Kubernetes的Service外部访问方式:NodePort和LoadBalancer
Kubernetes的Service外部访问方式:NodePort和LoadBalancer
Kubernetes的Pod的寿命是有限的,它们不会复活,因此尽管每个Pod都有自己的IP地址,但是这些IP地址是不可靠的,会随着Pod的消亡而消失。
这就带来一个问题,如果一些Pod的集合(称之为backends)为集群的其他的Pod(称之为frontends),这些frontends应该如何找到并一直知道哪些backends在这样的集合中呢?
这就需要引入Service, 一个kubernetes的service是一种抽象,它定义了一个Pod的逻辑集合和一个用于访问它们的策略。一个Service的目标Pod的集合通常是由Label Selector来决定的。
举个例子,想象一个处理图片的后端运行了三个副本。这些副本都是可以替代的,前端不关心它们使用的是哪一个后端。尽管实际组成后端集合的Pod可能会变化,前端的客户端却不需要知道这个变化,也不需要自己有一个列表来记录这些后端服务。Service抽象能让你达到这种解耦。
对于那些Kubernetes原生的应用,Kubernetes提供了一个简单的Endpoints API,会在Service中的Pod集合发生改变的时候更新。对于非Kubernetes原生的应用,Kubernetes为Service提供了一种基于虚拟IP的桥接方式使其重定向到后端的Pods。
定义一个Service
Kubernetes中的Service是一个REST对象,这点与Pod类似。正如所有的REST对象一样,向apiserver POST一个Service的定义就能创建一个新的实例。例如,假设你有一组Pods,每一个Pod都开放了9376端口,并且都有一个"app=MyApp"的标签。
![]()
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"protocol": "TCP",
"port": 80,
"targetPort": 9376
}
]
}
}![]()
这个定义会创建一个新的Service对象,名字为”my-service”,它指向所有带有”app=MyApp”标签的Pod上面的9376端口。这个Service同时也会被分配一个IP地址(有时被称作”cluster ip”),它会被服务的代理所使用(见下面)。这个Service的选择器,会不断的对Pod进行筛选,并将结果POST到名字同样为“my-service”的Endpoints对象。
注意一个Service能将一个来源的端口映射到任意的targetPort。默认情况下,targetPort会被设置成与port字段一样的值。可能更有意思的地方在于,targetPort可以是一个字符串,能引用一个后端Pod中定义的端口名。实际指派给该名称的端口号在每一个Pod中可能会不同。这为部署和更新你的Service提供了很大的灵活性。例如,你可以在你的后端的下一个版本中更改开放的端口,而无需导致客户出现故障。
Kubernetes的Service支持TCP和UDP协议。默认是TCP。
发布 services - service的类型
Kubernetes的ServiceTypes能让你指定你想要哪一种服务。默认的和基础的是ClusterIP,这会开放一个服务可以在集群内部进行连接。NodePort 和LoadBalancer是两种会将服务开放给外部网络的类型。
ServiceType字段的合法值是:
l ClusterIP: 仅仅使用一个集群内部的IP地址 - 这是默认值。选择这个值意味着你只想这个服务在集群内部才可以被访问到。
l NodePort: 在集群内部IP的基础上,在集群的每一个节点的端口上开放这个服务。你可以在任意
l LoadBalancer: 在使用一个集群内部IP地址和在NodePort上开放一个服务之外,向云提供商申请一个负载均衡器,会让流量转发到这个在每个节点上以
在使用一个集群内部IP地址和在NodePort上开放一个Service的基础上,还可以向云提供者申请一个负载均衡器,将流量转发到已经以NodePort形式开发的Service上。
注意尽管NodePort可以是TCP或者UDP的,对于Kubernetes 1.0来说,LoadBalancer还支持TCP。
NodePort类型
如果你把type字段设置为"NodePort",Kubernetes的master就会从由启动参数配置的范围(默认是:30000-32767)中分配一个端口,然后每一个Node都会将这个端口(在每一个Node上相同的端口)代理到你的Service。这个端口会被写入你的Service的spec.ports[*].nodePort字段中。
如果你想要一个特定的端口号,你可以在nodePort字段中指定一个值,确保系统能为你分配这个端口,否则API请求将会失败(例如你需要自己处理可能出现的端口冲突)。你指定的值必须在节点端口配置的范围内。
这给了开发者了设置他们自己的负载均衡器的自由,配置那些没有被Kubernetes完全支持的云环境,或者甚至可以直接开放一个或者多个节点的IP。
这种Service可以同时以
LoadBalancer类型
在那些支持外部负载均衡器的云提供者上面,将type字段设置为"LoadBalancer"会为你的Service设置好一个负载均衡器。该负载均衡器的实际的创建是异步进行的,并且该设置好均衡器会在该Service的status.loadBalancer字段中显示出来。例如:
![]()
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"protocol": "TCP",
"port": 80,
"targetPort": 9376,
"nodePort": 30061
}
],
"clusterIP": "10.0.171.239",
"loadBalancerIP": "78.11.24.19",
"type": "LoadBalancer"
},
"status": {
"loadBalancer": {
"ingress": [
{
"ip": "146.148.47.155"
}
]
}
}![]()
从外部负载均衡器的流量将会被引到后端的Pod,然而具体这个如何实现则要看云提供商。一些云提供商允许指定loadBalancerIP。在这种场景,负载均衡器将随用户指定的loadBalancerIP一起创建。如果字段loadBalancerIP没有指定,该负载均衡器会被指定一个短暂性的IP。如果指定了loadBalancerIP,但是云提供商不支持这个特性,这个字段会被忽略。
Kubernetes的三种外部访问方式:NodePort、LoadBalancer和Ingress
2018年04月18日 13:47:55 Docker_ 阅读数:2008

最近有些同学问我 NodePort,LoadBalancer 和 Ingress 之间的区别。它们都是将集群外部流量导入到集群内的方式,只是实现方式不同。让我们看一下它们分别是如何工作的,以及你该如何选择它们。
注意:这里说的每一点都基于Google Kubernetes Engine。如果你用 minikube 或其它工具,以预置型模式(om prem)运行在其它云上,对应的操作可能有点区别。我不会太深入技术细节,如果你有兴趣了解更多,官方文档[1]是一个非常棒的资源。ClusterIP
![]()
ClusterIP 服务是 Kubernetes 的默认服务。它给你一个集群内的服务,集群内的其它应用都可以访问该服务。集群外部无法访问它。
ClusterIP 服务的 YAML 文件类似如下:
apiVersion: v1
kind: Service
metadata:
name: my-internal-service
selector:
app: my-app
spec:
type: ClusterIP
ports:
- name: http
port: 80
targetPort: 80
protocol: TCP
如果 从Internet 没法访问 ClusterIP 服务,那么我们为什么要讨论它呢?那是因为我们可以通过 Kubernetes 的 proxy 模式来访问该服务!
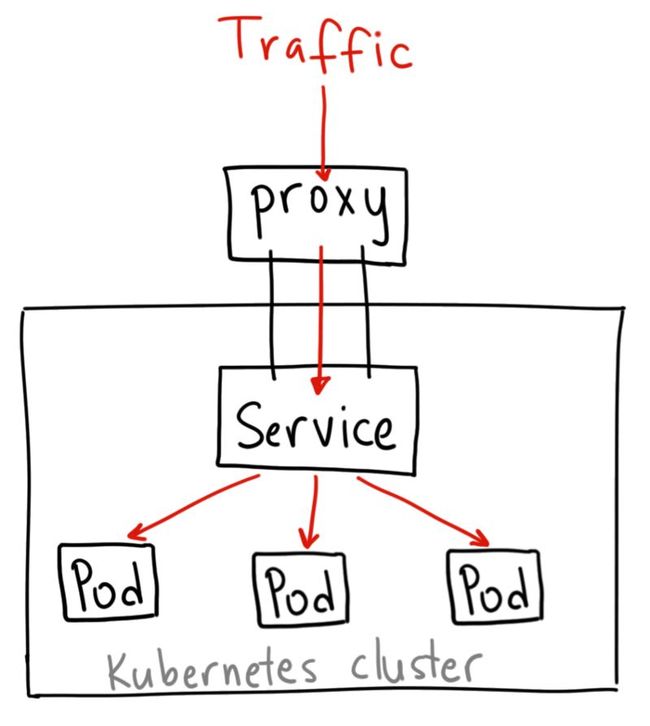
启动 Kubernetes proxy 模式:
$ kubectl proxy --port=8080
这样你可以通过Kubernetes API,使用如下模式来访问这个服务:
http://localhost:8080/api/v1/proxy/namespaces//services/:/
要访问我们上面定义的服务,你可以使用如下地址:
http://localhost:8080/api/v1/proxy/namespaces/default/services/my-internal-service:http/
何时使用这种方式?
有一些场景下,你得使用 Kubernetes 的 proxy 模式来访问你的服务:
-
由于某些原因,你需要调试你的服务,或者需要直接通过笔记本电脑去访问它们。
-
容许内部通信,展示内部仪表盘等。
这种方式要求我们运行 kubectl 作为一个未认证的用户,因此我们不能用这种方式把服务暴露到 internet 或者在生产环境使用。NodePort
![]()
NodePort 服务是引导外部流量到你的服务的最原始方式。NodePort,正如这个名字所示,在所有节点(虚拟机)上开放一个特定端口,任何发送到该端口的流量都被转发到对应服务。
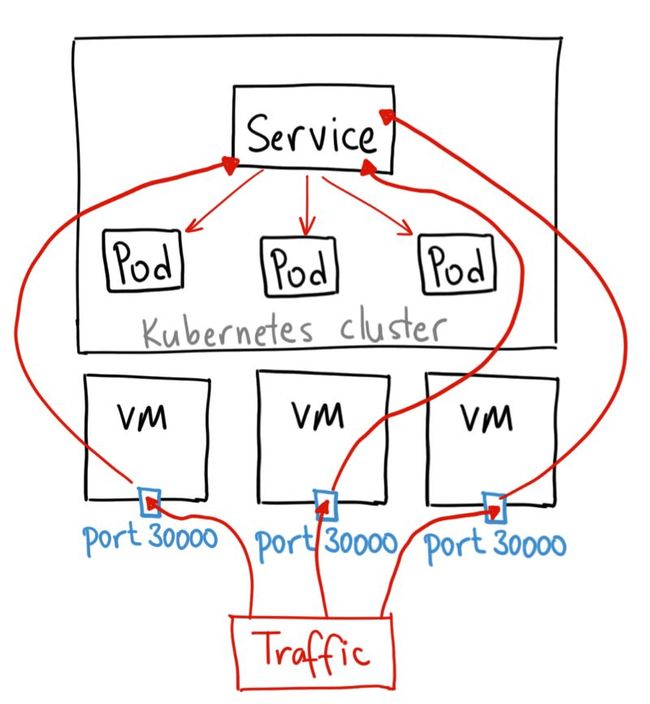
NodePort 服务的 YAML 文件类似如下:
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service
selector:
app: my-app
spec:
type: NodePort
ports:
- name: http
port: 80
targetPort: 80
nodePort: 30036
protocol: TCP
NodePort 服务主要有两点区别于普通的“ClusterIP”服务。第一,它的类型是“NodePort”。有一个额外的端口,称为 nodePort,它指定节点上开放的端口值 。如果你不指定这个端口,系统将选择一个随机端口。大多数时候我们应该让 Kubernetes 来选择端口,因为如评论中 thockin 所说,用户自己来选择可用端口代价太大。
何时使用这种方式?
这种方法有许多缺点:
-
每个端口只能是一种服务
-
端口范围只能是 30000-32767
-
如果节点/VM 的 IP 地址发生变化,你需要能处理这种情况
基于以上原因,我不建议在生产环境上用这种方式暴露服务。如果你运行的服务不要求一直可用,或者对成本比较敏感,你可以使用这种方法。这样的应用的最佳例子是 demo 应用,或者某些临时应用。LoadBalancer
![]()
LoadBalancer 服务是暴露服务到 internet 的标准方式。在 GKE 上,这种方式会启动一个 Network Load Balancer[2],它将给你一个单独的 IP 地址,转发所有流量到你的服务。
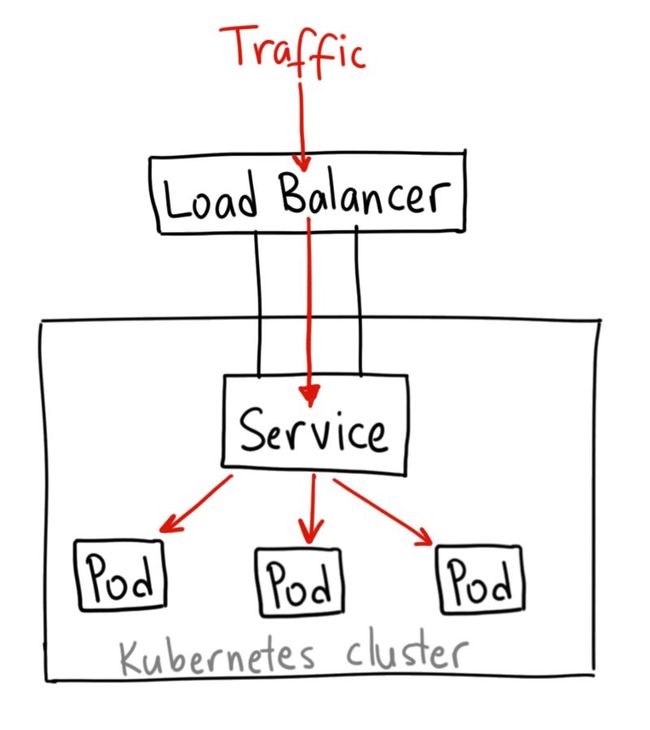
何时使用这种方式?
如果你想要直接暴露服务,这就是默认方式。所有通往你指定的端口的流量都会被转发到对应的服务。它没有过滤条件,没有路由等。这意味着你几乎可以发送任何种类的流量到该服务,像 HTTP,TCP,UDP,Websocket,gRPC 或其它任意种类。
这个方式的最大缺点是每一个用 LoadBalancer 暴露的服务都会有它自己的 IP 地址,每个用到的 LoadBalancer 都需要付费,这将是非常昂贵的。Ingress
![]()
有别于以上所有例子,Ingress 事实上不是一种服务类型。相反,它处于多个服务的前端,扮演着“智能路由”或者集群入口的角色。
你可以用 Ingress 来做许多不同的事情,各种不同类型的 Ingress 控制器也有不同的能力。
GKE 上的默认 ingress 控制器是启动一个 HTTP(S) Load Balancer[3]。它允许你基于路径或者子域名来路由流量到后端服务。例如,你可以将任何发往域名 foo.yourdomain.com 的流量转到 foo 服务,将路径 yourdomain.com/bar/path 的流量转到 bar 服务。
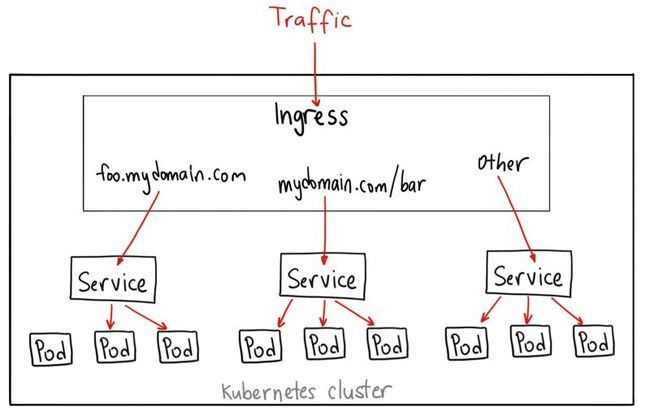
GKE 上用 L7 HTTP Load Balancer[4]生成的 Ingress 对象的 YAML 文件类似如下:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: my-ingress
spec:
backend:
serviceName: other
servicePort: 8080
rules:
- host: foo.mydomain.com
http:
paths:
- backend:
serviceName: foo
servicePort: 8080
- host: mydomain.com
http:
paths:
- path: /bar/*
backend:
serviceName: bar
servicePort: 8080
何时使用这种方式?
Ingress 可能是暴露服务的最强大方式,但同时也是最复杂的。Ingress 控制器有各种类型,包括 Google Cloud Load Balancer, Nginx,Contour,Istio,等等。它还有各种插件,比如 cert-manager[5],它可以为你的服务自动提供 SSL 证书。
如果你想要使用同一个 IP 暴露多个服务,这些服务都是使用相同的七层协议(典型如 HTTP),那么Ingress 就是最有用的。如果你使用本地的 GCP 集成,你只需要为一个负载均衡器付费,且由于 Ingress是“智能”的,你还可以获取各种开箱即用的特性(比如 SSL、认证、路由等等)。
相关链接:
-
https://kubernetes.io/docs/concepts/services-networking/service/
-
https://cloud.google.com/compute/docs/load-balancing/network/
-
https://cloud.google.com/compute/docs/load-balancing/http/
-
https://cloud.google.com/compute/docs/load-balancing/http/
-
https://github.com/jetstack/cert-manager
原文链接:https://medium.com/google-cloud/kubernetes-nodeport-vs-loadbalancer-vs-ingress-when-should-i-use-what-922f010849e0
通过nodePort,对外暴露k8s集群服务
https://blog.csdn.net/yjk13703623757/article/details/79818223
1. 原理
有时,我们需要向外部暴露一些k8s集群的服务。这时,我们可以指定service的port类型为nodePort来实现。例如k8s集群中有三个node节点:
- 192.168.0.1
- 192.168.0.2
- 192.168.0.3
则我们可以通过192.168.0.1:nodePort(也可以是192.168.0.2:nodePort,192.168.0.3:nodePort)访问k8s集群内部的服务。
默认的nodePort的范围是30000-32767, k8s会从中随机选择一个端口,我们也可以在spec.ports.nodePort中指定一个端口。
当然,我们可以修改apiserver的启动参数 --service-node-port-range来指定nodePort范围,如:--service-node-port-range 8000-9000
2. 实现
我们需要在service的yaml定义中指定nodePort:
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
type: NodePort // 指定service类型
selector:
app: forme
ports:
- port: 80 // 供集群中其它服务访问的端口
targetPort: 8020 // 后端pod中container暴露的端口
nodePort: 9000 // 节点暴露的端口
---
apiVersion: v1
kind: ReplicationController
metadata:
name: forme
namespace: default
spec:
replicas: 1
selector:
app: forme
template:
metadata:
name: forme
labels:
app: forme
spec:
volumes:
- name: "config"
hostPath:
path: "/data/xxx"
containers:
- name: forme
image: forme:k8s
#command: ["/bin/sh", "-c"]
#args: ["tail -f /dev/null"]
#args: ["sleep 20"]
resources:
limits:
alpha.kubernetes.io/nvidia-gpu: 1
#cpu: 8
#memory: 4Gi
ports:
- containerPort: 8020 // 该container监听的端口
volumeMounts:
- name: "config"
mountPath: "/home/docker/code"
3. 验证
当服务启动以后,我们可以通过
# lsof -i:9000查看端口情况。如果端口已经打开,但是其他节点无法访问,要查看防火墙设置,关闭防火墙即可。
4. 参考文章
https://www.jianshu.com/p/ce1028c1cbc0
Kubernetes如何支持有状态服务的部署?
作者:Jack47
转载请保留作者和原文出处 https://www.cnblogs.com/Jack47/p/deploy-stateful-application-on-Kubernetes.html
PS:如果喜欢我写的文章,欢迎关注我的微信公众账号程序员杰克,两边的文章会同步,也可以添加我的RSS订阅源。
Kubernetes对无状态服务有完善的支持,但是对于有状态的服务,是从1.3版本开始,才逐渐支持的。
有状态的应用程序
一般情况下,nginx或者web server(不包含MySQL)自身都是不需要保存数据的,对于 web server,数据会保存在专门做持久化的节点上。所以这些节点可以随意扩容或者缩容,只要简单的增加或减少副本的数量就可以。但是很多有状态的程序都需要集群式的部署,意味着节点需要形成群组关系,每个节点需要一个唯一的ID(例如Kafka BrokerId, Zookeeper myid)来作为集群内部每个成员的标识,集群内节点之间进行内部通信时需要用到这些标识。传统的做法是管理员会把这些程序部署到稳定的,长期存活的节点上去,这些节点有持久化的存储和静态的IP地址。这样某个应用的实例就跟底层物理基础设施比如某台机器,某个IP地址耦合在一起了。Kubernets中StatefulSet的目标是通过把标识分配给应用程序的某个不依赖于底层物理基础设施的特定实例来解耦这种依赖关系。(消费方不使用静态的IP,而是通过DNS域名去找到某台特定机器)
StatefulSet
前提
使用StatefulSet的前提:
- Kubernetes集群的版本 >=1.5
- 安装好DNS集群插件,版本 >=15
特点
StatefulSet(1.5版本之前叫做PetSet)为什么适合有状态的程序,因为它相比于Deployment有以下特点:
- 稳定的,唯一的网络标识,可以用来发现集群内部的其他成员。比如StatefulSet的名字叫kafka,那么第一个起来的Pet叫kafka-0,第二个叫 kafk-1,依次类推。
- 稳定的持久化存储:通过Kubernetes的PV/PVC或者外部存储(预先提供的)来实现
- 启动或关闭时保证有序:优雅的部署和伸缩性: 操作第n个pod时,前n-1个pod已经是运行且准备好的状态。 有序的,优雅的删除和终止操作:从 n, n-1, ... 1, 0 这样的顺序删除
上述提到的“稳定”指的是Pod在多次重新调度时保持稳定,即存储,DNS名称,hostname都是跟Pod绑定到一起的,跟Pod被调度到哪个节点没关系。
所以Zookeeper, Etcd 或 Elasticsearch这类需要稳定的集群成员的应用时,就可以用StatefulSet。通过查询无头服务域名的A记录,就可以得到集群内成员的域名信息。
限制
StatefulSet也有一些限制:
- Pod的存储必须是通过 PersistentVolume Provisioner基于
storeage类来提供,或者是管理员预先提供的外部存储 - 删除或者缩容不会删除跟StatefulSet相关的卷,这是为了保证数据的安全
- StatefulSet现在需要一个无头服务(Headless Service)来负责生成Pods的唯一网络标示,需要开发人员创建这个服务
- 对
StatefulSet的升级是一个手工的过程
无头服务(Headless Service)
要定义一个服务(Service)为无头服务(Headless Service),需要把Service定义中的ClusterIP配置项设置为空: spec.clusterIP:None。和普通Service相比,Headless Service没有ClusterIP(所以没有负载均衡),它会给一个集群内部的每个成员提供一个唯一的DNS域名来作为每个成员的网络标识,集群内部成员之间使用域名通信。无头服务管理的域名是如下的格式:$(service_name).$(k8s_namespace).svc.cluster.local。其中的 "cluster.local"是集群的域名,除非做了配置,否则集群域名默认就是cluster.local。StatefulSet下创建的每个Pod,得到一个对应的DNS子域名,格式如下:
$(podname).$(governing_service_domain),这里 governing_service_domain是由StatefulSet中定义的serviceName来决定。举例子,无头服务管理的kafka的域名是:kafka.test.svc.cluster.local, 创建的Pod得到的子域名是 kafka-1.kafka.test.svc.cluster.local。注意这里提到的域名,都是由kuber-dns组件管理的集群内部使用的域名,可以通过命令来查询:
$ nslookup my-nginx
Server: 192.168.16.53
Address 1: 192.168.16.53
Name: my-nginx
Address 1: 192.168.16.132而普通Service情况下,Pod名字后面是随机数,需要通过Service来做负载均衡。
当一个StatefulSet挂掉,新创建的StatefulSet会被赋予跟原来的Pod一样的名字,通过这个名字来匹配到原来的存储,实现了状态保存。因为上文提到了,每个Pod的标识附着在Pod上,无论pod被重新调度到了哪里。
成员发现
一个Pod可以通过 Downward api机制来知道自己的pod名字,也可以运行hostname来发现自己的DNS名字。StatefuleSet的服务名(governing service)在创建的时刻就已知了,所以只需要通过一个约定的环境变量把服务名传递给POD就可以。
一点八卦
为什么从PetSet改名字到StatefulSet,也是很有意思的,感兴趣的同学可以去这里看看:
Please Consider changing the name of PetSet before General Availability
实例
Kubernetes官方博客上有一个在Kubernetes上运行MogoDB的例子,见这里。
借用一下里面的架构图:
在StatefulSet之上运行MongoDB
如果您看了本篇博客,觉得对您有所收获,请点击右下角的“推荐”,让更多人看到!
资助Jack47写作,打赏一个鸡蛋灌饼吧

微信打赏

支付宝打赏