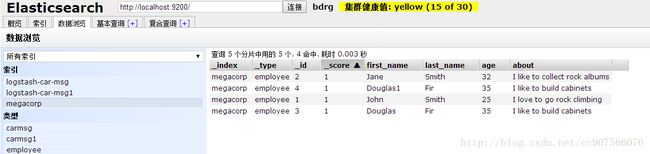
我们的interets数据呢?

(还可以选择json格式的,只有table格式的出不来)
它没有表示成一个字段显示出来。也很符合逻辑。
简单检索一个文档
目前我们已经在 Elasticsearch 中存储了一些数据, 接下来就能专注于实现应用的业务需求了。第一个需求是可以检索到单个雇员的数据。
这在 Elasticsearch 中很简单。简单地执行 一个 HTTP GET 请求并指定文档的地址——索引库、类型和ID。 使用这三个信息可以返回原始的 JSON 文档:
GET /megacorp/employee/1返回结果包含了文档的一些元数据,以及 _source 属性,内容是 John Smith 雇员的原始 JSON 文档:
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
}
用客户端连接的方式完成以上操作的示例
接着上一个示例中写,我们增加一个检索方法:
main方法中增加调用
// 1.索引雇员文档
//insertEmployee(client);
// 2.简单检索一个文档 GET
getOneEmployee(client,"megacorp","employee","1");
增加的方法
/* 简单检索一个文档 GET
* 简单地执行 一个 HTTP GET 请求并指定文档的地址——索引库、类型和ID。 使用这三个信息可以返回原始的 JSON 文档:
* {
"_index" : "megacorp",
"_type" : "employee",
"_id" : "1",
"_version" : 5,
"found" : true,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
}
*/
private static void getOneEmployee(Client client,String index,String type,String id)throws Exception {
GetResponse response3 = client.prepareGet(index, type, id).execute().actionGet();
System.out.println(response3.getSourceAsString());//这是_source部分
//{"first_name":"John","last_name":"Smith","age":25,"about":"I love to go rock climbing","interests":["sports","music"]}
System.out.println(response3.getIndex()+"--"+response3.getType()+"--"+response3.getId()+"--"+response3.getVersion());
}结果显示:
连接成功…
{“first_name”:”John”,”last_name”:”Smith”,”age”:25,”about”:”I love to go rock climbing”,”interests”:[“sports”,”music”]}
megacorp–employee–1—5
Head插件操作示例
