互斥锁——解决原子性问题
互斥锁
文章目录
- 互斥锁
- 1. 线程不安全的三大原因
- 1.三大特性问题举例
- 1. 原子性:
- 2. 可见性
- 3. 有序性
- 2. Java解决有序性和可见性的方案
- 3. 互斥锁——解决原子性问题
- 1. Long变量在32位机器上的问题
- 2. 互斥的定义
- 3. Java提供的互斥锁:synchronized
- 4. 超典型的银行转账问题
- 1. 保护没有关联的多个资源
- 2. 保护有关联关系的多个资源
- 1. 误区方式
- 2. 同一把锁方式
- 3. 用全局锁(class对象锁)
- 4. 双重锁
1. 线程不安全的三大原因
线程不安全的源头来自于无法保证以下特性:
- 原子性 :把一个或者多个操作在CPU中的执行不被中断的特性;
- 操作系统的线程切换可以发生在任何一个指令之后,这就是原子性的根源;
- 可见性:一个线程对共享变量的修改,其他线程能够立马得知;
- 缓存是导致可见性问题的根因
- 有序性: 保证程序按照代码的书写顺序来执行;
- 导致有序性问题的就是编译器的优化,会带来指令重排序;
1.三大特性问题举例
以上只是做了个简单的分析介绍,下面来举一些示例来进行说明
1. 原子性:
private int count = 1;
count += 1; //2
假如线程一在执行上述语句2时,在CPU里应该分成三条指令:
- (1)向内存读取count到工作内存
- (2)执行+1操作
- (3)写回count到内存
当线程一执行到1的时候,时间片完了,这时线程二获取到了时间片,来执行这三个步骤,并执行完成,此时写回内存的是2,然后线程一又获取到了时间片,然后继续执行(2)、(3),最后写回去的还是2,这就产生了原子性的问题;
2. 可见性
上面说了,可见性是缓存造成的,这是典型的硬件给软件挖的坑!,为了提升运算效率,引入了缓存,同时也带来了风险,(当时单核CPU的情形下是没有风险的,因为操作的都是同一块缓存,不存在不可见问题),但现在多核多线程的时代,缓存带来的不可见问题是肯定不可避免的;
这里来举个简单的例子:(count初始值为0)
count += 1;
假如线程一来执行这条语句,会先从内存中读取count到自己的工作内存中,然后执行加一,然后写回主内存,问题就发生在这,写回主内存的时间是不确定的,假如在写回主内存前,假如有线程二来执行这条语句,此时从主存中读取到的count到工作内存为1,加一后为2,这时最终写回主内存的count值肯定为2;
当然,发生上述是小概率事件,但你把线程数调到10000、100000,最终count的值肯定小于10000、100000;
3. 有序性
编译器为了优化性能,有时候会改变程序中语句的先后顺序,但不会改变程序最终的执行结果,这里指单线程下不会产生与原来不同的结果,但多线程就未必了,有时会产生意想不到的结果;
这里最典型的例子就是double check(双重单例模式)里面可能产生空指针异常的问题,这里就不再详述,我的前面一篇博客有介绍:
2. Java解决有序性和可见性的方案
开门见山:
Java为了解决有序性和可见性,引入了Java内存模型,这里就不再详细介绍,上面说到了,要解决这两个问题,最直接的就是禁用缓存和编译优化,但这大大的降低了效率,在单线程的情况下本来就线程安全,但却使用不了缓存和编译优化;
所以Java内存模型做到了按需禁用缓存以及编译优化,将设置权交给程序员,至于如何按需禁用,Java里提供了很多方法:volatile、synchronized、final、Happens-before原则;
这里看一个例子:
class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;
v = true;
}
public void reader() {
if (v == true) {
// 这里 x 会是多少呢?
}
}
}
问题:
如上代码所示,线程A执行writer方法,这时线程B执行reader方法,当v==true,进入if块里面时,x为多少?
解答:
在JDK5之间可能是42,也有可能0,但在jdk5之后,x肯定为42,具体为什么,先来看看happens-berore原则:
在谈happens-berore规则前,先说明,happens-before并不是先行发生的意思,一定不要这样理解,它的意思是:
- A Happens before B,代表A操作的结果对B是可见的;
Happens-before原则约束了编译器的优化行为,虽然允许编译器优化,但是要求编译器优化后一定遵守Happens-before原则;
1 . 规则一:程序的顺序性规则
一个线程中,按照程序的顺序,前面的操作happens-before后续的任何操作。
对于这一点,可能会有疑问。顺序性是指,我们可以按照顺序推演程序的执行结果,但是编译器未必一定会按照这个顺序编译,但是编译器保证结果一定==顺序推演的结果。
2 . 规则二:volatile规则
对一个volatile变量的写操作,happens-before后续对这个变量的读操作。
3 . 规则三:传递性规则
如果A happens-before B,B happens-before C,那么A happens-before C。
jdk1.5的增强就体现在这里。回到上面例子中,线程A中,根据规则一,对变量x的写操作是happens-before对变量v的写操作的,根据规则二,对变量v的写操作是happens-before对变量v的读操作的,最后根据规则三,也就是说,线程A对变量x的写操作,一定happens-before线程B对v的读操作,那么线程B在注释处读到的变量x的值,一定是42.
4 . 规则四:管程中的锁规则
对一个锁的解锁操作,happens-before后续对这个锁的加锁操作。
这一点很好理解,例如线程一进入了一个synchronized块,当它释放锁后,线程二又立马获取了锁进入了synchronized块,这时线程一在其中数据的改变对线程二是可见的;
5 . 规则五:线程start()规则
主线程A启动线程B,线程B中可以看到主线程启动B之前的操作。也就是start() happens before 线程B中的操作。
6 . 规则六:线程join()规则
主线程A等待子线程B完成,当子线程B执行完毕后,主线程A可以看到线程B的所有操作。也就是说,子线程B中的任意操作,happens-before join()的返回。
3. 互斥锁——解决原子性问题
好啦这里才到本文的主题,前面提到,原子性问题是因为CPU在切换线程时并不是以高级语言中的语句为准,而是以指令,高级语言中的语句一般由好几个指令构成,所以切换线程的时候就可能中断在高级语言中的一个完整操作,这就导致了原子性问题的发生;
1. Long变量在32位机器上的问题
大家都知道,Long变量是8个字节,64位,如果在32位上的机器要操作(写)Long变量,就得分成两次写操作来完成,即一次写高32位,一次写低32位,即:
Long x = 0;
x = 100; //2
看似x = 100是个原子操作,但是这里在32位机器上却被分割成了两个步骤,假如在写完高32位时,时间片完了,另一个线程也来写高32位,这时就发生了线程安全问题了,前面一个的值就会被覆盖;
2. 互斥的定义
所谓互斥:就是同一时刻只有一个线程执行!!(⭐)
只有保证了对共享变量的修改是互斥的,就能保证原子性问题了;
谈到互斥,这里就想到了锁,没错,就是如下这个典型的模型:
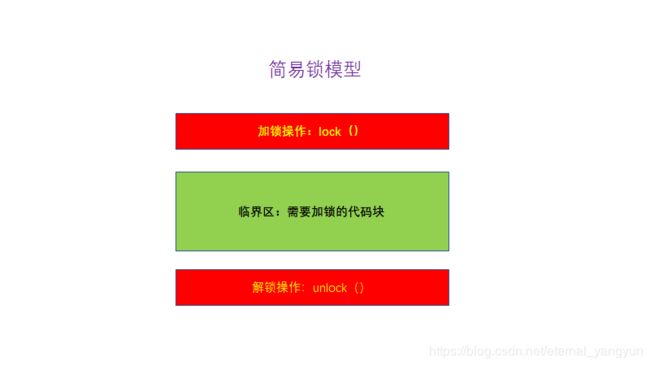
这里,我们把一段需要互斥执行的代码称为临界区,线程进入临界区前,先尝试加锁,如果失败,说明锁被其他线程占用,就需要等待那个线程释放锁,然后获取锁;
但我们需要明确:我们锁的是什么?我们保护的又是什么?
即锁和锁保护的资源应当是有关系的,这里就有了改进的锁模型:(这大大提升了多线程下的并发效率)

运用这种锁模型,我们需要注意的是:
- 认清锁和资源的关系,不要出现“锁自家门保护别家财产的事情”;
3. Java提供的互斥锁:synchronized
synchronized模型就是上面的改进锁模型,需要注意的是:
- Java中的lock和unlock这两个操作在synchronized中是被Java默默加上,不需要程序员去关心;这带来的好处就是不用去担心忘记解锁带来的问题;
关于synchronized,这里有我之前专门的一篇文章来进行介绍:https://wonderyang.github.io/2019/05/13/线程同步与死锁(synchronized关键字详解)/
4. 超典型的银行转账问题
案例分析:
- 账户类(Account)有两个成员变量,分别是账户余额balance和账户密码password;
- 该类提供两个方法来访问balance,分别是withdraw(取款)和getBalance(查看余额);
- 该类提供两个方法来访问password,分别是updatePassword(更改密码)和getPassword(查看密码);
1. 保护没有关联的多个资源
对于上述案例,我们要用怎样的锁来保护资源呢?
- (1)所有方法加上synchronized;
- (2)保护余额对应一个锁,账户密码对应一个锁;
上述两种方法,第一种假如更改密码和查看余额就不能同时进行,但理论上它两应该可以同时进行,因为他们操作的不是一个资源,不会出现线程安全的问题,采用方法一会导致效率严重下降;
下面就来实现一下第二种方案,这种方案中,用不同的锁对受保护资源进行精细化管理,能够提升性能,这种锁也叫细粒度锁(⭐);
class Account {
private String password;
private Integer balance;
//保护密码的锁
private final Object pwLock = new Object();
//保护余额的锁
private final Object balLock = new Object();
public void updatePassword(String newPassword) {
synchronized (pwLock) {
this.password = newPassword;
}
}
public String getPassword() {
synchronized (pwLock) {
return password;
}
}
public void withdraw(Integer amt) {
synchronized (balLock) {
this.balance -= amt;
}
}
public Integer getBalance() {
synchronized (balLock) {
return balance;
}
}
}
2. 保护有关联关系的多个资源
这里还是上面那个例子,同样有Account账户类,这里来讨论一下转账的问题,在A向B转账过程中,A账户余额要减少,B账户余额要增加,为了线程安全,A和B账户的余额都应该收到保护,那我们怎么去保护这两个有关联的资源呢?
设转账操作的方法为transfer;
1. 误区方式
误区:有人想到直接这样不就好了?:
class Account {
private Integer balance;
public synchronized void transfer(Account target, int amt) {
if(this.balance >= amt)
balance -= amt;
target.balance += amt;
}
}
这样做的话,我们new一个A账户和一个B账户,然后A账户进行转账操作,这时A账户就拿到了锁进入了transfer方法中,试问此时B账户能不能执行他自己的转账操作?
有人会说不能啊,那个方法都被A锁住了,是吗?A拿的那把锁是A的对象锁,跟B有什么关系,所以B此时也能执行自己的转账操作,此时并发问题就产生了嘛!!!
上面的问题就在:用A对象的锁试图去保护B账户这个资源,这当然是不行的;
举例分析:
我们假设线程 1 执行账户 A 转账户 B 的操作,线程 2 执行账户 B 转账户 C 的操作。这两个线程分别在颗 CPU 上同时执行,那它们是互斥的吗?我们期望是,但实际上并不是。因为线程 1 锁定的是账户 A 的实例(A.this),而线程 2 锁定的是账户 B 的实例(B.this),所以这两个线程可以同时进入临界区 transfer()。同时进入临界区的结果是什么呢?线程 1 和线程 2 都会读到账户 B 的余额为 200,导致最终账户 B 的余额可能是 300(线程 1 后于线程 2 写 B.balance,线程 2 写的 B.balance 值被线程 1 覆盖),可能是 100(线程 1 先于线程 2 写 B.balance,线程 1 写的 B.balance 值被线程 2 覆盖),就是不可能是 200。
2. 同一把锁方式
对于上面的转账操作,我们紧接着就会想到,用同一把锁就能解决问题了呀,这种方式是完全可以的,下面来看看代码:
class Account {
private Integer balance;
private Object transferLock;
public Account(Object transferLock) {
this.transferLock = transferLock;
}
public void transfer(Account target, int amt) {
synchronized (transferLock) {
if(this.balance >= amt) {
balance -= amt;
target.balance += amt;
}
}
}
}
这个方式的缺点:
- 要求在创建账户的同时就得传入同一个对象(指给需要转帐的那两个账户),如果出现了传入的不是同一对象,就会锁不住转账的两方;
- 在真实的项目中,创建Account对象的代码可能分布在各个工程中,传入共享的Lock就会变得很难;
3. 用全局锁(class对象锁)
这里直接上代码,众所周知,锁住class对象的话,创建的所有Account账户就会持有同一把锁,一旦锁住一个,其他账户的所有操作就都不能执行了,这样严重影响了并发,现实生活中的转账就不能影响到其他用户(除转账对象账户)的操作;
class Account {
private Integer balance;
public void transfer(Account target, int amt) {
synchronized (this.getClass()) {
if(this.balance >= amt) {
balance -= amt;
target.balance += amt;
}
}
}
}
4. 双重锁
对于上面的例子,还有一种方式可以解决:
class Account {
private Integer balance;
public void transfer(Account target, int amt) {
//锁定转出账户
synchronized (this) {
//锁定转入账户
synchronized (target) {
if(this.balance >= amt) {
balance -= amt;
target.balance += amt;
}
}
}
}
}
这种方法一看,挺好的呀,消除了3中的弊病,也消除了2中的弊病,但是这也有一个致命缺点,容易造成死锁;
具体的:
- 当A账户准备给B账户转账,进入第一个synchronized块后未进入第二个synchronized块之前,此时B账户也执行给A账户转账,也进入了第一个未进入第二个synchronized块,此时A账户等待B账户的锁,B账户等待A账户的锁,就进入了死锁状态;
这里再分析一下死锁,死锁的四个必要条件: (⭐)
-
互斥: 共享资源X和Y只能被一个线程占有;
- 这个条件我们无法破坏;
-
占有且等待: 线程1已经获得共享资源X,在等待共享资源Y的时候,不释放共享资源X;
- 我们可以设置一个类用来管理这两把锁,要么都拿到,要么都别拿,这样就不会出现各持一把锁的情况;
-
不可抢占: 其他线程不能强行抢占线程1占有的资源;
- 这里synchronized申请资源的时候,如果申请不到就直接进入阻塞,所以要破坏不可抢占得使用Lock,这里后面再具体说;
-
循环等待: 线程1等待线程2的占有的锁,线程2等待线程1占有的锁;
-
破坏这个条件,需要对资源进行排序,然后按序申请资源。这个实现非常简单,我们假设每个账户都有不同的属性 id,这个 id 可以作为排序字段,申请的时候,我们可以按照从小到大的顺序来申请。比如下面代码中,①~⑥处的代码对转出账户(this)和转入账户(target)排序,然后按照序号从小到大的顺序锁定账户。这样就不存在“循环”等待了。
代码如下:class Account { private int id; private int balance; // 转账 void transfer(Account target, int amt){ Account left = this //① Account right = target; //② if (this.id > target.id) { //③ left = target; //④ right = this; //⑤ } //⑥ // 锁定序号小的账户 synchronized(left){ // 锁定序号大的账户 synchronized(right){ if (this.balance > amt){ this.balance -= amt; target.balance += amt; } } } } }
-