MySql Innodb存储引擎--文件和索引
MySql架构图
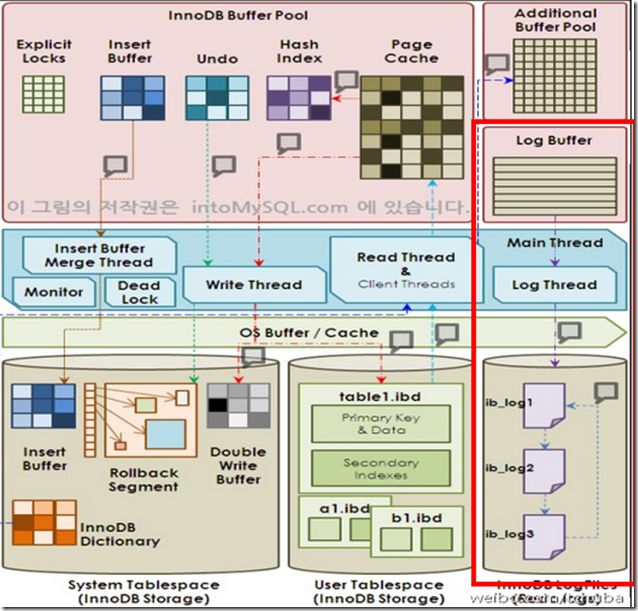
MySql文件类型
参数文件,启动时候需要的参数
日志文件,二进制文件(bin log),慢查询日志,查询日志,错误日志,重做日志(undo log)
socket文件,使用域socket连接时候用的
pid文件,进程的pid文件
表结构文件,存储表结构的定义
存储引擎文件,存放最终数据的
参数查询和修改
查询的参数在 INFORMATION_SCHEMA库中的GLOBAL_STATUS中,5.6之后的mysql默认是关闭的
set global show_compatibility_56=on;
可以使用上面命令打开
显示innodb相关的参数
Mysql代码 ![]()
- SHOW VARIABLES LIKE 'innodb%'
有些参数默认是修改会话级别的
Java代码 ![]()
- --修改当前会话的参数
- SET read_buffer_size=524288;
- --查询当前会话的参数值
- SELECT @@session.read_buffer_size;
- --查询这个值的全局值
- SELECT @@global.read_buffer_size;
- --如果要修改全局值,加上@@global前缀
- SET @@global.read_buffer_size=65535;
静态变量是只读的不可以修改
Mysql代码 ![]()
- --修改静态变量会报错
- SET GLOBAL datadir='sdff';
- Error Code : 1238
- Variable 'datadir' is a read only variable
- (0 ms taken)
MySql常见的日志文件有
1.错误日志
2.二进制日志bin log
3.慢查询日志 slow log
4.查询日志
查看错误日志
Mysql代码 ![]()
- SHOW VARIABLES LIKE 'log_error';
慢查询日志
Mysql代码 ![]()
- --慢查询日志是否开启
- SHOW VARIABLES LIKE 'slow_query_log';
- --慢查询日志存放位置
- SHOW VARIABLES LIKE 'slow_query_log_file';
- --查询超过多长时间就算是慢查询
- SHOW VARIABLES LIKE 'long_query_time';
- --查询相关的参数
- SHOW VARIABLES LIKE '%query%';
- --如果查询没有使用索引就在慢查询日志中记录这条sql
- SHOW VARIABLES LIKE 'log_queries_not_using_indexes%'
- --允许每分钟多少条没有使用索引的sql被记录到慢查询日志文件中
- SHOW VARIABLES LIKE 'log_throttle_queries_not_using_indexes%'
慢查询命令
mysqldumpslow
通过数据库表查看慢查询日志
Mysql代码 ![]()
- --查询日志保存的方式,默认为FILE
- SHOW VARIABLES LIKE 'log_output';
- --将查询日志保存到表中
- SET GLOBAL log_output='TABLE';
- --执行一个慢查询
- SELECT sleep(11);
- --通过表 mysql.slow_log可以查看刚才执行的慢查询
- --修改mysql.slow_log表存储引起为MyISAM
- SET GLOBAL slow_query_log=off;
- ALTER TABLE mysql.slow_log ENGINE=MyISAM;
查询日志
所有对主机进行查询的操作都会记录,甚至对Access denied的请求都会记录
二进制日志
二级制日志bin log记录所有对mysql更改的操作,加入一个update没有对任何行做修改,也会记录这条sql
Mysql代码 ![]()
- mysql> SHOW MASTER STATUS\G
- *************************** 1. row ***************************
- File: mysql2-bin.000010
- Position: 625203964
- Binlog_Do_DB:
- Binlog_Ignore_DB: mysql,information_schema,sys,performance_schema
- Executed_Gtid_Set:
- 1 row in set (0.08 sec)
binlog相关的参数
Mysql代码 ![]()
- SHOW VARIABLES LIKE 'binlog%';
bin log的位置
Mysql代码 ![]()
- SHOW VARIABLES LIKE 'datadir';
bin log相关的参数
Mysql代码 ![]()
- binlog_cache_size 32768
- binlog_checksum CRC32
- binlog_direct_non_transactional_updates OFF
- binlog_error_action ABORT_SERVER
- binlog_format MIXED
- binlog_group_commit_sync_delay 0
- binlog_group_commit_sync_no_delay_count 0
- binlog_gtid_simple_recovery ON
- binlog_max_flush_queue_time 0
- binlog_order_commits ON
- binlog_row_image FULL
- binlog_rows_query_log_events OFF
binlog的用途
1.数据恢复
2.复制,mysql的主从同步
3.审计,用户可以通过二进制日志中的信息来进行审计判断是否有sql注入
MySQL的bin-log日志备份有三种模式,分别是:ROW、Statement、Mixed
一、Row
日志会记录成每一行数据被修改成的形式,然后再slave端再对相同的数据进行修改,只记录要修改的数据,只有value,不会有sql多表关联的情况。
优点:在row模式下,bin-log中可以不记录执行的sql语句的上下文相关信息,仅仅需要记录哪一条记录被修改了,修改成什么信样了,所以row的日志内容会非常清楚的记录下每一行数据修改的细节,非常容易理解。而且不会出现在某些特定情况下的存储过程和function,以及trigger的调用和处罚无法被正确复制问题。
缺点:在row模式下,所有执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容。
二、Statement
每一条会修改数据的sql都会记录到master的binlog中,slave在复制的时候sql进程会解析成和原来master端相同的sql再执行。
优点:在Statement模式下首先就是解决了row模式下的缺点,不需要记录记录每一行日志的变化,减少了bin-log日志量,节省了I/O以及存储资源,提高性能。因为它们只需要激励在master上所执行的语句的细节以及执行语句时候的上下文信息。
缺点:在Statement模式下,由于它记录的执行语句,所以,为了让这些语句在slave端也能正确执行,那么它还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在slave端被执行的时候能够得到和在master端执行时候的结果。另外,由于MySQL现在发展较快,很多的新功能不断的加入,使MySQL的复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug也就越容易出现。在Statement中,目前已经发现不少情况会造成MySQL的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现。
三、Mixed
从官方文档中看到,之前的MySQL一直都只有基于Statement的复制模式,知道5.1.5版本的MySQL才开始支持row模式。从5.0开始,MySQL的复制已经解决了大量老版本中出现的无法正确复制的问题。但是由于存储过程的出现,给MySQL replication又带来了更大的挑战。另外,看到官方文档说,从5.1.8版本开始,MySQL提供了除Statement和row之外的第三种模式:mixed,实际上就是前两种模式的结合。在mixed模式下,MySQL会根据执行的每一条具体的sql语句来区分对待记录的日志形式,也就是在Statement和row之间选择一种。新版本中的Statement还是和以前一样,仅仅记录执行的语句。而新版本的MySQL中对row模式也做了优化,并不是所有的修改都会以row模式来记录,比如遇到表结构变更的时候就会以Statement模式来记录,如果sql语句确实是update或者delete等修改数据的语句,那么还是会记录所有行的变更。
套接字和pid文件
UNIX可以使用域套接字,存放地址
Java代码 ![]()
- SHOW VARIABLES LIKE 'socket';
pid文件的存放位置
Mysql代码 ![]()
- SHOW VARIABLES LIKE 'pid_file';
InnoDB存储引擎文件
Mysql代码 ![]()
- --表空间的存储位置,12M表示文件ibdata1的大小,autoextend为可以自动增长
- SHOW VARIABLES LIKE 'innodb_data_file_path';
- --ibdata1:12M:autoextend
- --每个表使用独立的表空间,命名规则是
- --表名.fm为表定义文件
- --表明.idb为数据文件
- SHOW VARIABLES LIKE 'innodb_file_per_table';
重做日志与二进制日志的区别
4.1 记录的范围不同:二进制日志会记录MySQL的所有存储引擎的日志记录(包括InnoDB、MyISAM等),而InnoDB存储引擎的重做日志只会记录其本身的事务日志。
4.2 记录的内容不同:二进制日志文件记录的格式可以为STATEMENT或者ROW也可以是MIXED,其记录的都是关于一个事务的具体操作内容。InnoDB存储引擎的重做日志文件记录的关于每个页的更改的物理情况。
4.3 写入的时间也不同:二进制日志文件是在事务提交前进行记录的,而在事务进行的过程中,不断有重做日志条目被写入到重做日志文件中。
重做日志相关的参数
Mysql代码 ![]()
- innodb_api_enable_binlog OFF
- innodb_flush_log_at_timeout 1
- innodb_flush_log_at_trx_commit 1
- innodb_locks_unsafe_for_binlog OFF
- innodb_log_buffer_size 1048576
- innodb_log_checksums ON
- innodb_log_compressed_pages ON
- innodb_log_file_size 50331648
- innodb_log_files_in_group 2
- innodb_log_group_home_dir .\\
- innodb_log_write_ahead_size 8192
- innodb_max_undo_log_size 1073741824
- innodb_online_alter_log_max_size 134217728
- innodb_undo_log_truncate OFF
- innodb_undo_logs 128
重做日志文件组结构图
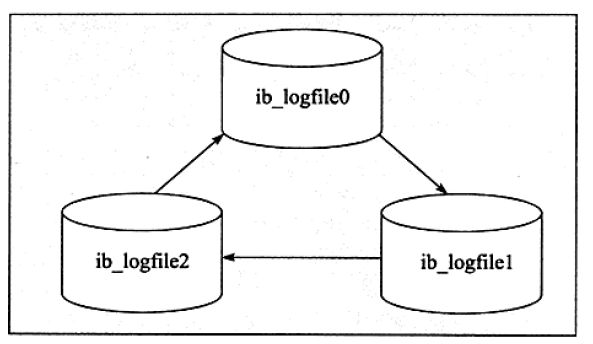
重做日志写入过程

查看innodb的版本和文件格式
Mysql代码 ![]()
- --查看版本
- SHOW VARIABLES LIKE 'innodb_version';
- --查看文件格式
- SHOW VARIABLES LIKE 'innodb_file_format';
Innodb表存储引擎文件架构
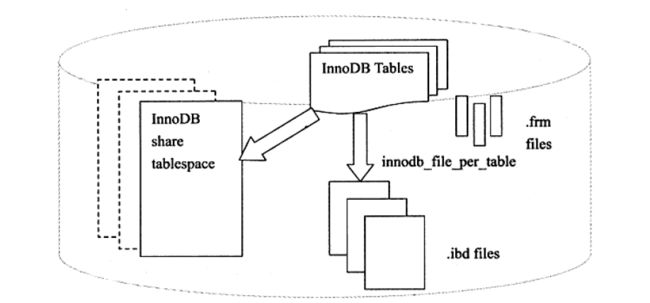
添加索引
Mysql代码 ![]()
- 1.PRIMARY KEY(主键索引)
- mysql>ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
- 2.UNIQUE(唯一索引)
- mysql>ALTER TABLE `table_name` ADD UNIQUE (
- `column` )
- 3.INDEX(普通索引)
- mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
- 4.FULLTEXT(全文索引)
- mysql>ALTER TABLE `table_name` ADD FULLTEXT ( `column` )
- 5.多列索引
- mysql>ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
自适应hash索引
只能用于类似这样的语句
Mysql代码 ![]()
- SELECT * FORM table_name WHERE index_col='xxx'
自适应hash相关的信息,通过 SHOW ENGINE INNODB STATUS查看
Mysql代码 ![]()
- -------------------------------------
- INSERT BUFFER AND ADAPTIVE HASH INDEX
- -------------------------------------
- Ibuf: size 1, free list len 0, seg size 2, 94 merges
- merged operations:
- insert 280, delete mark 0, delete 0
- discarded operations:
- insert 0, delete mark 0, delete 0
- Hash table size 4425293, node heap has 1337 buffer(s)
- 174.24 hash searches/s, 169.49 non-hash searches/s
可以通过下面参数来禁用或启动此特性,默认是开启
Mysql代码 ![]()
- innodb_adaptive_hash_index
全文索引
Mysql代码 ![]()
- MATCH (列名1, 列名2,…) AGAINST (搜索字符串 [搜索修饰符])
- search_modifier:
- {
- IN NATURAL LANGUAGE MODE
- | IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
- | IN BOOLEAN MODE
- | WITH QUERY EXPANSION
- }
几种全文索引类型
1)IN NATURAL LANGUAGE MODE
简介:默认的搜索形式(不加任何搜索修饰符或者修饰符为 IN NATURAL LANGUAGE MODE 的情况)
特点:
对于搜索字符串中的字符都解析为正常的字符,没有特殊意义
对屏蔽字符列表中的字符串进行过滤
当记录的选择性超过50%的时候,通常被认为是不匹配。
返回记录按照记录的相关性进行排序显示
Mysql代码 ![]()
- SELECT * FROM product WHERE match(name) against(‘auto’)
2)IN BOOLEAN MODE
简介:布尔模式搜索(搜索修饰符为IN BOOLEAN MODE的情况)
特点:
会按照一定的规则解析搜索字符串中的特殊字符的含义,进行一些逻辑意义的规则。如:某个单词必须出现,或者不能出现等。
这种类型的搜索返回的记录是不按照相关性进行排序的
Mysql代码 ![]()
- SELECT * FROM articles WHERE MATCH (title,body) AGAINST (‘+MySQL -YourSQL’ IN BOOLEAN MODE);
3)WITH QUERY EXPANSION
简介:一种稍微复杂的搜索形式,实际上是进行了2次自然搜索,可以返回记录直接简介性关系的记录,修饰词IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION 或者WITH QUERY EXPANSION modifier
特点:这种类型的搜素,实际上提供了一种间接的搜索功能,比如:我搜索某个词,而且返回的第一行中却不包含搜索词中的任意字符串。可以根据第一次搜索结果的记录词进行第二次匹配,从而可能找到一些间接关系的匹配记录。
AuxiliaryTable是持久的表,存放在磁盘上,然而在InnoDB存储引擎的全文索引中,还有另外一个重要的概念FTSIndexCache(全文检索索引缓存),其用来提高全文检索的性能
InnoDB存储引擎会批量对AuxiliaryTable进行更新.而不是每次插入后更新一次AuxiliaryTable.当全文检索进行查询时,AuxiliaryTable首先会将在FTSIndexCache中对应的word字段合并到AuxiliaryTable中,然后进行查询。这种merge操作非常类似之前的InsertBuffer功能。不同的是InsertBuffer是个持久性的对象,并且是B+树结构,然后FTSIndexCache的作用又和InsertBuffer类似,它提高了InnoDB存储引擎的性能,并且由于其根据红黑树排序后进行批量插入,其产生的AuxiliaryTable相对较小
可以通过设置innodb_ft_aux_table来观察倒排索引的AuxiliaryTable下面的SQL语句设置查看test架构下表fts_a的AuxiliaryTable:
Mysql代码 ![]()
- SET GLOBAL innodb_ft_aux_table='test/fts_a';
B+树索引
聚集索引
任何一个表都会有一个主键如果没有就默认创建一个,然后顺序写入磁盘,主键的存储方式是物理上顺序的,通过主键的根和非根节点找到叶子节点,也就是数据节点。

辅助索引
这种索引的page类型跟数据节点是一样的,存储到磁盘上当时也是一个连续的B+树结构,但是逻辑上不是连续的,通过扫描辅助索引就可以找到聚集索引,然后再找到真实数据
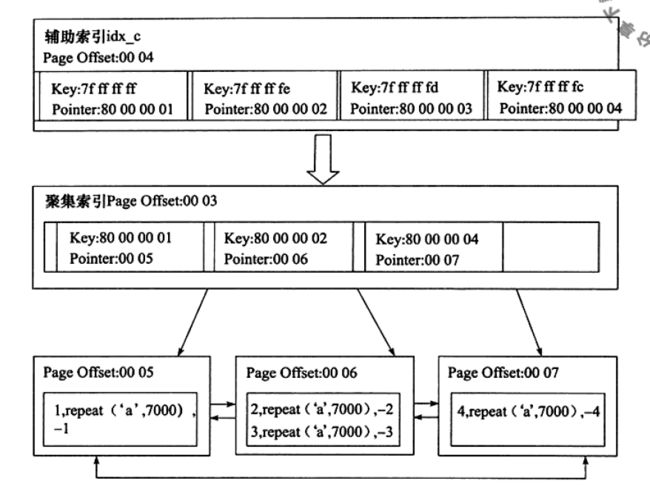
联合索引
内部也是B+树结构,联合索引的第一个索引可能是排序好的,第二个索引就不是有序的了
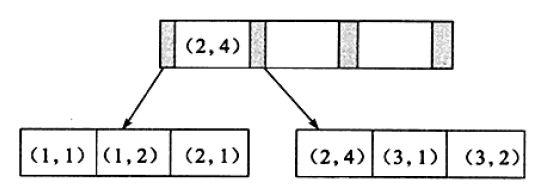
SHOW INDEX FROM [table_name] 后显示的每个字段含义
1.Table 表的名称。
2.Non_unique 如果索引不能包括重复词,则为0。如果可以,则为1。
3.Key_name 索引的名称。
4.Seq_in_index 索引中的列序列号,从1开始。
5.Column_name 列名称。
6.Collation 列以什么方式存储在索引中。在MySQL中,有值‘A’(升序)或NULL(无分类)。
7.Cardinality
索引中唯一值的数目的估计值。通过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机会就越大。
8.Sub_part 如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。
9.Packed 指示关键字如何被压缩。如果没有被压缩,则为NULL。
10.Null 如果列含有NULL,则含有YES。如果没有,则该列含有NO。
11.Index_type 用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。
12.Comment 多种评注。
Cardinality
Cardinality统计信息的更新发生在两个操作中:insert和update。InnoDB存储引擎内部对更新Cardinality信息的策略为:
1)表中1/16的数据已发生了改变(如果全部都是update则需要第二个操作配合使用)
2)stat_modified_counter>2000 000 000
默认的InnoDB存储引擎对8个叶子节点Leaf Page进行采用。采用过程如下
取得B+树索引中叶子节点的数量,记为A
随机取得B+树索引中的8个叶子节点,统计每个页不同记录的个数,即为P1,P2....P8
通过采样信息给出Cardinality的预估值:Cardinality=(P1+P2+...+P8)*A/8
索引统计相关参数
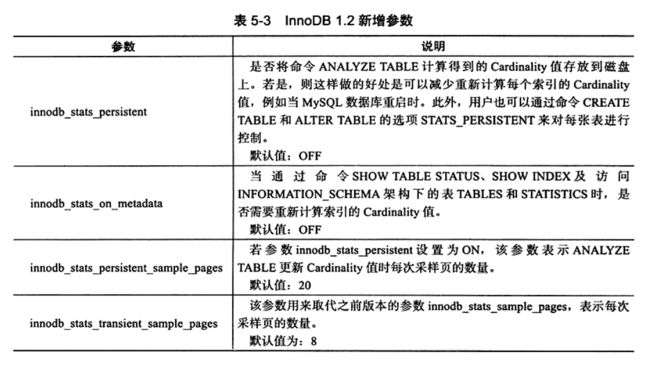
索引优化器会根据Cardinality的结果决定是否使用索引,不是加了索引就会一定使用索引的
可以建议MySql引擎使用索引
Mysql代码 ![]()
- --增加一个 USE INDEX的语句,提示引擎使用索引
- SELECT * FROM t USE INDEX(a) WHERE a=1 AND b=2;
但是仍然不能保存最终一定会使用索引,可以强制使用引擎用某个索引
Mysql代码 ![]()
- SELECT * FROM t FORCE INDEX(a) WHERE a=1 AND b=2;
Multi-Range Read
MRR原理,MySQL 将根据辅助索引获取的结果集根据主键进行排序,将乱序化为有序,可以用主键顺序访问基表,将随机读转化为顺序读,多页数据记录可一次性读入或根据此次的主键范围分次读入,以减少IO操作,提高查询效率。
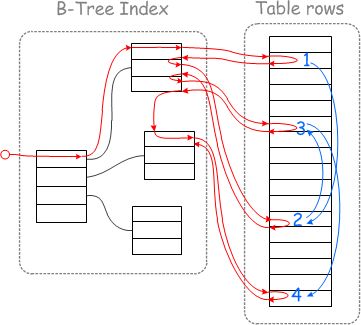
首先根据辅助索引得到主键,然后再查询最终数据,因为辅助索引在逻辑上不是连续的所以得到的主键都是离散的,这样查询就变成随机IO了
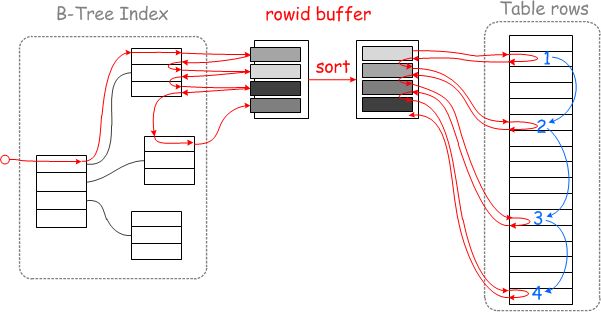
改变的策略是将获取到的主键放到内存中进行一次排序,因为主键的顺序就是数据存放的顺序,所以排序玩之后的读取就变成顺序IO了,效率会提高很多
Index Condition Pushdown
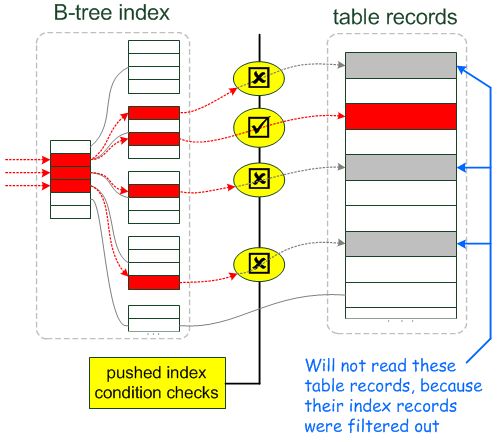
使用ICP时,where的条件可以再一次过滤减少不必要的IO提高效率,可以跟MMR一起使用
注意一下ICP的使用条件:
只能用于二级索引(secondary index)。
explain显示的执行计划中type值(join 类型)为range、 ref、 eq_ref或者ref_or_null。且查询需要访问表的整行数据,即不能直接通过二级索引的元组数据获得查询结果(索引覆盖)。
参考
Antelope 和Barracuda区别
MyISAM和InnoDB的行格式ROW_FORMAT
mysql innoDB重做日志文件
MySQL全文索引应用简明教程
理解B+树算法和Innodb索引
MySQL 和 B 树的那些事
倒排索引原理和实践
搜索引擎-倒排索引基础知识
MySQL5.6新特性之Multi-Range Read
MySQL5.6之Index Condition Pushdown(ICP,索引条件下推)
MySql优化参数