(Caffe)LSTM层分析
本文地址:http://blog.csdn.net/mounty_fsc/article/details/53114698
本文内容:
- 本文描述了Caffe中实现LSTM网络的思路以及LSTM网络层的接口使用方法。
- 本文描述了论文《Long-term recurrent convolutional networks for visual recognition and description》的算法实验
- 本文不做LSTM原理介绍,不从数学角度推导反向传播,不进行Caffe详细代码分析
- 本文基于对Caffe的代码及使用有一定的了解
涉及LSTM算法原理的部分可以参考其他文章见如 理解 LSTM 网络等。
1 简介及相关论文
LSTM为处理具有时间维度以及类似时间维度信息的RNN深度神经网络的一种改进模型,参考文献[1,2],在不少问题上能弥补CNN只能处理空间维度信息的缺陷。不同于CNN的深度体现在网络层数及参数规模上,RNN/LSTM的深度主要体现在时间节点上的深度。
Caffe中的LSTM相关代码由Jeff Donahue基于文献[1]的实验Merge而来。文献[3]中有三个关于使用LSTM的实验:(1)行为识别(介绍及代码) (2)图像描述(图像标注,介绍及代码) (3)视频描述。 三个实验难度依次递增。其中前两个实验代码开源。

本文主要从文献[3]第一个实验出发,介绍LSTM的接口的使用。
2 行为识别实验
实验使用UCF-101 数据集。行为识别实验目的为给定一视频片段,判断出视频片段人物的行为。
2.1 算法介绍
如1.1图所示,该实验的方法为:
- 首先提取视频的部分帧
- 其次根据标注的帧预训练一个图片分类网络(基于AlexNet)
- 训练LSTM模型
- 预训练的共享的CNN提取一段视频序列(时间上相关的帧)的CNN特征
- 以上特征输入至LSTM单元
- 对每个LSTM单元的输出取平均得到最后的检测结果
2.2 网络模型
Caffe训练网络的网络结果如下所示:
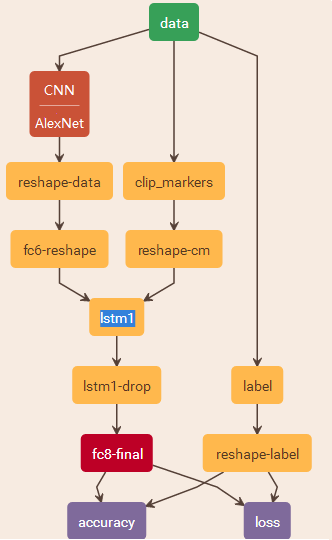
2.3相关术语及变量
N 为LSTM同时处理的独立流的个数,在该实验中为输入LSTM相互独立的视频的个数,以该实验测试网络为例,本文取 T=3 。
T 为LSTM网络层处理的时间步总数,在该实验中为输入LSTM的任意一独立视频的视频帧个数,以该实验测试网络为例,本文取 T=16 。
因此fc-reshape层输出维度为 T×N×4096 . 4096为AlexNet中全连接层的维度,即CNN特征的维度。
reshape-cm的输出维度为 T×N ,即每一个帧有一个是否连续帧的标志。
reshape-label的维度同样为 T×N
3 Caffe 相关类及接口
3.1 相关类
主要类说明见官方文档 RecurrentLayer、LSTMLayer、LSTMUnitLayer。

其中:
- RecurrentLayer为一个抽象类,定义了处理时间序列的循环神经网络的通用行为
- LSTMLayer及RNNLayer为RecurrentLayer的具体实现,后者为RNN的一般形式
- LSTMUnitLayer在LSTMLayer内部使用,处理了部分核心计算
3.2 接口说明
由官方文档可知,一个 RecurrentLayer/LSTMLayer 的输入为三个Blob:
- 一. 时间变化数据 x,(T×N×...) 。2.3处已介绍,此实验测试网络中该维度为 16×3×4096 。注意 T 在 N 前面。
- 二. 序列连续性标志 cont,(T×N) 。2.3处已介绍,此实验测试网络中该维度为 16×3 ,其中0表示该图片为视频帧的开始,1表示该图片为上一帧的延续。注意不能反过来用1表示为开始,在代码实现中,开始帧视频应当“遗忘”以往的信息,所以乘以0归零了之前的数据。
- 三. 时间不变的静态数据 xstatic,(N×...) (可选)。该项在行为识别中没有使用,而在第二个实验图片描述中有使用。如使用一张不随时间变化的图片作为第三个输入,该图片的输入维度为 N×4096 .
4 LSTMLayer
Caffe中通过展开LSTMLayer网络层,得到另一个网络从而实现LSTM,即一个LSTMLayer即为一个LSTM网络。以实验中测试网络为例,及 T=16,N=3 ,CNN特征维度为4096,LSTM特征维度为256,来介绍展开网络的各网络层及数据流动情况。
4.1 实现流程
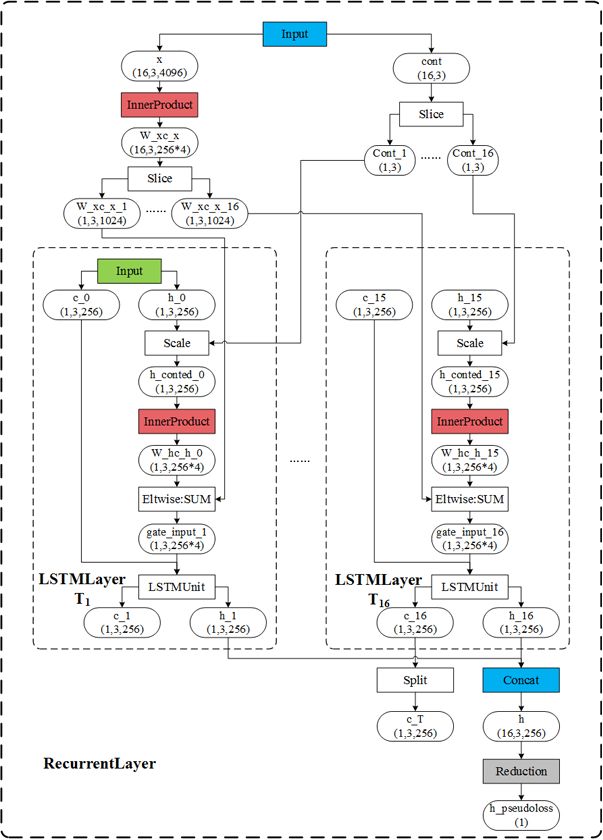
如图所示:
- 方框为网络层,文字为网络层类型。
- 椭圆为数据Blob。
- Blob ci 为细胞状态; Blob hi 为隐藏状态
- 蓝色为输入数据或产生输出数据的网络层。
- 红色为权重网络层。
- 整体外框为基类RecurrentLayer实现的功能,子框为LSTMLayer实现的功能。
- 输出为Blob h(1,3,256)。
- 最后的Reduction层生产的伪损失,该网络层不起功能作用,存在的意义只是使这个网络变得完成,而“强制”反向传播。
- 多个时间步( T1,…,T16 )间的InnerProduct是共享参数的,及保证了各个时间步的权重能处理同一时间序列。因而整个网络(LSTM网络)只有三个权重Blob:图中第一个红色框中的InnerProduct层的权重 Wxc 及 偏置 bc ,后边所有红色权重层的权重 Whc (共享的,且无偏置)
- Scale层为根据cont提供的序列连续性情况,来决定是否保持(乘1)与放弃(乘0)之前的隐藏状态 ht−1
4.2 公式描述
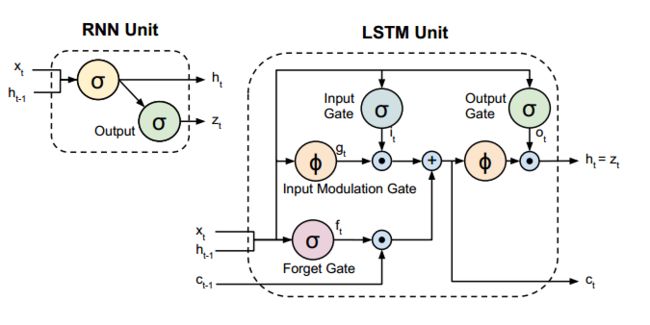
计算公式如下:
注意:
- 联系前两张图与以上公式,可以描述Caffe的LSTM实现过程
- 以上公式的 [Wxi,Wxf,Wxo,Wxg] 为由第一个InnnerProduct层保存,及4.1中的 Wxc
- 以上公式的 [bi,bf,bo,bg] 为由第一个InnnerProduct层保存,及4.1中的 bc
- 以上公式的 [Whi,Whf,Who,Whg] 为由后边的InnnerProduct层保存,及4.1中的 Whc
5 总结
一个RNN/LSTM网络层可以通过从时间维度上进行展开来进行理解( 理解 LSTM 网络)。同样的,Caffe在实现LSTM时也是通过展开LSTM层来实现,等价于一个LSTM 网络层 即为一个LSTM 网络。
6 图像描述实验
实验使用coco caption数据集。给定一张图片,其目标为产生一段语句对该图片进行描述。
6.1 语言模型小实验
这部分实验属于图像描述的基础实验。图像描述在该实验基础上拓展而来,且相对图像描述来说更为简单,因而先介绍该小实验。
语言模型实验为训练一个语言模型,使其能够完成:
(1)给定一个词,如some,该模型能产生下人类语言中能搭配该词的下一个次,如some people, some apple。
(2)在(1)的基础上,该模型能产生一个完整的语句。
链接处为作者给出的该模型的实例与教程。
6.1.1 训练
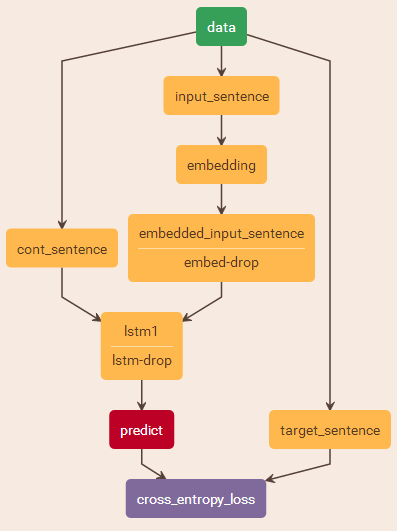
该模型的训练过程与行为检测的训练过程类似。如图所示,LSTM层的输入为两个Blob:
(1)训练数据Blob,维度为 T×N×1000 ,其中1000为每个词的特征,即语言模型的训练数据中,一个词对应于行为识别中的一张图片(行为识别的训练数据维度为 T×N×4096 )。
注意,此处说的维度为embedded_input_sentence的维度。而输入数据的input_sentence的维度为 T×N×8801 , 8801 为词典(词库)的规模 N ,即输入数据为该词在该词典中的独热向量(one-hot vector) y˜,y˜∈R8801 。该独热向量通过权重层Embed层产生一个 1000 维的特征向量 y,y∈R1000 。该Embed层等价于实现 y=Wey˜,We∈R1000×8801 。由于 y˜ 为独热向量,所以也可以理解为 We 为一个查找表,每一列为一个词的特征向量。
(2)连续性标志Blob。与行为识别类似,维度为 T×N
6.1.2 推理
该模型的产生一个完整句子的过程推理如下图所示。
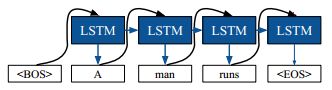
说明:
1. 生成一个完整的句子需要反复多次调用该语言模型,即前一次的结果作为下一次的输入,直至最后的输出为语句终止符EOS
2. 推理时的输入LSTM维度为 1×N×1000 ,如果是只产生单个语句,则为 1×1×1000
6.2 使用静态输入 xstatic
不同于行为识别实验以及语言模型小实验,图像描述实验的LSTM层使用了第三个输入参数,静态输入 xstatic 。有 xstatic LSTM层的训练模型如下图所示:
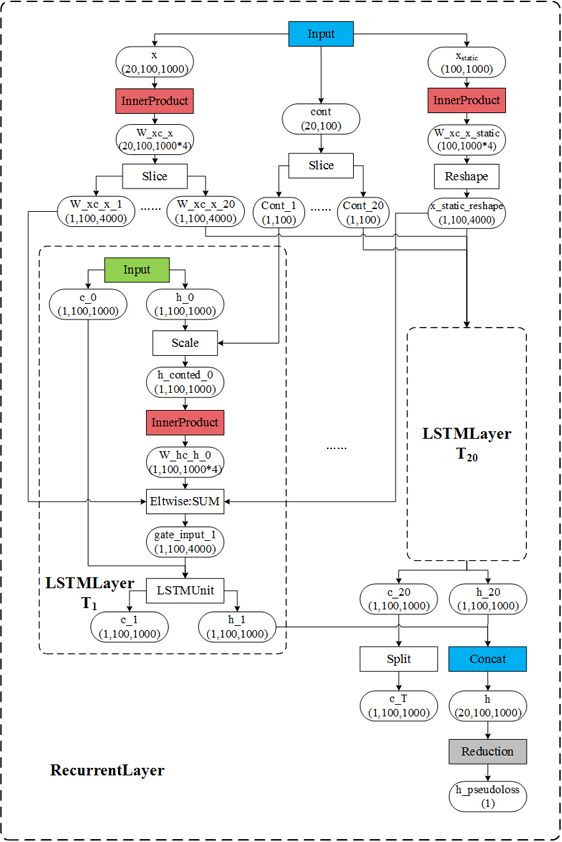
注意:
- 第一个输入Blob同语言模型,维度为 (20,100,1000) ,即 N=100 条语句(对应100张图片),时间步 T=20 ,每个词的特征维度为 1000 。
- 第二个输入Blob同语言模型,维度为 (20,100)
- 第三个输入Blob为图片CNN特征,维度为 (100,1000) ,即 N=100 张图片,每张图片特征为1000维度。注意图片的特征维度尽量与词的特征维度相同,若不同,Caffe会通过填充或截断的方式进行维度长度匹配。
- Caffe中的官方文档说对 x 以及 xstatic 的处理方式,及通过连接每个时间步 xt 与 xstatic 得到新的特征 x′t=[xt;xstatic] 。而由上图可知,实现上Caffe不是使用Concat层连接二者而是使用Eltwise求和二者,及 x′t=[xt+xstatic]
6.3 图像描述实验
图像描述实验是在语言描述实验的基础上,增加图像的CNN特征作为LSTM的静态输入特征。
文献[1]提出三个组合方式,如下图所示:
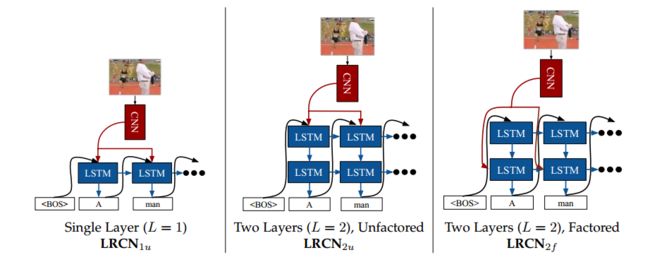
1)第一种为一层LSTM,为最朴素的方法。
2)第二种为两层LSTM,静态输入在第一个LSTM层。
3)第三种为两层LSTM,静态输入在第二个LSTM层。最后取的是该种方法。
参考文献
[1] Hochreiter, Sepp, and Schmidhuber, Jürgen. “Long short-term memory.” Neural Computation 9, no. 8 (1997): 1735-1780.
[2] Zaremba, Wojciech, and Sutskever, Ilya. “Learning to execute.” arXiv preprint arXiv:1410.4615 (2014).
[3] Donahue, J., et al. “Long-term recurrent convolutional networks for visual recognition and description.” Computer Vision and Pattern Recognition IEEE, 2015.