Google Brain去年干了太多事,Jeff Dean一篇长文都没回顾完

编译 | AI科技大本营(rgznai100)
参与 | Reason_W
从AutoML、机器学习新算法、底层计算、对抗性攻击、模型应用与底层理解,到开源数据集、Tensorflow和TPU,Google Brain 负责人Jeff Dean发长文来总结他们2017年所做的工作。但写了一天,Jeff Dean也没覆盖到Google Brain在医疗健康、机器人、基础科学等领域的研究,他接下来打算把如何促进人类创造性、公平和包容性也写进去。
接下来的事情我们接下来再关心,眼下我们还是更关心Jeff Dean已经写好的机器学习技术总结,【AI科技大本营】翻译如下:
核心研究
我们的团队重点追求研究那些可以提高我们对机器学习的理解力以及解决机器学习领域新问题能力的问题。
自动化机器学习(AutoML)
自动化机器学习的目标是开发计算机在不需要人类机器学习专家干预的情况下,自动解决每个新的机器学习问题的技术。如果我们想要创造真正的智能系统,这一定是我们需要的基本能力。我们通过使用强化学习和进化算法设计神经网络结构,开发了一些新方法,并通过这项工作在ImageNet分类和检测任务上实现了目前最好的效果,同时提出了自动学习新优化算法和有效的激活函数的方法。我们也正在同我们的云人工智能(Cloud AI)团队合作,以期让更多Google的客户享受到此项技术带来的优势,同时还将向多个方向推进这项研究。
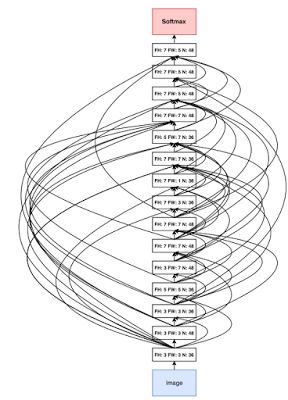
通过神经架构搜索发现的传统架构
https://research.google.com/pubs/pub45826.html

通过自动化机器学习技术设计网络进行目标检测
https://research.googleblog.com/2017/11/automl-for-large-scale-image.html
语音理解和生成
我们的另一项工作是开发提升计算机系统理解和生成人类语言能力的技术。在与Google语音团队的合作中,我们通过在语音识别端到端方法上的大量改进,使得Google语音识别系统的相对单词错误率降低了16%。这项工作的出色之处在于,它将很多独立的研究线索整合到了一起。

面向语音识别的 Listen-Attend-Spell端到端模型
https://research.googleblog.com/2017/12/improving-end-to-end-models-for-speech.html
我们还和Google机器感知团队的同事们合作开发了一种新的文本-语音生成方法,极大提高了语音生成的质量。我们的模型在mean opinion score (MOS)上的评分可以达到4.53分。而在我们之前,最好的计算机语音生成系统的评分(mean opinion score (MOS))只能达到4.34,即使是有声读物中使用的专业语音质量也只有4.58分。这里我们的demo效果 listen for yourself.,你可以自己感受一下它的效果。
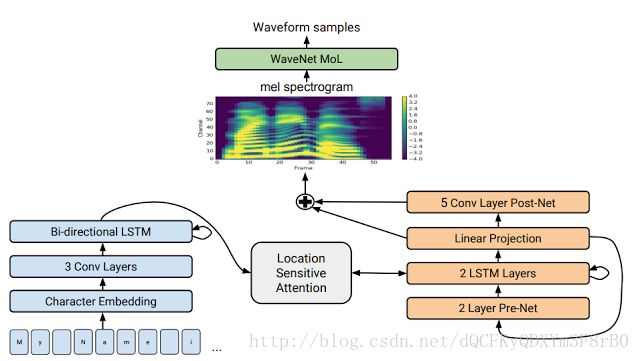
Tacotron 2(我们的文本-语音生成方法)的模型架构
https://research.googleblog.com/2017/12/tacotron-2-generating-human-like-speech.html
新的机器学习算法
这一年,我们一直在不断开发新颖的机器学习算法,包括
- capsules(一种可以明确地寻找激活特征中的一致性,从而可以用于评估视觉任务中多种不同噪声假设的方法,该工作发表在NIPS(2017))、
- sparsely-gated mixtures of experts(一种可以在保证计算效率的同时处理大型数据的网络模型)、
- hypernetworks(一种可以使用一个模型的权重来生成另一个模型权重的网络,该工作发表在ICLR (2017))、
- new kinds of multi-modal models(一种可以在多任务(音频、视觉、文本输入)学习中使用同一模型的方法)、
- attention-based mechanisms (一种可以替代卷积网络和循环网络的模型【小编注,就是前段时间讨论的很热的Attention is All You Need】,该工作发表在NIPS (2017))、
- symbolic和non-symbolic的学习优化方法、
- back-propagate through discrete variables(一种通过离散变量反向传播的方法,ICLR (2017))
- 以及一系列在reinforcement learning( 增强学习,NIPS (2017))算法上的改进。
面向计算机系统的机器学习
在计算机系统中使用机器学习来取代传统的启发式方法也是我们非常感兴趣的一个方向。我们的工作展示了通过使用强化学习进行位置决策,以便将计算图映射到计算设备上的方法,该方法显示出了比人类专家更好的表现。同Google Reasearch的同事一道,我们的工作表明了在“索引结构学习情形(“The Case for Learned Index Structures,)”下,神经网络工作效果比传统数据结构(如B-trees,哈希表和布隆过滤器)更快,内存更小。正如我们在NIPS 机器学习和系统(Machine Learning for Systems and Systems for Machine Learning)的研讨会上说的那样,我们相信我们才刚刚抓住了在核心计算机系统中应用机器学习的皮毛。

索引结构学习到的模型(Learned Models as Index Structures)
https://arxiv.org/abs/1712.01208
隐私和安全
机器学习及其与安全和隐私的交互仍是我们关心的研究重点。我们的工作表明了机器学习能以一种新颖的方式应用到隐私保护中,该工作发表在ICLR (2017)上,并获得了最佳论文奖。我们还继续研究了机器学习在对抗性攻击领域的特性,包括证实物理世界的对抗性攻击以及在训练过程中大规模利用对抗性攻击以使得模型在对抗性攻击面前更加鲁棒的方法。
理解机器学习系统
虽然深度学习在很多方面给我们带来了极大的改善效果,但对我们来说更重要的是要搞明白它为什么有效(work),什么时候无效。在ICLR (2017)的另一篇最佳论文奖中,我们的工作表明了目前的机器学习理论框架都无法解释深度学习所带来的显著的改善结果。我们还证明了最优化方法找到的极小值的“平滑性”并不像一开始想象的那样同良好的泛化性紧密相关。为了更好地理解深度架构下的训练机制,我们发表了一系列分析随机矩阵(它们是大多数训练方法的出发点)的论文。另一个理解深度学习的重要途径是更好地衡量它们的表现。在最近的一项研究工作中,我们表明了良好的实验设计和统计严谨性的重要性。在对很多GAN(生成式对抗网络)方法进行对比之后,我们发现这些受到追捧的生成式模型的增强方法实际上并没有提高性能。我们希望这项研究可以为其他研究人员提高一个让实验研究更鲁棒的范例。
我们正在研究可以更好地解释机器学习系统的方法。在2017年的三月份,我们与OpenAI, DeepMind, YC Research及其他一些研究机构合作推出了 Distill,这是一本致力于促进人类对机器学习理解的开放性在线科学期刊。它在包括机器学习概念上清晰的阐释,以及其文章中提供的出色的交互式可视化工具方面好评颇多。在过去的一年中,Distill发布了许多旨在了解各种机器学习技术的内部工作的启发性的文章。2018年,我们期待更多更好的工作可以出现。

特征可视化(Feature Visualization)
https://distill.pub/2017/feature-visualization/

如何有效使用t-SNE(How to Use t-SNE effectively)
https://distill.pub/2016/misread-tsne/
机器学习开源数据集
诸如 MNIST, CIFAR-10, ImageNet, SVHN, 和 WMT 这样的开源数据集已经极大地推动了机器学习领域的发展。作为一个整体,过去的一年我们和Google Research一直在积极地通过提供更多的大型标记数据集,为机器学习研究提供更多有趣的开源新数据集:
- YouTube-8M: 4,716个不同类别,超过700万的YouTube视频注释
- YouTube-Bounding Boxes: 500万个边界框(bounding boxes),涉及21万个 YouTube 视频
- Speech Commands Dataset: 简短命令语,涉及数千个人
- AudioSet: 200万个10秒的YouTube剪辑,标有527个不同的声音事件Atomic Visual Actions (AVA): 21万个动作标签 ,涉及57,000个视频剪辑
- Open Images: 9M的创意共享授权图片,标有6000个类别
- Open Images with Bounding Boxes: 1.2M的边界框(bounding boxes),涉及600个类

来自YouTube边界框数据集( YouTube-Bounding Boxes dataset)的示例:在以每秒1帧采样的视频片段中围绕感兴趣的项目成功标识边界框。
TensorFlow 和开源软件
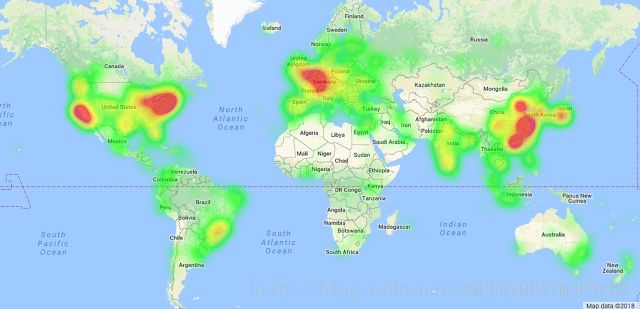
TensorFlow用户 (source) 全球分布地图
回顾我们团队的历史就会发现我们已经构建了一些有用的工具,可以帮助我们在Google的许多产品中进行机器学习研究并部署机器学习系统。2015年11月,我们开源了第二代机器学习框架TensorFlow,希望机器学习社区能够从我们在机器学习软件工具的工作中受益。
今年二月份,我们发布了TensorFlow 1.0,在11月份,我们发布了1.4版本,包括:交互式命令式编程,TensorFlow程序的优化编译器XLA和TensorFlow Lite(一个针对移动和嵌入式设备的轻量级解决方案)。预编译的TensorFlow二进制文件现在下载量已经超过一千万次,涉及到180多个国家,GitHub上的源代码贡献者现在已经超过1200位。
今年2月,我们举办了第一届TensorFlow开发者峰会,有450多人参加了在山景城举办的活动,活动直播观看人次超过6500人,全球35个国家和地区举办了超过85场的本地观看活动。
峰会所有的演讲都已经被记录了下来,主题包括新特性,使用TensorFlow的技巧,以及在低层次的TensorFlow抽象(low-level TensorFlow abstractions)中的详细介绍。
我们还将于2018年3月30日在湾区举办第二届TensorFlow开发者峰会。大家可以通过这里(Sign up now )进行注册,以确认时间并关注最新消息。
https://youtu.be/hyNruFqe1L0
这个剪刀石头布实验是TensorFlow的一种新颖的用途。我们对在2017年看到的TensorFlow广泛的用途感到兴奋,包括黄瓜自动化分拣,在航拍图像中寻找海牛,将切丁的马铃薯分类以制作更安全的婴儿食品,识别皮肤癌,帮助解读在新西兰鸟类保护区的鸟叫录音,并在坦桑尼亚为地球上最流行的根作物鉴定病株!
在11月,TensorFlow庆祝了它开放源代码项目两周年。这样一个充满活力的TensorFlow开发人员和用户群体的出现,给予了我们莫大的荣誉感。TensorFlow现在是GitHub上排名第一的机器学习平台,也是GitHub上的五大软件库之一,使用者包括众多的公司和组织。在GitHub上与TensorFlow相关的软件库超过24,500个。现在,许多研究论文都在发表时,附加上开源的TensorFlow代码以配合研究结果,从而使社区人员能够更容易地理解所使用的确切方法,并重现或扩展工作。
TensorFlow也从Google其他研究团队的相关开源工作中受益颇多,其中包括TensorFlow中的轻量级生成式对抗模型库TF-GAN,用于处理晶格模型(lattice models)的一组估计器TensorFlow Lattice,以及TensorFlow 目标检测API。TensorFlow模型库正在同越来越多的算法模型共同发展。
除了TensorFlow,我们还在发布了deeplearn.js,一个开源的网页版硬件加速深度学习API实现(无需下载或安装任何东西,只需要一个浏览器)。deeplearn.js主页有许多很好的例子,其中包括一个使用你自己的网络摄像头(webcam)就可以训练出的计算机视觉模型——“教学机器”,以及一个基于实时神经网络(real-time neural-network)的钢琴作曲和表演演示——“表演RNN”。我们还将在2018年继续努力,以便将TensorFlow模型直接部署到deeplearn.js环境中。
TPUs

提供高达180 teraflops的机器学习加速的云端TPU Cloud TPUs
大约五年前,我们认识到深度学习会大大改变我们所需要的硬件种类。 深度学习的计算量非常大,但它们有两个特殊的性质:它们主要由密集的线性代数运算(矩阵乘法,向量运算等)组成,它们对精度的降低非常宽容。我们意识到我们可以利用这两个属性来构建能够非常快速地运行神经网络计算的专用硬件。我们为Google的平台团队提供了设计思路,他们设计并生产了我们的第一代Tensor Processing Unit(TPU):一种旨在加速深度学习模型推理的单芯片ASIC(推理是使用已经训练的神经网络,并且与训练不同)。
第一代TPU已经在我们的数据中心部署了三年,并且已经被用在包括Google搜索查询,Google翻译,Google相册中图像理解,AlphaGo与李世石以及柯杰的对战等很多深度学习模型上,以及其他许多研究和产品用途。 六月份,我们在ISCA 2017上发表了一篇论文,显示第一代TPU比现代GPU或CPU同类产品快15倍--30倍,性能/功耗要好30- 80倍。

可以提供高达11.5 petaflops机器学习加速的Cloud TPU Pods
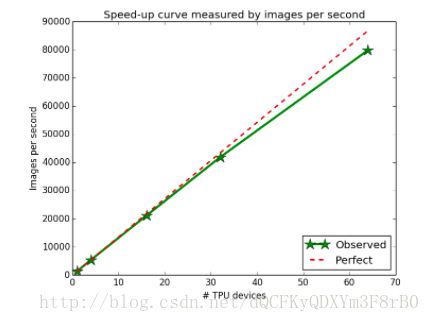
随着所使用的TPU设备数量的增加,在ImageNet上进行ResNet-50训练的实验显示其接近完美的线性加速。
推理是重要的,但加速训练过程是一个更重要的问题 - 也更难。训练过程越快,研究人员尝试一个新的想法的时间就越少,我们就可以做出更多的突破。我们在5月份的Google I / O上发布的第二代TPU是一个旨在加速训练和推理的完整系统(定制ASIC芯片,电路板和互连),我们展示了单机配置以及一个叫做TPU Pod的多机深度学习超级计算机配置。这些第二代设备将作为云端TPU在Google云端平台上供大家使用。 我们还公布了TensorFlow研究云计划(TFRC, TensorFlow Research Cloud (TFRC)),该计划旨在为那些致力于与世界分享他们的工作的顶级机器学习研究人员提供支持,以便他们可以免费访问1000个云端TPU的集群。在十二月份,我们的一项工作表明我们可以在22分钟内在TPU Pod上训练一个ResNet-50 ImageNet模型,同时比在一个传统的工作站上需要几天或更长时间训练出来的模型精度更高。我们认为以这种方式缩短研究周期将大大提高Google的机器学习团队以及所有使用云端TPU的组织的工作效率。如果您对Cloud TPU,TPU Pods或TensorFlow Research Cloud感兴趣,可以在g.co/tpusignup上进行注册以了解更多信息。在2018年,我们非常开心能让更多的工程师和研究人员使用TPU!
感谢阅读!
(在第二部分中,我们将讨论机器学习在那些可能产生重大影响的特定领域的研究,包括在医疗健康、机器人、基础科学领域的研究。我们还将介绍我们在促进人类创造性、公平和包容性方面所做的工作。)
作者 | Jeff Dean,Google 高级研究员,Google Brain 团队发言人
原文链接:https://research.googleblog.com/2018/01/the-google-brain-team-looking-back-on.html