hbase shell:打印中文,数据迁移
1, 在shell中调用hbase shll客户端
[root@eadage txt]# echo 'scan "'"t2"'"' |hbase shell
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
19/07/09 18:01:51 INFO Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
HBase Shell; enter 'help' for list of supported commands.
Type "exit" to leave the HBase Shell
Version 1.2.0-cdh5.12.0, rUnknown, Thu Jun 29 04:42:07 PDT 2017
scan "t2"
ROW COLUMN+CELL
r1 column=f:dept, timestamp=1560843778078, value=java
r4 column=f:name, timestamp=1562662995660, value=\xE7\x8E\x8B
2 row(s) in 0.2120 seconds
#####使用python打印16进制的value值
[root@eadage txt]# python
Python 2.6.6 (r266:84292, Aug 18 2016, 15:13:37)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-17)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> print("\xE7\x8E\x8B")
王
2,生成put语句: python,awk,sed
### 1,过滤原数据
[root@eadage txt]# echo 'scan "'"t2"'"' |hbase shell |grep column | awk -F',' '{print $1,$3}'
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
19/07/09 18:12:12 INFO Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
r1 column=f:dept value=java
r4 column=f:name value=\xE7\x8E\x8B
### 2, python解析16进制的值:
##awk '{print "print '\''"$0"'\''"}' |python
##或者sed "s/^/print('/; s/$/')/" |python
[root@eadage ~]# echo 'scan "'"t2"'"' |hbase shell |grep column | awk -F',' '{print $1,$3}' |sed "s/^/print('/; s/$/')/" |python
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
19/07/09 20:52:27 INFO Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
r1 column=f:dept value=java
r4 column=f:name value=王
### 3,去掉多余的字段,添加双引号:
## sed "s/ column=/', '/; s/ value=/','/; s/^ /'/; s/$/'/"
## 或者awk '{print "\""$1"\",", "\""$2"\",","\""$3"\""}'
[root@eadage ~]# echo 'scan "'"t2"'"' |hbase shell |grep column | awk -F',' '{print $1,$3}' |sed "s/^/print('/; s/$/')/" |python |sed "s/ column=/', '/; s/ value=/','/; s/^ /'/; s/$/'/"
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
19/07/09 20:59:31 INFO Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
"r1", "f:dept", "java"
"r4", "f:name", "王"
### 4,补充hbase put语句:
#sed "s/^/put /"
#或者 awk '{print "put \"t1""\", " $1,$2,$3}'
[root@eadage ~]# echo 'scan "'"t2"'"' |hbase shell |grep column | awk -F',' '{print $1,$3}' |sed "s/^/print('/; s/$/')/" |python |sed "s/ column=/', '/; s/ value=/','/; s/^ /'/; s/$/'/" | sed "s/^/put /"
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
19/07/09 21:27:14 INFO Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
put "t1", "r1", "f:dept", "java"
put "t1", "r4", "f:name", "王"
3, 编写脚本:实现hbase数组转移
在数据源处,执行此脚本(hbase_gen_put.sh),产生多个put语句文件,压缩为tar包后,传输到目标处
#1, 定义要用到的hbase表
arr=(
t1
t2
)
#2, 遍历数组
for x in ${arr[*]}
do
echo "=========="$x "====表, 生成put语句 为 $x.txt ====="
#第一步: 建表语句
echo create "'$x'" ,"'f'" > $x.txt
#第二步: 查询hbaes数据,生成put语句, 每个表put语句形成单独的文件
echo 'scan "'"$x"'"' |hbase shell |grep column | awk -F',' '{print $1,$3}' |sed "s/^/print('/; s/$/')/" |python |sed "s/ column=/', '/; s/ value=/','/; s/^ /'/; s/$/'/" | sed "s/^/put /" >> $x.txt
done
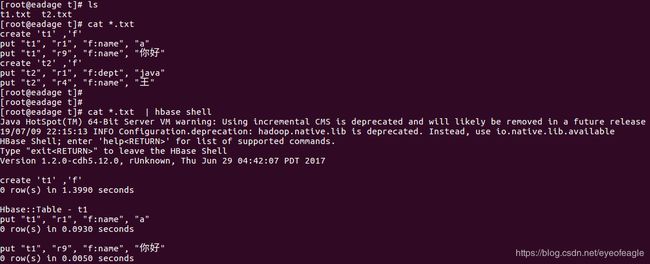
到目标处解压该文件,然后执行命令:
[root@eadage t]# ls
t1.txt t2.txt
[root@eadage t]# cat *.txt |hbase shell
.......