深度学习:基于pytorch,从零到实现CNN分类器并优化
基于pytorch,从零到实现CNN分类器并优化
- 前言
- 基础知识
- Pytorch
- 介绍
- 安装
- 开始学习Pytorch
- 导入包
- tensor
- 基础操作
- 与Numpy类型相互转化
- Autograd(自动求微分)
- 前言
- 简述
- autograd包的使用
- 神经网络
- 前言
- 简述
- 神经网络基本训练过程
- 定义神经网络(注释官网的代码)
- 损失函数(loss function)
- 反向传播(Back propagation)
- 更新权重
- 训练一个(图片)分类器
- 前言
- 数据来源
- 训练步骤
- 深度学习术语补充
- 代码附注释
- 模型改进方面的思考
- 卷积后的图片大小计算
前言
以下内容大部分翻译自pytorch
记录自己从零到实现CNN分类器所寻找的资源、学习过程
基础知识
学会Python的numpy包,numpy官网教程入口
Pytorch
介绍
- Pytorch是一个开源的深度学习平台,提供了从原型研究到生产部署的无缝衔接。
- 可替代Numpy(增强对GPU即图形处理器的使用)
- 一个深度学习的研究平台,具有最大的灵活性和速度
安装
不同版本/平台 Pytorch安装命令
Windows下利用pip安装pytorch1.0
pip install https://download.pytorch.org/whl/cu90/torch-1.0.1-cp36-cp36m-win_amd64.whl
pip install torchvision
开始学习Pytorch
这一大段学习自这里
导入包
import torch
tensor
torch包的数组类型,相当于list和numpy.array(…)
一些函数:
- torch.empty(x,y) 创建大小为X*Y的矩阵,这个矩阵是tensor类型的,初始化为0
- torch.rand(x,y)
- torch.zeros(5, 3, dtype=torch.long)
- torch.tensor([5.5, 3])
- torch.randn_like(x,dtype=torch.float) 创建一个大小和x相同的tensor
基础操作
加减乘除类似numpy,其他
假设x=torch.randn(4,4)
- x.view(…) 改变x的大小
- x.view(-1,8) //the size -1 is inferred from other dimensions,即-1的值可从其他维推出来
- x.item() 返回python原生类型的值
与Numpy类型相互转化
- b=torch.from_numpy(a) 将torch.tensor转化为numpy.array
- b=a.numpy() 将tensor转化为array
Autograd(自动求微分)
前言
官网链接
我看第一遍看不懂他在讲什么,第二遍还是不知道讲什么-_-||(我菜爆了)
于是乎,参考了以下文章点这里
(注:这篇文章里的creator已经被最近版本的pytorch换成了grad_fn)
看完这篇文章,然后我回过去看官网的文章
简述
为了实现autograd,需要使用Variable和Function这两种基本的数据类型
Variable类包括的属性如下:
| 属性名 | 解释 |
|---|---|
| data | 数据(存储着tensor类型的数据) |
| grad | 梯度,即求出来的微分(导数)在data取值下的值 |
| grad_fn | 可理解为函数表达式(是Function类型) |
autograd包的使用
- 开启tensor变量的自动求导功能
x.requires_grad=true
- 自动求微分
对最终的输出y进行操作
y.backward()
- 获取y关于x的导数在x取值下的值
x.grad
- 禁止变量继续追踪计算历史
x.detach()
或者
with torch.no_grad():
....
官网中有提到雅可比不等式,不是很懂,先不深究,以后要用再看
神经网络
前言
这里需要一些机器学习和深度学习(CNN卷积神经网络)的知识,
- 机器学习的课程,推荐吴恩达的网课,网易云课堂入口
原版的是coursera网站上的,只不过coursera是英文的,而网易云课堂有翻译 - CNN:第一个博客入口
第二个博客入口 - CNN中特征图/通道的概念:
特征图:博客入口
通道:博客入口
简述
所需包:
import torch.nn
- nn基于autograd去区分每个神经网络
- nn.Module包含神经网络的layers
- nn.forward(input)返回output
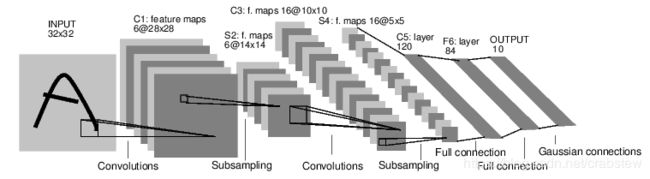
这是一个典型的前馈(feed_forward)神经网络,即 输入数据-经过不同的层处理-产生输出
神经网络基本训练过程
- 定义一个有可学习参数(或称权重)的神经网络
- 在数据集上迭代输入
- 在神经网络中处理输入
- 计算损失loss
- 将梯度(gradients)反向传播回神经网络的参数
- 更新神经网络的权重,一个基本的更新公式是
w e i g h t = w e i g h t − l e a r n i n g _ r a t e ∗ g r a d i e n t weight = weight - learning\_rate * gradient weight=weight−learning_rate∗gradient
定义神经网络(注释官网的代码)
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__() #调用Net父类(nn.Module)的__init__()方法
# 1 input image channel, 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5) #表
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
print(net)
我们只需要定义上面的 forward 函数,backward 函数由torch包自动为我们定义。
学习得到的 参数(权重)可通过以下方法获得:
net.parameters()
*注意:torch.nn只接受小批量输入mini-batches,也就是说不接受单个输入
损失函数(loss function)
损失函数的输入输出
输入:output(经过神经网络计算得到的输出),target(实际的值)
输出:一个值,表示的是ouput离target的距离
例子:
output = net(input) #通过刚才定义的神经网络计算得到输出
target = torch.randn(10) #先随遍设置一个目标值
target = target.view(1, -1) #使目标值和输出拥有相同的维度,-1是自动计算该处的维度的意思
criterion = nn.MSELoss() #使用均方误差mean-square这个loss function
loss = criterion(output, target) #计算均方误差
print(loss)
反向传播(Back propagation)
反向传播是一个根据loss function,计算梯度,以达到最小化loss目的的一个算法。
步骤:
- net.zero_grad() 清空现存的梯度值
- loss.backward() 自动计算梯度
更新权重
最简单的更新权重的方法是 随机梯度下降 Stochastic Gradient Descent(SGD):
w e i g h t = w e i g h t − l e a r n i n g _ r a t e ∗ g r a d i e n t weight=weight-learning\_rate*gradient weight=weight−learning_rate∗gradient
更新权重的方法(这里列出的是每一层循环的内容)
learning_rate=0.01 #设置一个学习率
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
选择其他的损失函数:
刚才我们用了均方误差这个损失函数,torch还提供了其他损失函数,比如说 SGD, Nesterov-SGD, ADAM, RMSProp 等等,这些由 torch.optim 包提供
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr=0.01)
#在每一层循环中
optimizer.zero_grad() # 清空梯度
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # 更新参数(权重)
训练一个(图片)分类器
前言
官网入口
数据来源
- 图片:Pillow,OpenCV(这些都是python包)
- 音频: scipy,librosa
- 文本:Python、Cython/NLTK/SpaCy
- 视觉:torchvision
训练步骤
- 使用torchvision加载并归一化(normalize)CIFAR10数据集
- 定义卷积神经网络
- 定义损失函数(loss function)
- 在训练数据上训练网络(得到一系列的参数)
- 在测试数据上测试分类效果
深度学习术语补充
在看代码前,有必要了解一下什么是随机梯度下降(stochastic gradient descent)、批梯度下降(batch gradient descent)、以及小批的梯度下降(mini-batch gradient descent) 、batchsize、iteration、epoch博客入口
代码附注释
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(), #[0,256]-[0-1]
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#[0-1]-[-1,1]
#transforms.Compose这个函数的作用就是把几个变换组合起来
#里面都是transforms对象
#ToTensor()把numpy.ndarray或PIL Image转换成tensor
#transforms.Normalize 的作用是给定均值和标准差,标准化tensor image
#比如说有三个颜色通道(R,G,B),对于每一个通道的数据有一个M,有一个标准差S
#那么对于每一个数据,该通道归一化后就是(x-M)/S
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
#download=True说明打开下载选项,root='./data'说明下载到当前目录下的data文件夹
#如果download=False则说明数据集已经存在于当前目录下的./data里面
#train=True说明从训练集中加载对象,这里CIFAR10已经未我们预先分好了训练集和测试集
#transform=transform就是用刚才定义的transform对象对数据集进行处理
#返回值 (image, target) where target is index of the target class.
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
#trainset意味着用刚才加载的训练集
#batch_size=4意味着每一个batch大小为4,即用4个数据项就计算损失函数反向传播一次更新参数。
#shuffle=True意味着每次用全部的训练集训练完就进行随机打乱一次
#num_workers是用来载入数据集的子进程的数目
#返回的是一个实例化的类对象
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
#载入测试集,train=False意味着从测试集中加载数据
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
展示训练集的图片
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy() #把图片转换为numpy的array数组
plt.imshow(np.transpose(npimg, (1, 2, 0))
# np.transpose(array,[list of dimension]) 按照列表里的维度顺序调转维度
#plt.imshow显示图片
plt.show()
# get some random training images
#iter是python的内置函数,传入支持迭代的集合对象,返回迭代器对象
dataiter = iter(trainloader)
# 如果batch_size为4,则取出来的images是4×c×h×w的tensor,labels是1×4的向量
images, labels = dataiter.next() #获取一组图像
# show images
imshow(torchvision.utils.make_grid(images))
#制作一个网格后作为一个参数传入函数
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
#以空格为分界符
结果:

训练神经网络
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__() #调用Net父类的init方法
self.conv1 = nn.Conv2d(3, 6, 5)
#定义第一层卷积中的输入通道数为3,输出通道数为6,输入通道为3其实就是RGB三通道
#输出通道数为6其实就是有六个卷积核进行卷积输出6个featuremap,featuremap就是通道
#第三个通道意味着卷积核的大小为5X5
#卷积层的作用是提取特征
self.pool = nn.MaxPool2d(2, 2)
#分别代表卷积核是2X2的矩阵以及卷积步长为2
#池化层的作用是
#1.保留主要的特征,同时减少下一层的参数和计算量,防止过拟合;
#2.保持某种不变性,包括translation(平移),rotation(旋转),scale(尺度)
#常用的有mean-pooling和max-pooling。
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
#分别为输入特征的大小和输出特征的大小
#对应于第二层卷积层 16个通道,每个通道大小为5X5
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
#最后输出10个类别的概率
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
#F.relu的意思是,第一层卷积后的每一个元素都输入这个函数进行处理
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
#改变矩阵的大小,-1自动计算,另一维度为16*5*5
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
接下来定义损失函数以及优化器optimizer来训练神经网络
优化器的意思是,更新参数的方法,之前提到的简单优化器有随机梯度下降SGD
import torch.optim as optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # 一个epoch说明用所用数据进行训练一次
running_loss = 0.0
for i, data in enumerate(trainloader, 0): #enumerate的第二个参数是开始下标的意思
#返回(index,data)
#特征向量和标签
# 由于batch是4,因此input是4*C*W*H的tensor
# label是一个1*4的tensor
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
# 每个mini-batch的大小之前在trainloader里面有设置过
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
在测试集上测试
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data #label指的是在类里面的下标
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
#找出第一维的最大值,predicted里面保存的是下标
total += labels.size(0),#因为是minibatch,所以一组里面有很多个数据
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
每一种类别的正确率
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
#outputs的包含每一个类的概率
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
##一个batch大小为4,相当于有四张图的类别
for i in range(4):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(10):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
模型改进方面的思考
博客入口
尝试1:初始化模型权重
刚开始可以较快收敛,在训练次数比较小的时候还是比较重要的,但是随着epoch增加不怎么有用。
尝试2:更改激活函数
激活函数的作用:
将线性的输出转换为非线性的输出,构造一个复杂的函数,以构造输入和输出之间复杂的映射。
- RELU: 56%
- Simoid: 26%
- tanh : 56%
- log_softmax: 37%
- leaky_relu: 53%
- rrelu: 56%
尝试几个还是没改进,换回RELU
尝试3:数据增强技术
transforms.ColorJitter()
改变亮度、对比度、色调
在训练数据上增加微小的扰动或者变化,一方面可以增加训练数据,从而提升模型的泛化能力,另一方面可以增加噪声数据,从而增强模型的鲁棒性。
方法有:
- 翻转变换 flip
- 随机修剪(random crop)
- 色彩抖动(color jittering)
- 平移变换(shift)
- 尺度变换(scale)
- 对比度变换(contrast)
- 噪声扰动(noise)
- 旋转变换 / 反射变换 (rotation/reflection)
改了好几次好像不是很明显
尝试4:增加对数据集的遍历次数
epoch=2-3: 56-57%
epoch=4-6: 60%左右,loss趋向于一个稳定值
尝试5:根据epoch增加减小learning_rate
理解:当epoch比较小的时候,目标函数还没有收敛到最低点,所以刚开始learning_rate应该要大一点,随着迭代次数增加,应该减小learning_rate。
官网给出初始learning_rate=0.001
发现1-3次迭代loss下降较快,4-6次迭代之后loss下降不是很明显,函数值在最低点附近跳来跳去
改进方案:每四次减小learning_rate,初始设置为0.01
代码参考:博客入口
最终运行12次,精度为65%
尝试6:更改优化器
刚开始使用AdaDelta替代SGD,后换回SGD,但是效果不明显。
博客
尝试7:使用dropout
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
dropout是为了防止过拟合,但是在epoch比较小的时候这个操作会导致正确率下降,因为epoch比较小的时候面临了欠拟合
卷积后的图片大小计算
拿面的代码举例
self.conv1 = nn.Conv2d(3, 6, 5)
3可以理解成有3个矩阵,即一个数据项X有3个特征
输出6个矩阵
假设原来的数据集一个矩阵为32*32的大小
那么输入就是3*32*32
应为卷积核为5,默认步长为1,那么对一个矩阵做卷积,横向进行了28次,
竖向进行了28次,因此输出为6*28*28的矩阵
self.pool = nn.MaxPool2d(2, 2)
卷积核为2,步长为2,相当于横向进行了n/2次卷积,n为矩阵横向长度