轻量级目标检测框架MobileNet-SSD在Caffe下实现的流程步骤
Caffe下实现MobileNet-SSD流程步骤详解
- MobileNet-v1介绍
- MobileNet-SSD下载及文件说明
- 针对VOC0712数据集训练
- 对作者训练好的模型进行测试
- 直接进行模型测试
- 融合批归一化层进行测试
- 利用MobileNet-SSD对NEUDataset进行finetune
- 网络训练
- 网络测试
- 实际测试图片展示
- 关于MobileNet的DepthwiseConvolution在caffe下的实现
本篇博客将涉及对Mobilenet-v1的简单介绍、Mobilenet-SSD的下载及文件说明、网络训练部分、网络测试部分、批归一化融合验证、finetune训练、DepthwiseConvolution即深度可分离卷积在caffe下的实现等内容。
数据集制作及下载请参考我的这篇博客:目标检测SSD网络在Caffe下的实现——基于VOC0712数据集
数据来源:VOC0712、NEUDataset
模型:MobileNet-SSD(基于MobileNet-v1)
系统:Linux-Ubuntu
MobileNet-v1介绍
论文链接:MobileNets: EfficientConvolutionalNeuralNetworksforMobileVision Applications
MobileNet是Google提出了一个轻量型网络模型,其发展到今天一共有v1、v2、v3三种变形和升级。
本次只涉及到v1的简单讲解。
v1使用深度可分离卷积(depthwise separatable convolutions),即Xception变体结构构建了一个轻量级的深度网络,模型大小只有十几M。
-
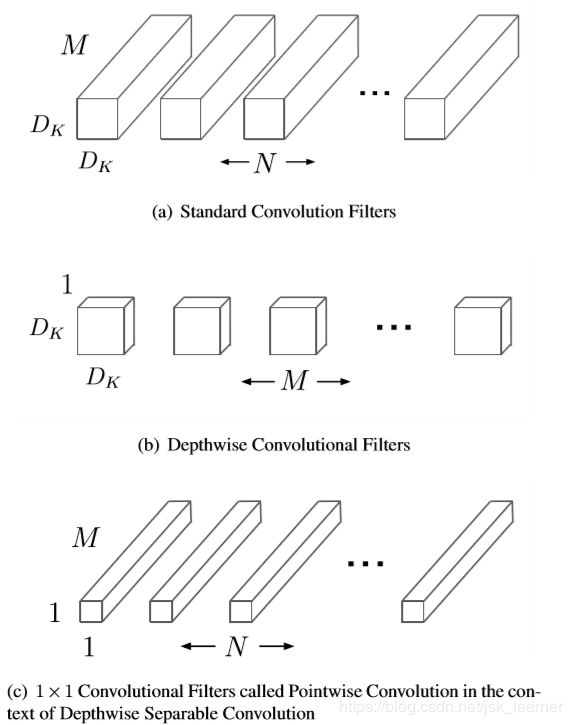
深度可分离卷积
是将标准卷积分解为深度卷积(depthwise convolution)和逐点卷积(pointwise convolution)。
-
标准卷积
对于一次卷积过程
输入F:(DF,DF,M),其中DF表示输入feature map尺寸,M表示输入特征维度;
卷积核K:(DK,DK,M,N),其中DK表示卷积核尺寸,N表示有多少个卷积核,即输出的特征维度;
输出G:(DG,DG,DG,N),其中DG表示输出feature map尺寸,N表示输出特征维度;
计算量: DK x DK x M x N x DF x DF -
深度可分离卷积
输入F:(DF,DF,M),其中DF表示输入feature map尺寸,M表示输入特征维度;
depthwise:(DK,DK,1,M),其中M表示用M个卷积核对输入M个通道作卷积操作(是对应进行操作的吗?),输出通道也为M;
输出:(DG,DG,DG,M),深度卷后的输出
pointwise: (1,1,M,N),卷积核尺寸为1X1,输出通道为N,表示用N个1x1卷积核对输入M个通道分别作卷积,输出为N个通道;
输出G:(DG,DG,DG,N);
计算量: DK x DK x 1 x M x DF x DF + M x N x DG x DG -
计算量对比
标准卷积 / 深度卷积= N + DK2
在这里,为了便于计算量对比值,对于深度可分离卷积的计算量 DG x DG部分简化为DF x DF,因为一般来说 DG x DG小于DF x DF,更能说明计算量的对比明显,即使用深度可分离卷积操作,MobileNet-v1显著降低了模型的参数。
因此可以看出深度卷积(depthwise)完成的操作是改变feature map的尺寸大小,而逐点卷积(pointwise)相当于对feature map作全卷积操作,改变的是输出的通道数。
本质上完成的功能和标准卷积一致,但是降低了模型参数。
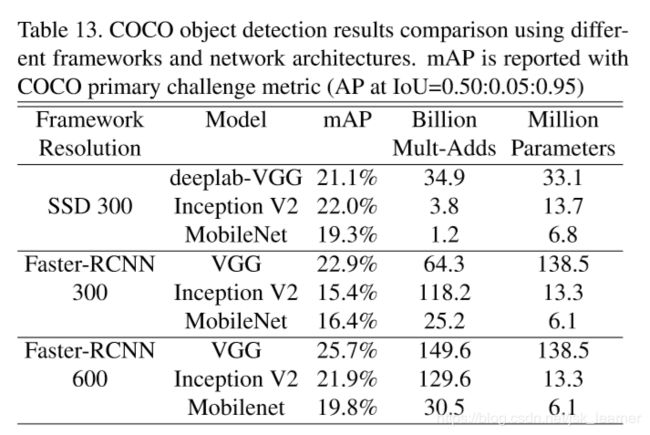
- 使用MobileNet作为特征提取网络,以SSD和Faster-RCNN为例,在coco数据集上mAP值对比:
MobileNet-SSD下载及文件说明
我使用的是Github上chuanqi305的网络结构: Github-MobileNet-SSD下载
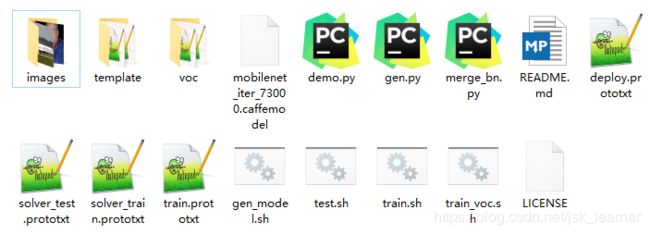
| 文件名 | 文件说明 |
|---|---|
| images | 测试模型图片 |
| template | train、test、deploy模板网络结构,在使用gen_model.sh自动生成针对不同类别下的网络结构时会用到 |
| voc | 以voc 21个类别生成的网络结构 |
| mobilenet_iter_73000.caffemodel | 其训练好的网络模型 |
| demo.py | 测试用的脚本代码 |
| gen.py | 生成网络结构的代码 |
| merge_bn.py | 融合batch_normalization层,用在测试推理过程中,可以提高推理速度 |
| gen_model.sh | 针对具有不同类别数量数据集生成相应的网络结构,需要用到template下的文件 |
| test.sh | 进行模型测试,给出loss和mAP值 |
| train.sh | 进行模型训练 |
| train_voc.sh | 对VOC进行训练,区别不大 |
| deploy.prototxt和train.prototxt | 网络结构 |
| solver_test.prototxt和solver_train.prototxt | 训练和测试时的超参设置 |
针对VOC0712数据集训练
先说明一下,这部分没有成功。
用MobileNet-SSD对VOC0712数据集直接训练,mAP值低的出乎意料
起初,我怀疑是数据集制作有问题,但是我用同样的数据集在vgg-ssd下可以达到一个和官方差不多的结果即mAP值,可以参考我的这篇博客(目标检测SSD网络在Caffe下的实现——基于VOC0712数据集),所以不会是数据集的问题。
后来我去详细看了一下README.md文件,原来作者是将tensorflow下训练好的模型转成了caffemodel,然后又在coco数据集下进行预训练,最后才在VOC数据集下进行训练才达到一个mAP=0.727的效果。
- 作者原话如下:
I trained this model from a MobileNet classifier(caffemodel and prototxt) converted from tensorflow.
I first trained the model on MS-COCO and then fine-tuned on VOC0712.
Without MS-COCO pretraining, it can only get mAP=0.68.
所以我就先不在voc数据集进行训练了。
对作者训练好的模型进行测试
直接进行模型测试
使用的模型:作者训练好的mobilenet_iter_73000.caffemodel
使用的网络结构:deploy.prototxt
- 精度测试
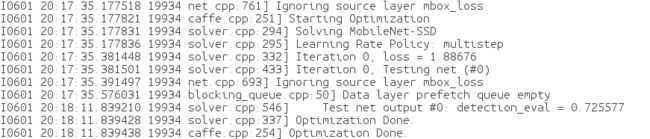
sudo sh test.sh
结果如下图,精度为0.726,和作者给出的mAP差不多。
- 实际图片测试
执行脚本命令:
python2 demo.py
因为我的caffe是和python2一起编译的,所以如果你是python3,直接
python demo.py
- 一些检测的图片展示:



可见效果还是不错的。
不过如果你在运行demo.py或者merge_bn.py程序遇到如下错误的时候,请将deploy.prototxt中注释掉的#engine: CAFFE不进行注释,大概有13处,即凡是涉及到深度可分离卷积计算的层都要进行uncomment,出现该问题应该是因为mobilenet的depthwise计算时和cudnn不适配。
不过,我在运行demo.py程序时 ,没遇到这个问题,但是在运行merge_bn.py程序时遇到了此问题。
Check failed: status == CUDNN_STATUS_SUCCESS (4 vs. 0) CUDNN_STATUS_INTERNAL_ERROR

融合批归一化层进行测试
终端命令下执行:
python2 merge_bn.py --weights=mobilenet_iter_73000.caffemodel --model=deploy_uncomment.prototxt
可以看到,目录下会生成两个新的文件:
分别是去除批归一化层后的caffemodel和prototxt。

接下来验证一下融合归一化层之后的模型推理速度提升。
- 在demo.py中添加几行代码
start = time.time()
out = net.forward()
end = time.time()
没有进行归一化融合的网络模型前向传播(推理)的速度,测试7张图片平均时间为0.75
进行归一化融合后的网络模型前向传播速度,测试7张的平均时间为0.36
可以判断,进行批归一化层融合,前向传播时间大概有2倍时间缩短。
- 使用融合批归一化层进行实际图片测试:


可见,融合归一化层并不会造成模型推理出现问题,同时速度提升很多。
利用MobileNet-SSD对NEUDataset进行finetune
网络训练
使用MobileNet对NEUDataset进行finetune训练的步骤,和使用vgg-ssd进行finetune没有什么区别,只不过使用MobileNet-SSD进行finetune时不用对涉及到类别数量的分类层进行命名修改。
具体可参考我这篇博客: 利用caffe-ssd对钢材表面缺陷数据集(NEUDataset)进行finetune训练和测试
设置好相应的路径后
运行sudo sh train.sh即可
- train.sh
#!/bin/sh
if ! test -f example/MobileNetSSD_train_dw.prototxt ;then
echo "error: example/MobileNetSSD_train.prototxt does not exist."
echo "please use the gen_model.sh to generate your own model."
exit 1
fi
mkdir -p snapshot_no_change_base_lr
GLOG_logtostderr=0 GLOG_log_dir=./example/log_no_change_base_lr/ ../../build/tools/caffe train -solver="solver_train.prototxt" \
-weights="mobilenet_iter_73000.caffemodel" \
-gpu 1
我一直认为进行finetune时,要把base_lr调低的,但是使用MobileNet-SSd对NEUDataset进行finetune时,我分别将base_lr调低10倍与不将base_lr进行调整,结果却是不将base_lr调整的mAP值高。
| base_lr | mAP |
|---|---|
| 0.00005 | 0.682 |
| 0.0005 | 0.701 |
网络测试
修改demo.py代码,使之能够对测试图片进行批量分类预测和位置预测并保存预测后的图片。
- 修改后的代码如下:
import numpy as np
import sys,os
import cv2
sys.path.insert(0,'/home1/xxx/caffe_ssd/python')
import caffe
import time
net_file= '/home1/xxx/caffe_ssd/examples/MobileNet-SSD/example/MobileNetSSD_deploy_dw.prototxt'
caffe_model='/home1/xxx/caffe_ssd/examples/MobileNet-SSD/snapshot_no_change_base_lr/_iter_119000.caffemodel'
test_dir = "/home1/xxx/caffe_ssd/examples/MobileNet-SSD/test/IMAGES/"
if not os.path.exists(caffe_model):
print(caffe_model + " does not exist")
exit()
if not os.path.exists(net_file):
print(net_file + " does not exist")
exit()
net = caffe.Net(net_file,caffe_model,caffe.TEST)
CLASSES = ('background','crazing','inclusion','patches','pitted_surface','rolled-in_scale','scratches')
def preprocess(src):
img = cv2.resize(src, (300,300))
img = img - 128.329
img = img * 0.007843
return img
def postprocess(img, out):
h = img.shape[0]
w = img.shape[1]
box = out['detection_out'][0,0,:,3:7] * np.array([w, h, w, h])
cls = out['detection_out'][0,0,:,1]
conf = out['detection_out'][0,0,:,2]
return (box.astype(np.int32), conf, cls)
def detect(imgfile):
origimg = cv2.imread(imgfile)
img = preprocess(origimg)
img = img.astype(np.float32)
img = img.transpose((2, 0, 1))
net.blobs['data'].data[...] = img
out = net.forward()
box, conf, cls = postprocess(origimg, out)
img_name = imgfile.split('/')[-1]
print(img_name)
for i in range(len(box)):
p1 = (box[i][0], box[i][1])
p2 = (box[i][2], box[i][3])
cv2.rectangle(origimg, p1, p2, (0,255,0))
p3 = (max(p1[0], 15), max(p1[1], 15))
title = "%s:%.2f" % (CLASSES[int(cls[i])], conf[i])
cv2.putText(origimg, title, p3, cv2.FONT_ITALIC, 0.6, (0, 255, 0), 1)
cv2.imwrite(os.path.join('/home1/xxx/caffe_ssd/examples/MobileNet-SSD/detect_demo_1/',img_name), origimg)
for f in os.listdir(test_dir):
start= time.time()
if detect(test_dir + "/" + f) == False:
break
end = time.time()
print("run_time:", end-start)
实际测试图片展示
效果还是要好于vgg-ssd,但是对于crazing这一缺陷,都表现的不是特别好。不过我回过头去看ground truth,发现制作数据集的人,在对这一缺陷标注时也有点一言难尽,暂且不管。
- crazing

- inclusion
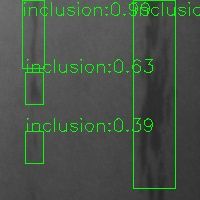
- patches
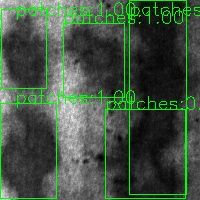
- pitted_surface

- rolled-in_scale

- scatches

关于MobileNet的DepthwiseConvolution在caffe下的实现
请参考我的这篇博客:MobileNet DepthwiseConvolution、ShuffleNet shuffle channel、CenterLoss在Caffe下实现
至此,MobileNet-SSD在Caffe的实现的流程步骤已经讲解完毕,包括。
希望能帮助到大家。谢谢。
2019.7.12