【实用】Redis各种存储结构使用场景
1. Redis使用场景简介
1.1 Redis常见使用场景

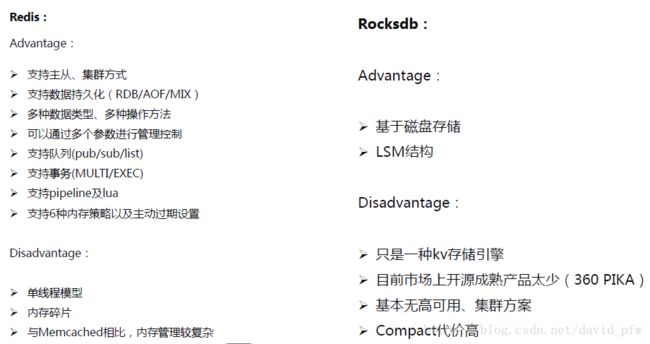
1.2 Redis竞品比较

2. Redis数据类型及实用场景
2.1 Redis数据类型总览
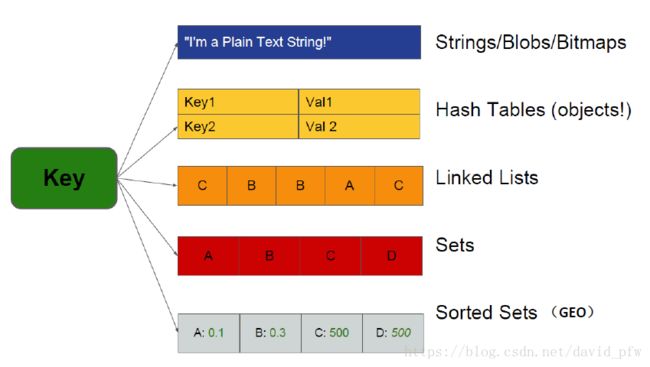
2.2 Redis常见数据结构
- String 数据结构
- List 数据结构
- Hash 数据结构
- Set 数据结构
- Zset数据结构
2.2.1 String
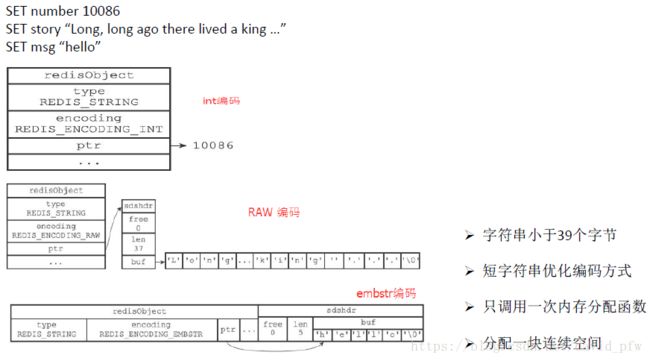
String 内部存储:
String 常用命令:
- SET:为一个key设置value,可以配合EX/PX参数指定key的有效期,通过NX/XX参数针对key是否存在的情况进行区别操作,时间复杂度O(1)
- GET:获取某个key对应的value,时间复杂度O(1)
- GETSET:为一个key设置value,并返回该key的原value,时间复杂度O(1)
- MSET:为多个key设置value,时间复杂度O(N)
- MSETNX:同MSET,如果指定的key中有任意一个已存在,则不进行任何操作,时间复杂度O(N)
- MGET:获取多个key对应的value,时间复杂度O(N)
- INCR:将key对应的value值自增1,并返回自增后的值。只对可以转换为整型的String数据起作用。时间复杂度O(1)
- INCRBY:将key对应的value值自增指定的整型数值,并返回自增后的值。只对可以转换为整型的String数据起作用。时间复杂度O(1)
- DECR/DECRBY:同INCR/INCRBY,自增改为自减。
String 使用场景:
- 文章
- 库存控制
- 简单的计数器
2.2.2 List
List 内部存储:
RPUSH numbers 1 “three” 5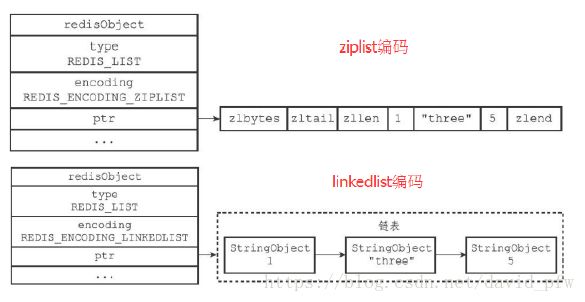
参数配置:
list-max-ziplist-entries 512
list-max-ziplist-value 64
List 常用命令:
- LPUSH:向指定List的左侧(即头部)插入1个或多个元素,返回插入后的List长度。时间复杂度O(N),N为插入元素的数量
- RPUSH:同LPUSH,向指定List的右侧(即尾部)插入1或多个元素
- LPOP:从指定List的左侧(即头部)移除一个元素并返回,时间复杂度O(1)
- RPOP:同LPOP,从指定List的右侧(即尾部)移除1个元素并返回
- LPUSHX/RPUSHX:与LPUSH/RPUSH类似,区别在于,LPUSHX/RPUSHX操作的key如果不存在,则不会进行任何操作
- LLEN:返回指定List的长度,时间复杂度O(1)
- LRANGE:返回指定List中指定范围的元素(双端包含,即LRANGE key 0 10会返回11个元素),时间复杂度O(N)。应尽可能控制一次获取的元素数量,一次获取过大范围的List元素会导致延迟,同时对长度不可预知的List,避免使用LRANGE key 0 -1这样的完整遍历操作。
List 使用场景:
- 队列
- 关注列表
- 评论列表
2.2.3 Hash
Hash内部存储:
HSET profile name “tom”
HSET profile age 25
HSET profile carerr“Programmer”

参数配置:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
Hash 常用命令:
- HSET:将key对应的Hash中的field设置为value。如果该Hash不存在,会自动创建一个。时间复杂度O(1)
- HGET:返回指定Hash中field字段的值,时间复杂度O(1)
- HMSET/HMGET:同HSET和HGET,可以批量操作同一个key下的多个field,时间复杂度:O(N),N为一次操作的field数量
- HSETNX:同HSET,但如field已经存在,HSETNX不会进行任何操作,时间复杂度O(1)
- HEXISTS:判断指定Hash中field是否存在,存在返回1,不存在返回0,时间复杂度O(1)
- HDEL:删除指定Hash中的field(1个或多个),时间复杂度:O(N),N为操作的field数量
- HINCRBY:同INCRBY命令,对指定Hash中的一个field进行INCRBY,时间复杂度O(1)
- HGETALL:返回指定Hash中所有的field-value对。返回结果为数组,数组中field和value交替出现。时间复杂度O(N)
- HKEYS/HVALS:返回指定Hash中所有的field/value,时间复杂度O(N)
Hash 使用场景:
- 用户资料
- 购物车
- 存储对象相关
2.2.4 Set
Set内部存储:
SADD numbers 1 3 5
SADD fruits “apple” “banana” “cherry”
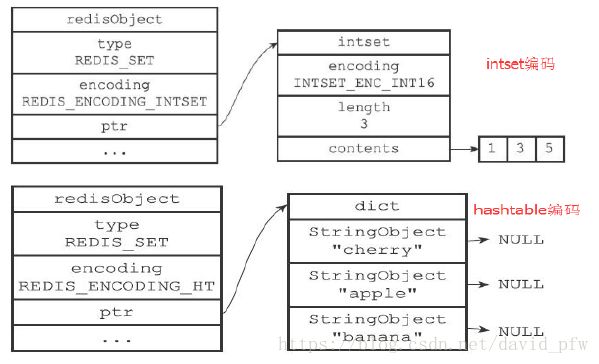
参数配置:
set-max-intset-entries 512
注意:intset编码中集合对象中保存的所有元素都是int值
Set 常用命令:
- SADD:向指定Set中添加1个或多个member,如果指定Set不存在,会自动创建一个。时间复杂度O(N),N为添加的member个数
- SREM:从指定Set中移除1个或多个member,时间复杂度O(N),N为移除的member个数
- SRANDMEMBER:从指定Set中随机返回1个或多个member,时间复杂度O(N),N为返回的member个数
- SPOP:从指定Set中随机移除并返回count个member,时间复杂度O(N),N为移除的member个数
- SCARD:返回指定Set中的member个数,时间复杂度O(1)
- SISMEMBER:判断指定的value是否存在于指定Set中,时间复杂度O(1)
- SMOVE:将指定member从一个Set移至另一个Set
- SMEMBERS:返回指定Hash中所有的member,时间复杂度O(N)
- SUNION/SUNIONSTORE:计算多个Set的并集并返回/存储至另一个Set中,时间复杂度O(N),N为参与计算的所有集合的总member数
- SINTER/SINTERSTORE:计算多个Set的交集并返回/存储至另一个Set中,时间复杂度O(N),N为参与计算的所有集合的总member数
- SDIFF/SDIFFSTORE:计算1个Set与1或多个Set的差集并返回/存储至另一个Set中,时间复杂度O(N),N为参与计算的所有集合的总member数。
Set 使用场景:
- 与list相比可以排重
- 共同关注
- 共同喜好
2.2.5 Zset
Zset内部存储:
ZADD price 8.5 apple 5.0 banana 6.0 cherry
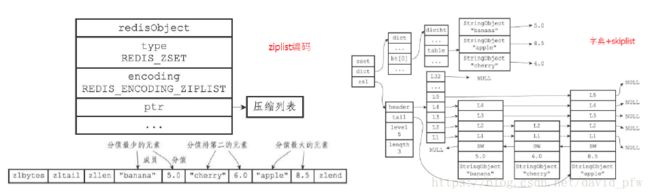
参数配置:
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
Zset常用命令:
- ZADD:向指定Sorted Set中添加1个或多个member,时间复杂度O(Mlog(N)),M为添加的member数量,N为Sorted Set中的member数量
- ZREM:从指定Sorted Set中删除1个或多个member,时间复杂度O(Mlog(N)),M为删除的member数量,N为Sorted Set中的member数量
- ZCOUNT:返回指定Sorted Set中指定score范围内的member数量,时间复杂度:O(log(N))
- ZCARD:返回指定Sorted Set中的member数量,时间复杂度O(1)
- ZSCORE:返回指定Sorted Set中指定member的score,时间复杂度O(1)
- ZRANK/ZREVRANK:返回指定member在Sorted Set中的排名,ZRANK返回按升序排序的排名,ZREVRANK则返回按降序排序的排名。时间复杂度O(log(N))
- ZINCRBY:同INCRBY,对指定Sorted Set中的指定member的score进行自增,时间复杂度O(log(N))
- ZRANGE/ZREVRANGE:返回指定Sorted Set中指定排名范围内的所有member,ZRANGE为按score升序排序,ZREVRANGE为按score降序排序,时间复杂度O(log(N)+M),M为本次返回的member数
- ZRANGEBYSCORE/ZREVRANGEBYSCORE:返回指定Sorted Set中指定score范围内的所有member,返回结果以升序/降序排序,min和max可以指定为-inf和+inf,代表返回所有的member。时间复杂度O(log(N)+M)
- ZREMRANGEBYRANK/ZREMRANGEBYSCORE:移除Sorted Set中指定排名范围/指定score范围内的所有member。时间复杂度O(log(N)+M)
Zset使用场景:
- 排行榜
2.2.6 RedisHyperLog
Redis在2.8.9 版本添加了HyperLog结构。
RedisHyperLog是用来做基数统计的算法,HyperLog的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定的、并且是很小的。

2.2.7 Redis内存优化怎么做
1. 业务控制key与value长度
2. 数据结构优化
- 共享内存
- 采用压缩编码
- 数据类型替换
3. 内存碎片
2.2.8 内部存储架构
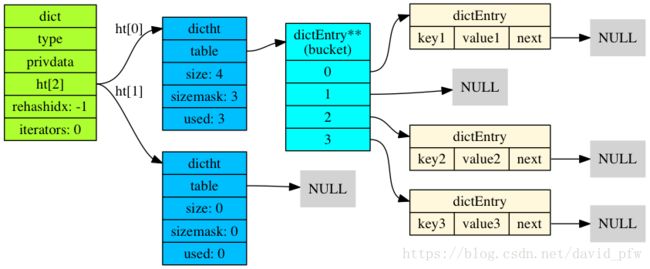
- Redis一个db的所有Key/value 存储在一个字典中
- 一个字典包括两个hash table
- ht[0]用于存储键值对,ht[1]用于rehash(扩容)
- 一个dictEntry包含一个键值对
- 单向链表解决键hash过后的值冲突
3. Redis使用场景总结
3.1 案例1
实现一个文章列表,文章可根据投票数量或者时间进行排序,并且一个用户只能给文章投一次票,文章超过2周之后就不能进行投票了。

3.2 案例2
某APP需要实时,或者定时下发推送消息,针对于不在线的用户则需要等待用户下次打开APP的时候可以收到推送消息。
3.2.1 流程分析
运营编辑数据> 保存下发信息
下发系统> 扫描下发信息> 根据用户生成下发队列> 下发信息
3.2.2 依赖数据
- 下发任务存储
- 下发内容存储
- 下发队列存储
3.2.3 实现
1、下发任务存储:
数据结构:zset
key:bid(业务唯一id)
value:{157ED172BHZHOHzs0jBcBLscriehOgdr1482065164} (唯一下发ID,时间戳(下发时间))
2、下发内容存储:
数据结构:hash
key:push_id(157ED172BHZHOHzs0jBcBLscriehOgdr )
value:{time:1521953508,total:100000000,content:'张继科公布恋情',......}
3、下发队列存储:
数据结构:list(队列)
具体数据:
key:push_id
value:({time:timestamp,appid:234,content:"张继科公布恋情",token:"c00564a3cf132a138ab3334b",......})
3.3 案例3
某APP需要根据用户的特性及平常访问的文章来给用户推荐他可能感兴趣的文章以及广告。
3.3.1 流程分析
用户注册登录>用户访问具体文章> 客户端记录用户访问记录> 用户再次访问或者下拉列表> APP根据用户相关特性以及兴趣标签推送相应的文章或广告
3.3.2 依赖数据
- 用户信息存储
- 标签对应文章
- 文章元数据
- 用户兴趣标签
- 文章推送列表
- 访问历史存储
- 曝光历史存储
- 用户地理位置存储
3.3.3 实现
1、用户存储
数据结构:hash
具体数据:
key:uid(用户唯一ID)
value:{name:“martin”,age:28,loc:“beijing”, gender:”男”}
2、存储标签对应的文章
数据结构:set
具体数据:
key:tag_id(唯一兴趣标签)
value:(doc_id,doc_id,doc_id,ad_id)
3.存储文章元数据
数据结构:hash
具体数据:
key:doc_id(文章唯一id)
value:{ctime:1515585314,category:'体育',author:'martin',into:'张继科公布恋情',url:'http://test.cn'}
4、存储用户兴趣标签
数据结构:hash
具体数据:
key:用户唯一id,(23532452)
value:{tag_id:'外事访问',tag_id:'张继科'}
5、存储文章推送列表
数据结构:set
具体数据:
key:uid(用户唯一id)
value:(doc_id,doc_id,doc_id)
6、访问历史存储:
数据结构:zset
具体数据:
key:uid(用户访问id)
value:{doc_idtimestamp,doc_idtimestamp}
7、曝光历史存储:
数据结构:zset
具体数据:
key:uid(用户访问id)
value:{doc_idtimestamp, doc_idtimestamp}
8、地理位置存储:
数据结构:geo(zset)
key:uid(用户id)
value:{39.9110666857,116.4136103013}
经度、维度
3.3.4 Redis其他用途
- 分布式锁
- 服务发现,配置存储
- 队列