学习笔记:自动上色
上篇文章介绍了GAN的基本原理以及如何使用GAN来生成样本,还再用于生成图像样本的一种特殊的GAN结构–DCGAN 。这篇文章会介绍cGAN ,
与原始GAN使用随机躁声生成样本不同, cGAN可以根据指定标签生成样本。接着会介绍pix2pix模型,包可以看作是cGAN的一种特殊形式。最后会做一个实验:在TensorFlow 中使用pix2pix模型对灰度图像自动上色。
cGAN的原理
使用GAN可以对样本进行无监督学习,然后生成全新的样本。但是这里还有一个问题。虽然能生成新的样本,但是却无法确切控制新样本的类型。如使用GAN生成MNIST数字,虽然可以生成数字,但生成的结果是随机的(因为是根据输入的随机躁声生成图片) ,没有办法控制模型生成的具体数字。
如果希望控制生成的结果,例如给生成器输入数字1 ,那么它只会生成数字为1的图像,应该怎么办呢?这实际上是cGAN 可以解决的问题。
先来回忆GAN的输入和输出:
- 生成器G,输入为一个噪声z,输出一个图像G(z) 。
- 判别器D,输入为一个图像x,输出该图像为真实的概率D(x) 。
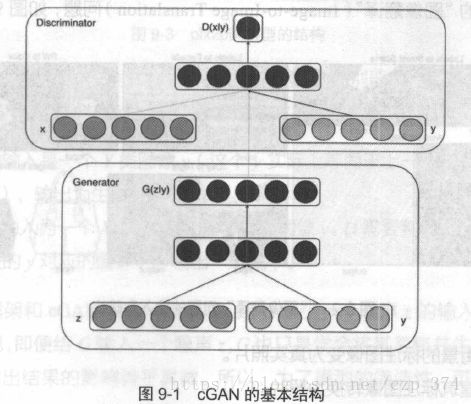
cGAN的全称为Conditional Generative Adversarial Networks, 即条件对抗生成网络,它为生成器、判别器都额外加入了一个条件y, 这个条件实际是希望生成的标签。生成器G必须要生成和条件y匹配的样本,判别器不仅要判别图像是否真实,还要判别图像和条件y是否匹配。cGAN的输入输为:
- 生成器G,输入一个噪声z,一个条件y,输出符合该条件的图像G(z|y)。
- 判别器D,输入一张图像x,一个条件y,输出该图像在该条件下的真实概率D(x|y) 。
cGAN的基本结构如图9-1所示。
在原始的GAN中,优化目标为:
V(D,G)=Ex∼pdata[logD(x)]+Ez∼pz(z)[ln(1−D(G(z)))] V ( D , G ) = E x ∼ p d a t a [ l o g D ( x ) ] + E z ∼ p z ( z ) [ l n ( 1 − D ( G ( z ) ) ) ]
在cGAN中,只需要做简单的修改,向优化目标中加入条件y即可:
V(D,G)=Ex∼pdata[logD(x|y)]+Ez∼pz(z)[ln(1−D(G(z|y)))] V ( D , G ) = E x ∼ p d a t a [ l o g D ( x | y ) ] + E z ∼ p z ( z ) [ l n ( 1 − D ( G ( z | y ) ) ) ]
以MNIST为例,生成器G和判别器D的输入输出是
- G输入一个噪声z,一个数字标签y(y的取值范围是0~9),输出和数字标签相符合的图像G(z|y) 。
- D输入一个图像x,一个数字标签y,输出国像和数字符合的概率D(x|y) 。
显然,在训练完成后,向G输入某个数字标签和噪声,可以生成对应数字的图像。
2 pix2pix模型的原理
都知道所谓的“机器翻译”比如将一段中文翻译成英文。在图像领域,也有类似的“图像翻译”( Image-to-Image Translation )问题, 如图9-2所示。

- 将街景的标注图像变为真实照片。
- 将建筑标注图像转换为照片。
- 将卫星图像转换为地图。
- 将白天的图片转换为夜晚的图片。
- 将边缘轮廓线转段为真实物体。
使用传统的方法很难解决这类图像翻译问题。而这个小节要介绍的pix2pix模型使用了cGAN,可以用同样的网络结构处理这类问题。
pix2pix模型的结构如图9-3所示。
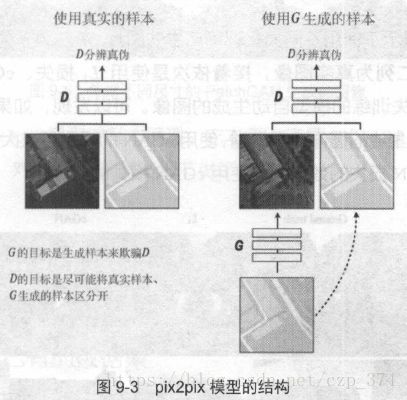
它和cGAN的结构类似,同样是由生成器G、判别器D两个网络组成。设要将Y类型的图像转换为X类型的图像,G、D的任务分别为:
- G的输入是一个Y 类图像y(这个y实际上等同于上一节所讲的cGAN的y),输出为生成图像G(y) 。
- D的输入为一个X类图像x,一个y类图像y。D需要判断x图像是否是真正的y对应的图像,并输出一个概率。
这个框架和cGAN只一有点不同,是G缺少一个躁声z的输入。因为在实验中发现即使给G输入一个噪声z,G也只是学会将其忽略并生成图像,噪声z对输出结果的影响微乎其微。所以,为了模型的简洁性,可以把噪声z去掉。
再了D和G后,可以定义一个和cGAN一模一样的损失 LcGAN L c G A N 。在实验中发现,除了使用 LcGAN L c G A N 外,还可以在生成图像和真实图像之间加上 L1 L 1 或者 L2 L 2 损失,这可以加快模型收敛并提高生成图像的精度。设(x,y)是一个真实的图片对,G 生成的图像是G(y),那么G(y)应该接近真实的图像x,因此,可以在G(y)和x之间定义下面的L1 损失
L1=∥x−G(y)∥1 L 1 = ‖ x − G ( y ) ‖ 1
图9-4展示了使用不同损失训练产生的图片。最左边一列是输入G的图像,左边第二列为真实图像,接着依次是使用 L1 L 1 损失、cGAN 损失以及
cGAN+L1损失训练的模型自动生成的图像。可以发现,如果不使用cGAN
的损失,那么生成的图像会很模糊,使用cGAN的损失可以大大改进这一点。使用L1+cGAN损失的效果比只使用cGAN损失的略好。

除了损失外,pix2pix 模型还对判别器的结构做了一定的小改动。之前都是对整张图片输出一个是否真实的概率。pix2pix模型提出了一种Patch GAN 的概念。PatchGAN对图片中每个NxN的小块(Patch)计算概率,然后再将这些概率求平均值作为整体的输出。这样做可以加快计算速度以及加快收敛。
图9-5比较了PatchGAN相对整张图片进行计算的效果。最左边的一张图是不使用GAN而使用L1损失,往右依次是使用1x1、16 x16 、70x70 、
256x256的PatchGAN。由于图片的尺寸是256,因此256×256的PatchGAN
等价于原来对图像整体计算概率。从图中可以看出,使用1x1和16x16的Patch GAN产生的图片效果不算很好,原因在于Patch取得太小了。但70×70的Patch GAN产生的图片已经和图像整体计算并没再太大差别了。

以上是pix2pix模型的基本原理,它本质上还是一个cGAN,只是针对图片翻译问题,对G和D的某些细节做了调整。
3 TensorFlow中的pix2pix模型
3.1 执行已有的数据集
提供的代码结构比较简单,接下来会用到几个代码文件, 见表9-1。

首先,通过Facades数据集感受这个项目。Facades数据集包含了建筑的外观图像和建筑的标注。建筑的标注同样是图像形式,用不同颜色的色块表示不同的类别。Facades数据集将建筑外观分为墙壁、窗户、门、檐口等12个类别。在项目根目录下运行下面的命令可以下载已经整理格式的Facades数据集:
python tools/download-dataset.py facades下载的文件件存放在当前目录的facades文件夹下,一共分为train、val、
test三个部分。图9-6展示了该数据集的一个训练、样本。

在这个TensorFlow pix2pix项目中,所有的样本图像都将两张图像并列放在一起。左边的称为A类图像,右边的称为B类图像,如图9-7所示。当训练、模型时,可以指定是将A 类图像“翻译”为B类图像,还是将B类图像“翻译”为A 类图像。

在Facades数据集中,希望程序能从图像的标注出发,生成真实的建筑图像。因此,根据图像的排列顺序,应该指定将B类图像转换成A类图像,在项目根目录中运行下面的命令可以训练一个这样的模型:
python pix2pix.py \
--mode train \
--output_dir facades_train \
--max_epochs 200 \
--input_dir facades/train \
--which_direction BtoA参数的含义为:
- –mode train:表示要从头训练模型。后面还会指定–mode test,表示使用已有的模型进行测试。
- –output_dir facades_train:在训练过程中,会把模型自动保存到这个output_dir中,此外还会保存events日志。因此如果要启动TensorBoard观察训练情况,应该指定TensorBoard的logdir为facades_train。即运行指令tensorboard –logdir facades_train
- –max_epochs 200:这个参数很好理解,是执行的epoch数。因为Facades数据集图片较少,所以这里执行的epoch比较多。
- –input_dir facades/train:表示使用的训练数据。我们打开facades/train文件夹进行查看,应该会发现这些训练数据说的都是A 、B类图像并排的式。
- –which direction BtoA :表示应该将B类图像转换为A类图像。也可以指定–which direction AtoB,会训练、将A类图像转换为B 类图像的模型。
在训练过程中,或者等待训练完成后,都可以执行测试,对应的命令为:
python pipx2pix.py \
--mode test \
--output_dir facades_test \
--input_dir facades/val \
--checkpoint facades_train此时参数的含义:
- –mode test:之前是指定–mode train进行训练。这里是进行测试。
- –output_dir facades_test:测试的output_dir会保存测试集中所有图片的结果。以及一个可视化的html文件。
- –input_dir facades/val :执行测试的文件。这个文件夹中有许多和facades/train目录下类似的图像样本,会使用已经训练好的模型对这些图像样本进行转换。
- –checkpoint facades_train:因为之前将模型保存到了facades_train文件夹中,所以在测试时同样指定facades_train文件夹恢复己保存的模型。
执行测试后,在facades_test 文件夹下,会产生一个index.html文件。打开它后,可以看到一个可视化展示生成结果的网页,如图9-8所示。

图9-8的第一列是输入模型的建筑标签,第二列是模型根据标签自动生成的图像,第三列是第一列的标签对应的真实图像。训练结果说明,此模型确实可以将建筑的标签自动“翻译”为真实的建筑,十分神奇。
此外,不仅可以通过index.html来查看结果,还可以在facades_ test/images 文件夹下直接找到所高输入、输出和真实图像。
除了使用Facades数据集外,原项目还提供了几个已经整理好的数据集。给出了这些数据集的下载方式、大小以及示例,我们可以仿照Facades数据集的训练方式自行尝试,见表9-2 。

3.2 创建自己的数据集
如何使用自己的数据集进行训练呢?真实,只需要通过程序,将训练数据也整理为之前所说的A 、B图像并列排列的形式,然后使用第9.3.1节中对应的指令进行训练和测试就可以了。
在pix2pix项目中,提供了几个脚本来帮助创建自己的数据集,真中包含了一些常用的转换操作,现在来看下如何使用这些脚本。
1. 将图片缩放到同样的大小
原始的图片可能尺寸不一,但该项目要求所高训练的A类和B类图片都具有相同的宽和高,因此首先要对图片进行缩放。使用下面的命令可以将图片缩放到相同的大小:
python tools/process.py \
--input_dir photos/priginal \
--operation resize \
--output_dir photos/resized其中,–input_dir指定了原始图片保存的位置。所有缩放处理后的图片将保存在–output_dir参数指定的文件夹下。
2. 转换图像井合并
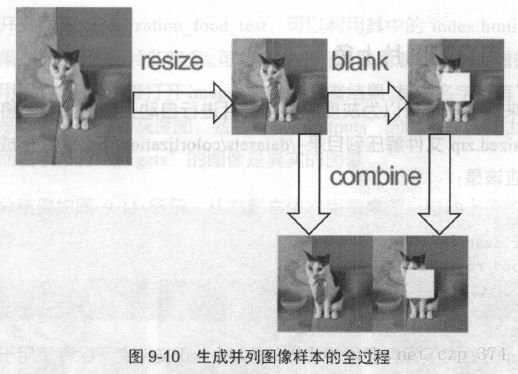
希望可以对A类图像做某种操作以生成对应的B类图像,如图9-9所示,将A 类图像的中间挖去了一部分像素,生成对应的B 类图像。
可以使用提供的脚本来完成这种转换,并将转换后的图像合起来变成一个训练样本。对应的命令是:
python tools/process.py \
--input_dir photos/resized \
--operation blank \
--output_dir photos/blank
python tools/process.py
--input_dir photos/resized \
--b_dir photos/blank \
--operation combine \
--output_dir photos/combined参数的含义应该都比较好理解。先指定了–operation blank,即在图片中央挖去一部分像素,并将生成的图片保存在photos/blank目录下。接着使用
–operation combine将A类和B类图像结合起来,结合后的样本保存在
photos/combined 下。
图像处理的整个过程如图9-10所示。
3. 分割数据集
最后,还可能想把数据集分割为训练集和验证集,对应的命令为。
python tools/split.py \
--dir photos/combined执行命令之后,在photos/combined目录下又会生成两个新的文件夹:train和val 。分别存放训练和验证数据。
4 使用TensorFlow为灰度图像自动上色
在pix2pix项目中,已为“灰度圄像上色”这一特殊的图像翻译问题做了特别的处理。不需要将图像存放成A、B并列的形式,只需要将彩色图像保存成统一的大小就可以进行训练了。在训练时,代码会自动将图片转换为灰度图,并将灰度图作为A类图片,对应的彩色图作为B类图片,训练一个从A 转换到B的模型。
在chapter_9_data/中提供了两个已经整理好的数据集,分别保存为
food_resized.zip和anime_resized.zip 。前者为一系列食物的图像,后者为动漫图像。它们都已经缩放到统一的大小,并使用第3.2节中的脚本划分好
训练和测试集。
4.1 为食物图片上色
先来训练一个可以为灰度的食物图片进行自动上色的模型。将提供的
food_resized.zip文件解压到目录~/datasets/colorlization/下,最终形成的文件夹结构应该是:

train/文件夹下保存了用于训练的图像, val/文件夹下保存了用于验证的图像,所有的图像大小都是统一的。我们可以不必和此处的路径~/datasets/colorlization/保持一致,使用不同路径的话,只需要改变下面运行指令的对应部分即可。
执行训练的命令为:
python pix2pix.py \
--mode train \
--output_dir colorlization_food \
--max_epochs 70 \
--input_dir ~/datasets/colorlization/food_resized/train \
--lab_colorization和第3.1节中的训练指令唯一有区别的地方是,这里指定了–lab_colorization,这样不需要将样本保存成A、B图像并列的形式,指定这
个标签后会自动训练为灰度图像上色的模型。训练的模型和日志都保存在colorlization_food文件夹下。
执行验证的命令为:
python pix2pix.py \
--mode test \
--output_dir colorlization_food_test \
--input_dir ~/datasets/colorization/food_resized/val \
--checkpoint colorization_food打开文件夹colorization_food_test,可以利用其中的index.html查看测试结果。此时因为图片非常多,可能会发生浏览器崩溃而无法产看的情况,此时不用担心,可以直接打开images文件夹查看结果。其中名字带高气nputs ”
的图像是输入模型得到灰度图,名字带布“ outputs ”的图像是自动上色后的
图像, 而名字带高“ targets ”的图像是真实的图像。
部分结果如图9-11所示,从左到右依次为灰度图、自动上色的图像、真实图像。
5 总结
这篇文章的出发点是cGAN ,它是GAN的一个变体。cGAN可以在某种条件下生成样本,因此可以根据标签生成数据。接着介绍了pix2pix模型,它是一种特殊的cGAN,可以较好解决一类“图像翻译”问题。最后,介绍了一个TensorFlow中的pix2pix项目,并使用它对灰度图进行自动上色。