NLP学习笔记(一):图解Transformer+实战
感谢Jay Alammar,图源自他的文章[17]。
文章目录
- 1. Transformer原理
- 1.1 高层Transformer
- 1.2 Encoder输入:
- 2 Self-Attention:
- 2.1 Self-Attention步骤:
- 2.2 $Query$、$Key$、$Value$:
- 2.3 Multi-Head Attention:
- 2.4 位置嵌入来表示序列的顺序信息:
- 3 残差网络(Residuals Network):
- 4. Keras实现:
- 4.1 自注意力机制:
- 4.2 求位置嵌入向量:
- 参考资料:
1. Transformer原理
1.1 高层Transformer
Transformer最初是在机器翻译中提出,所以我们以机器翻译为例。任何一个神经网络模型都可以认为是一个黑箱,Transformer也不例外。

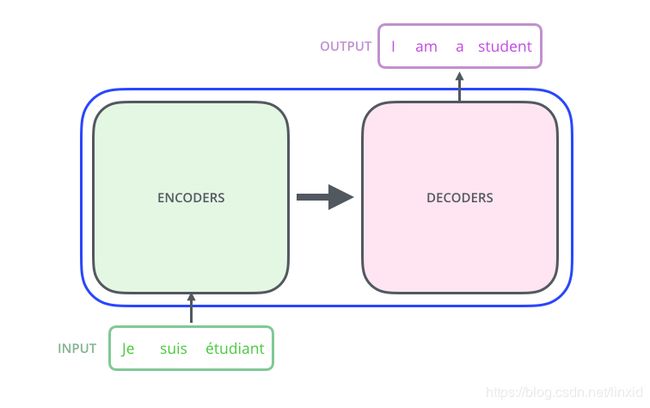
再往里面一层,Transformer是一个Encoder-Decoder结构,结构如下图所示:
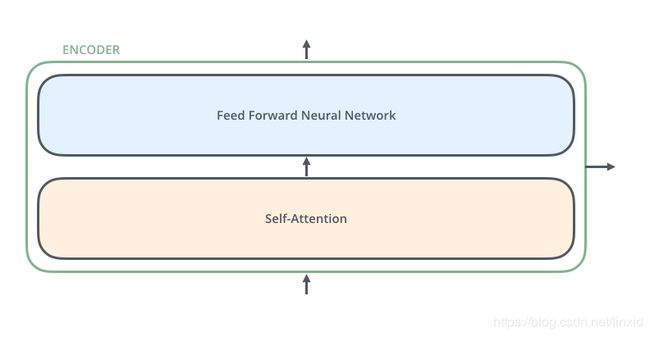
每一个Encoder是由self-attention+Feed Forward NN构成,如下图所示,所以我们首先要理解self-attention。
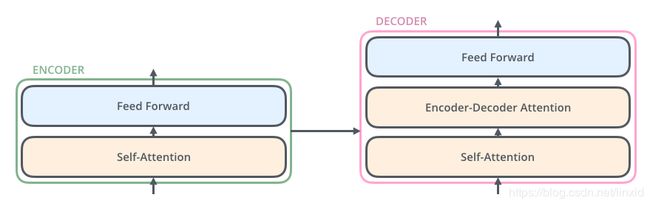
每一个Decoder是由Self-Attention+Encoder-Decoder Attention+Feed Forward NN构成,结构如下图所示:
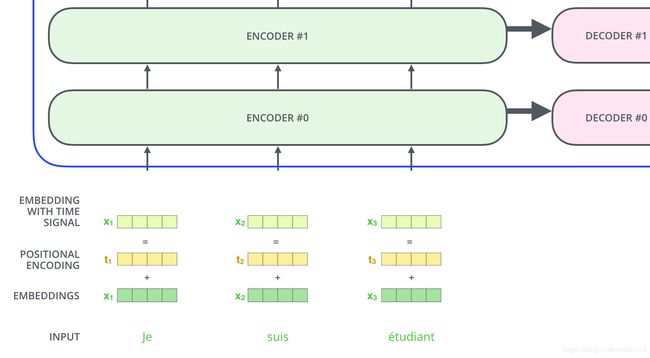
1.2 Encoder输入:
假设我们的输入三个词,三个词通过Embedding层后,每个词变成一个向量,如下图所示:

除了最底层输入是词的Embedding,其他层的输入是上一层的输出。这三个词在Encoder中的变换是:

Self-Attention是输入的第一层NN,比较难理解,却是模型的核心组成部分。所以我们单独拿出来讲。
2 Self-Attention:
关于注意力机制详细可以看张俊林博士的文章[3],此处讲解self-attention,更简单易懂。
以机器翻译为例,假设我们的输入是:
“The animal didn't cross the street because it was too tired”
在翻译的是时候我们希望将it和The animal联系起来,通过注意力机制可以实现这个需求。可以在Tensor2Tensor notebook 进行测试,观察每个词和其他词的对应关系(连接权重)。

2.1 Self-Attention步骤:
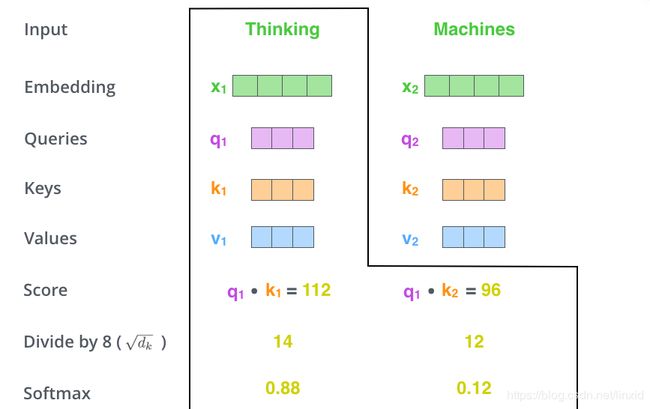
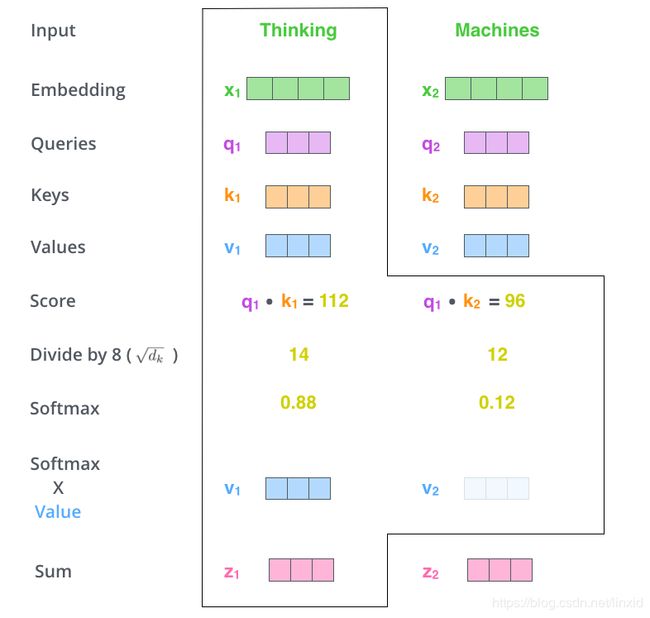
- 将输入词转变成词向量,即得到Embedding层;
- 每个词向量得到一个 Q u e r y Query Query向量, K e y Key Key向量和 V a l u e Value Value向量(下面说如何得到);
- 为每一个词向量计算一个 s c o r e : q u e r y . d o t ( k ) score :query.dot(k) score:query.dot(k);
我们需要计算句子中的每一个词对当前词的 s c o r e score score。这个 s c o r e score score决定对句子的其他部分注意力是多少,也就是如何用句子的其他部分类表征当前词。

- 对 s c o r e score score进行归一化(为了稳定),即除以 d k \sqrt{d_k} dk,然后对 s c o r e score score求 s o f t m a x ( ) softmax( ) softmax(): s c o r e = s o f t m a x ( s c o r e d k ) score = softmax(\frac{score}{\sqrt{d_k}}) score=softmax(dkscore)
- s c o r e score score和 V a l u e Value Value向量点积,然后对其求和: z = ∑ s c o r e ∗ V a l u e z = \sum{score * Value} z=∑score∗Value;
完结撒花,一图以蔽之:
2.2 Q u e r y Query Query、 K e y Key Key、 V a l u e Value Value:
刚才挖下的坑,现在来填。刚才我们提到这三个向量但是没有说如何得到的。
将我们的词向量矩阵 X X X和权重矩阵 W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV相乘,即可得到 Q u e r y Query Query、 K e y Key Key、 V a l u e Value Value向量。
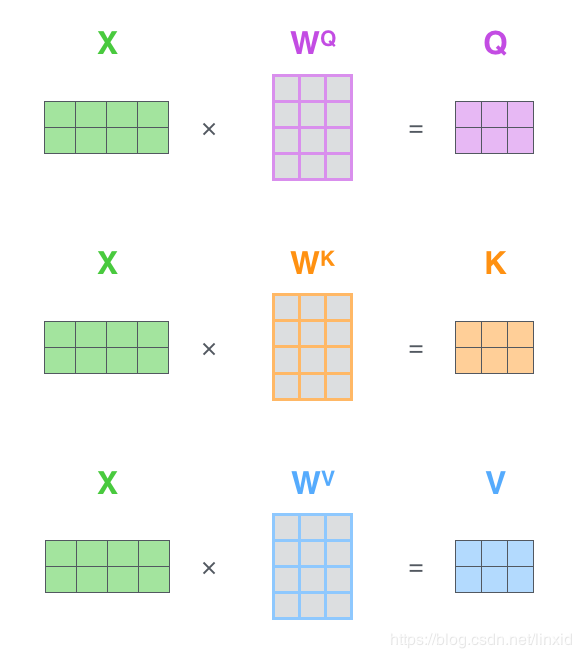
接下来这张图可以清晰的说明白 Q u e r y Query Query、 K e y Key Key、 V a l u e Value Value三个向量的关系。

2.3 Multi-Head Attention:
- 将词向量数据 X X X分别输入到8个不同的Self-Attention中,得到8个特征矩阵 Z i , i ∈ ( 1 , 2...8 ) Z_i,i\in{(1,2...8)} Zi,i∈(1,2...8):
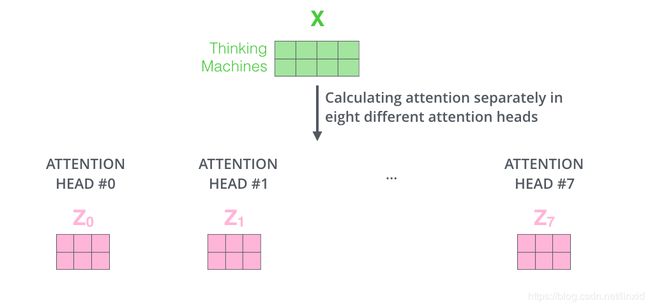
- 8个矩阵无法直接与前馈全连接相乘,所以对8个矩阵拼接,然后与一个权重矩阵 W O W_O WO相乘:
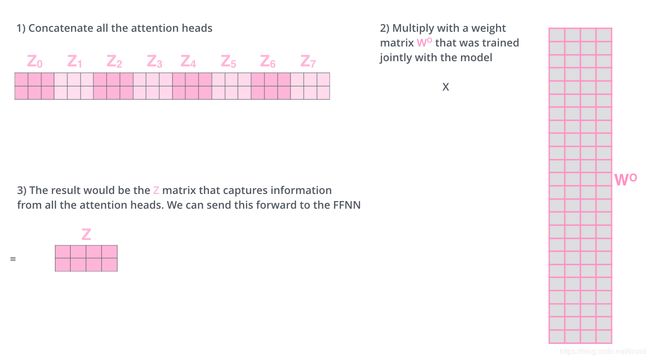
- 一图总结:
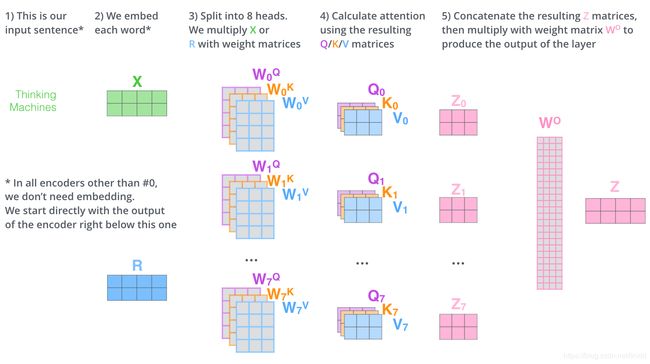
Multi-Head Attention的优点:
- 扩展模型能力可以注意到不同位置,一个注意力模型的关注点也许是错的,通过多个注意力模型可以提高这种泛化能力;
- 使得注意力层具有多个表示子空间,比如说上文的8个注意力模型,经过训练后,我们就可以将输入的词嵌入映射到8个不同的表示子空间;
2.4 位置嵌入来表示序列的顺序信息:
Transformer模型的一大缺点是不能捕捉句子的位置信息。试想我们的句子不管如何打乱,从刚才的原理可以看出,Transformer的结果都是相同的。为了解决这个问题,论文中在编码词向量时引入了位置编码(Position Embedding),词的位置信息通过位置编码来表示。
论文中令位置嵌入的维度和词向量的维度相同,然后与词向量相加。位置嵌入,可以帮我们判断每个词的位置和词向量之间的距离。
论文中的位置嵌入公式是:
P E ( p o s , 2 i ) = s i n ( p o s 100 0 2 i / d m o d e l ) PE_{(pos,2i)} = sin(\frac{pos}{1000^{2i/d_{model}}}) PE(pos,2i)=sin(10002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = c o s ( p o s 100 0 2 i / d m o d e l ) PE_{(pos,2i+1)} = cos(\frac{pos}{1000^{2i/d_{model}}}) PE(pos,2i+1)=cos(10002i/dmodelpos)
以上便是Slef-Attention的全部内容。
3 残差网络(Residuals Network):
构成Transformer的Encoder除了上述部分还有残差网络和一层归一化,通过图可以更容易明白。
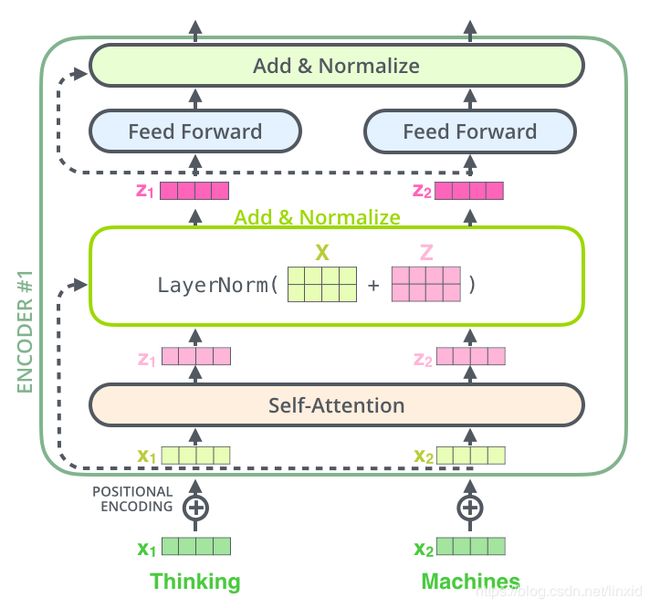
4. Keras实现:
4.1 自注意力机制:
2.1中详细介绍的Self-Attention可以通过下列代码实现。忘记的可以和前面的公式去对应。
class ScaledDotProductAttention():
def __init__(self, d_model, attn_dropout=0.1):
self.temper = np.sqrt(d_model)
self.dropout = Dropout(attn_dropout)
def __call__(self, q, k, v, mask):
attn = Lambda(lambda x:K.batch_dot(x[0],x[1],axes=[2,2])/self.temper)([q, k])
if mask is not None:
mmask = Lambda(lambda x:(-1e+10)*(1-x))(mask)
attn = Add()([attn, mmask])
attn = Activation('softmax')(attn)
attn = self.dropout(attn)
output = Lambda(lambda x:K.batch_dot(x[0], x[1]))([attn, v])
return output, attn
4.2 求位置嵌入向量:
详细公式可以见2.4,以下为keras实现:
def GetPosEncodingMatrix(max_len, d_emb):
pos_enc = np.array([
[pos / np.power(10000, 2 * (j // 2) / d_emb) for j in range(d_emb)]
if pos != 0 else np.zeros(d_emb)
for pos in range(max_len)
])
pos_enc[1:, 0::2] = np.sin(pos_enc[1:, 0::2]) # dim 2i
pos_enc[1:, 1::2] = np.cos(pos_enc[1:, 1::2]) # dim 2i+1
return pos_enc
未完待续…有空继续更新
参考资料:
[1]AllenNLP 使用教程
[2]从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
[3]深度学习中的注意力模型(2017版)
[4]模型汇总24 - 深度学习中Attention Mechanism详细介绍:原理、分类及应用
[5]Tensorflow源码解读(一):Attention Seq2Seq模型
[6]基于Attention Model的Aspect level文本情感分类—用Python+Keras实现
[7]完全图解RNN、RNN变体、Seq2Seq、Attention机制
[8]浅谈Attention-based Model【原理篇】
[9] 浅谈 NLP 中的 Attention 机制
[10]Deep Learning基础–理解LSTM/RNN中的Attention机制
[11]Attention? Attention!
[12]详解Transformer (Attention Is All You Need)
[13]The Annotated Transformer-Harvard出品
[14] 聊聊 Transformer
[15]Transformer Translation Model-TensorFlow官方实现
[16] BERT大火却不懂Transformer?读这一篇就够了
[17] The Illustrated Transformer
[18] Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
[19] Transformer注解及PyTorch实现(上)