linux学习篇5--- 文件系统 实体连接与符号链接 磁盘 分割挂载 格式化 swap
linux学习篇5---- 《鸟哥的Linux私房菜基础学习篇(第三版)》读书笔记
1.文件系统特性
Linux 操作系统的档案权限(rwx)与文件属性(拥有者、群组、时间参数等)。 文件系统通常会将这两部分的数据分别存放在不同癿区块,权限与属性放置到inode中,至于实际数据则放置到 datablock区块中。 另外,还有一个超级区块 (superblock) 会记录整个文件系统的整体信息,包括 inode 不 block 的总量、使用量、剩余量等。
superblock:记录此 filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及文件系统的格式与相关信息等;
inode:记录档案的属性,一个档案占用一个inode,同时记录此档案的数据所在的每个 block 号码;
block:实际记录档案的内容,若档案太大时,会占用多个 block 。
inode/block 资料存取示意图
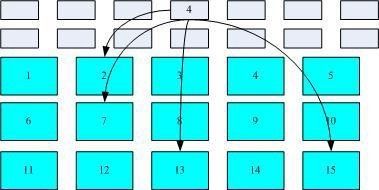
如图 第一个为索引式文件系统(linux) 第二个为Fat 没有inode 无法一次读出所有的block号 所以一个文件的block分散太厉害的话 容易出现磁盘碎片
ps. df指令查看挂载情况
2.与目录树的关系
当我们在 Linux 下的 ext 文件系统建立一个目录时, ext会分配一个 inode 与至少一块 block 给该目录。其中,inode 记录该目录的相关权限与属性,并可记录分配到的那块block 号码; 而block则是记录在这个目录下的文件名与该文件名占用的 inode 号码数据。
3.EXT3/EXT4 档案的存取
新增一个档案,此时文件系统的行为是:
1. 先确定用户对于欲新增档案的目彔是否具有 w 与 x 的权限,若有的话才能新增;
2. 根据 inode bitmap 找到没有使用的 inode 号码,并将新档案的权限/属性写入;
3. 根据 block bitmap 找到没有使用中的 block 号码,并将实际的数据写入 block 中,且更新 inode 的 block 指向数据;
4. 将刚刚写入的 inode 与 block 数据同步更新 inode bitmap 与 block bitmap,并更新 superblock 的内容。
4.日志式文件系统 (Journaling filesystem)
为了避免意外中断导致inode block中数据未同步到中介数据中去(上边的第四步)我们的前辈们想到一个方式, 如果在我们的 filesystem 当中规划出一个区块,该区块专门在记录写入或修订档案时的步骤, 那不就可以简化一致性检查的步骤了?也就是说:
1. 预备:当系统要写入一个档案时,会先在日志记录区块中记录某个档案准备要写入的信息;
2. 实际写入:开始写入档案的权限与数据;开始更新 metadata 的数据;
3. 结束:完成数据与 metadata 的更新后,在日志记录区块当中完成该档案的记录。
在这样的程序当中,万一数据的记录过程当中发生了问题,那么我们的系统只要去检查日志记录区块, 就可以知道那个档案发生了问题,针对该问题来做一致性的检查即可,而不必针对整块 filesystem 去检查, 这样就可以达到快速修复 filesystem 的能力了!这就是日志式档案最基础的功能。
5.Linux 文件系统的运作:
异步处理:
当系统加载一个档案到内存后,如果该档案没有被更改过,则在内存区段的档案数据会被设定为干净
(clean)的。 但如果内存中的档案数据被更改过了(例如你用 vi 去编辑过这个档案),此时该内存中的
数据会被设定为脏的 (Dirty)。此时所有的动作都还在内存中执行,并没有写入到磁盘中! 系统会不定
时的将内存中设定为『Dirty』的数据写回磁盘,以保持磁盘与内存数据的一致性。 你也可以利用 sync 指令来强迫写入磁盘。
Linux 文件系统与内存的关系:
系统会将常用的档案数据放置到主存储器的缓冲区,以加速文件系统的读/写;
承上,因此 Linux 的物理内存最后都会被用!加速系统效能;
你可以手动使用 sync 来强迫内存中设定为 Dirty 的档案回写到磁盘中;
若正常关机时,关机指令会主动呼叫 sync 来将内存的数据回写入磁盘内;
但若不正常关机(如跳电、当机或其他不明原因),由于数据尚未回写到磁盘内, 因此重新启动后
可能会花很多时间在进行磁盘检验,甚至可能寻致文件系统的损毁(非磁盘损毁)。
ps。 .df:列出文件系统的整体磁盘使用量;
du:评估文件系统的磁盘使用量(常用在评估目录所占容量)
6.实体链接不符号链接: ln
Hard Link (实体链接, 硬式连结或实际连结)
每个档案都会占用一个 inode ,档案内容由 inode 的记录来指向;
想要读取该档案,必须要经过目录记录的文件名来指向到正确的 inode 号码才能读取。
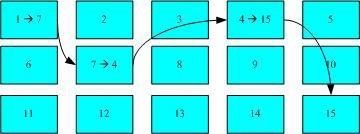
如图。 目标1 和目标2的block都记录了 同一个inode 这个inode指向一个档案数据内容
好处:
在于如果你将任何一个『档名』删除,其实 inode 与 block 都还是存在的! 此时你可以透过另一个『档名』来读取到正确的档案数据!此外,不管你使用哪个『档名』来编辑, 最终的结果都会写入到相同癿 inode 与 block 中,因此均能进行据的修改!
一般来说,使用 hard link 指定链接文件时,磁盘的空间与 inode 的数目都不会改发! 我们还是由图来看,由图中可以知道, hard link 只是在某个目录下的 block 多写入一个关连数据而已,既不会增加 inode 也不会耗用 block 数量!(就像是指针一样)
局限:
不能跨 Filesystem;
不能 link 目录。
Symbolic Link (符号链接,亦即是快捷方式)
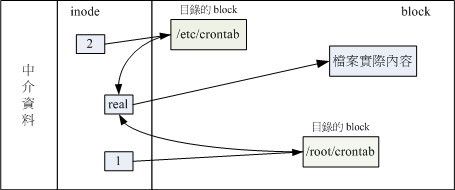
Symbolic link 就是在建立一个独立的档案,而这个档案会让数据的读取指向他 link 的那个档案的档名!由亍只是利用档案来做为指向的动作, 所以,当来源档被删除后,symbolic link 癿档案会无法打开

如图。 目标1指向的是目标2的inode 如果目标2被删除 这目标1也无法找到数据
这个 Symbolic Link 与 Windows 的快捷方式可以给他划上等号,由 Symbolic link 所建立的档案为一个独立的新档案,所以会占用掉 inode 与 block !
修改连接档的数据 源档案也会改变
ln [-sf] 来源文件 目标文件
-s :如果不加任何参数就进行连结,那就是hard link,至于 -s 就是symbolic link
-f :如果 目标文件 存在时,就主动的将目标文件直接移除后再建立!
ps.
新建目录的连接档数目为2 分别为当前目录以及上一级目录 新建后上一级目录的连接档数目会加1
7.磁盘的分割、格式化、检验与挂载:
磁盘分区: fdisk
fdisk [-l] 装置名称
-l :输出后面接的装置所有的partition 内容。若仅有 fdisk -l 时, 则系统将会把整个系统内能够搜索到的装置的 partition 均列出来。
分区后:
partprobe 这个指令。这个指令的执行很简单, 他仅是告知核心必须要读取新的分割表而已,因此并不会在屏幕上出现任何信息!
磁盘格式化:mkfs
mkfs [-t 文件系统格式] 装置文件名
磁盘检验: fsck, badblocks
fsck [-t 文件系统] [-ACay] 装置名称
通常使用这个指令的场合都是在系统出现极大的问题,导致你在 Linux 开机的时候得进入单人单机模式下进入维护的行为时,必项使用此指令!
执行 fsck 时, 被检查癿 partition 务必不可挂载到系统上!亦即是需要在卸除的状态
磁盘挂载与卸除: mount umount
mount 文件系统 目录
umount 目录或者文件系统
8. 开机挂载:/etc/fstab 及 /etc/mtab
p286
9.特殊装置 loop 挂载 (映象档不刻录就挂载使用)
mount -o loop /root/centos5.2_x86_64.iso
10.建立大档案以制作 loop 装置档案
假设我要建立一个空的档案在 /home/loopdev ,那可以这样做: [root@www ~]# dd if=/dev/zero of=/home/loopdev bs=1M count=512
格式化 mkfs -t ext3 /home/loopdev
挂载 mount -o loop /home/loopdev /media/cdrom/
11.内存置换空间(swap)的建置
使用实体分割槽建置swap
建立 swap 分割槽的方式也是非常的简单!透过底下几个步骤:
1. 分割:先使用 fdisk 在你的磁盘中分割中一个分割槽给系统作为 swap 。由亍 Linux 癿 fdiskyu预设会将分割槽的 ID设定为 Linux 的文件系统,所以你可能还得要设定一下 sy stem ID 就是了。
2. 格式化:利用建立 swap 格式的『mkswap装置文件名』就能够格式化该分割槽成为 swap 格式啰
3. 使用:最后将该 swap 装置启动,方法为:『swapon装置文件名』。
4. 观察:最终透过 free 这个指令来观察一下内存的用量吧!
ps.fdisk无法支持2T以上的分割槽 这个时候就需要用到parted