理论基础
一、大数据领域的行式存储与列式存储
1、行式存储:
hdfs上一个block存储一或多行数据。
按行压缩,压缩性能受字段类型影响。
字段查询:select id,name from table_emp;
#####全表扫描,字段拼接,效率低。
全表查询:select * from table_emp;
#####直接展现数据,效率高。
2、列式存储:
hdfs上一个block一列或多列数据。
按列压缩,每一列相同数据类型,压缩性能好。
字段查询:select id,name from table_emp;
#####扫描部分字段,直接展现,效率高。
全表查询:select * from table_emp;
#####将分散的行重组, 效率低。
3、策略:
大数据领域的全表查询的场景少之又少,使用较多的还是列式存储。
1、存储格式的三种设置方式
hive建表时,可以使用“stored as file_format”来指定该表数据的存储格式,默认存储格式为TextFile,可通过hive.default.fileformat进行更改。
第一种方式:
create table t1
(
id int,
name string
)
row format delimited
fields terminated by "\t"
stored as textfile;
第二种方式:
create table t2 (
id int,
name string
)
row format delimited
fields terminated by "\t"
stored as
inputformat 'org.apache.hadoop.mapred.TextInputFormat'
outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
#####可以用这种方式执行自定义的存储格式。
第三种方式:
set hive.default.fileformat=textfile; #####该属性默认值就是textfile
create table t1
(
id int,
name string
)
row format delimited
fields terminated by "\t";
######以上三种方式存储的格式都是textfile。
2、存储格式讲解
A)textfile
textfile:
行式存储,默认的存储格式,将所有类型的数据都存储为String类型。
不便于数据的解析,也不具备随机读写的能力,但它却比较通用。
==============================================
测试:
建表:
create table t_text
(
record_time String,
imei String,
cell String,
ph_num int,
call_num int,
drop_num int,
duration int,
drop_rate int,
net_type String,
erl int
)
row format delimited
fields terminated by ','
stored as textfile;
导入数据:
hive> load data local inpath '/root/user.tmp/phone.csv' into table t_text;
统计大小:
hive> dfs -du -h -s /user/hive_remote/warehouse/t_text;
54.7 M /user/hive_remote/warehouse/t_text
相同查询读取的hdfs数据量大小:
hive> select count(1) from t_text where imei='359681';
HDFS Read: 57410034 ####约为54.7MB
===========================================================================
hive> desc formatted t_text;
OK
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
B)sequencefile
sequencefile:
行式存储。
每条record包含record legth、key length、key、value等四部分。
多了冗余信息,所以存储相同的数据,sequencefile比textfile略大。
但正是因为这些冗余信息,使其具备随机读写的能力。
该存储格式压缩时压缩只有value。
=========================================================================
测试:
建表:
create table t_seq
(
record_time String,
imei String,
cell String,
ph_num int,
call_num int,
drop_num int,
duration int,
drop_rate int,
net_type String,
erl int
)
row format delimited
fields terminated by ','
stored as sequencefile;
导入数据:
hive> insert into table t_seq select * from t_text;
统计大小:
hive> dfs -du -h -s /user/hive_remote/warehouse/t_seq;
65.6 M /user/hive_remote/warehouse/t_seq
相同查询读取的hdfs数据量大小:
hive> select count(1) from t_seq where imei='359681';
HDFS Read: 68785223 #####约为65.6MB
=====================================================================
hive> desc formatted t_seq;
OK
InputFormat: org.apache.hadoop.mapred.SequenceFileInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat

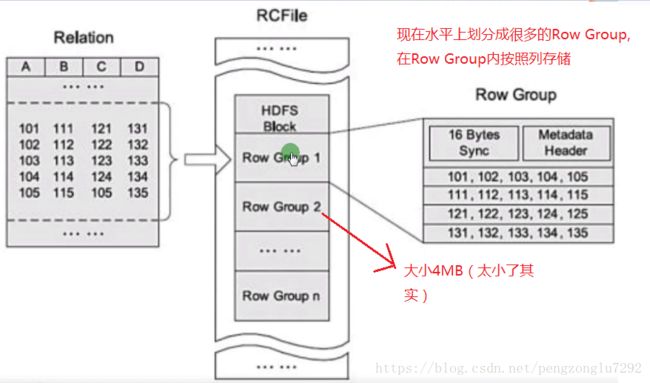
C)rcfile(Record Columnar File)
rcfile:
facebook开源,比标准行式存储节约10%的空间。
先水平划分按行存储的row group,row group中再按列存储数据。
尽管支持支持随机读写,但依然由于存储性能问题没啥大用处。
===================================================================================
测试:
建表:
hive>create table t_rc row format delimited fields terminated by ','
>stored as rcfile
>as select * from t_text;
统计大小:
hive> dfs -du -h -s /user/hive_remote/warehouse/t_rc;
44.0 M /user/hive_remote/warehouse/t_rc
相同查询读取的hdfs数据量大小:
hive> select count(1) from t_seq where imei='359681';
HDFS Read: 6622900 #####约为6.3MB
====================================================================================
hive> desc formatted t_rc;
OK
InputFormat: org.apache.hadoop.hive.ql.io.RCFileInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.RCFileOutputFormat
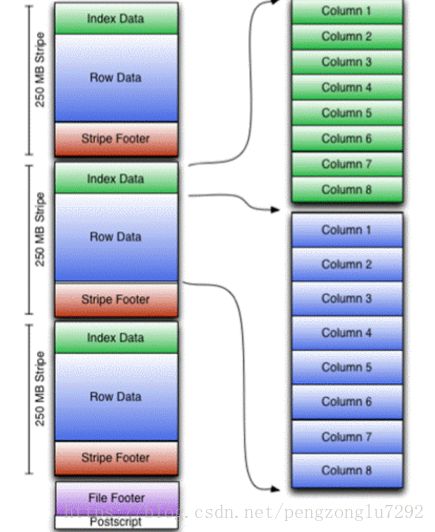
ORC:
orc:
优化过后的RCFile。可作用于表或者表的分区。
先在水平上划分为多个按行存储的Stripe(250MB)。Row Data中再按列存储数据。
Index Data记录的是整型数据最大值最小值、字符串数据前后缀信息,每个列的位置等等。
这就使得查询十分得高效,默认每一万行数据建立一个Index Data。
ORC存储大小为TEXTFILE的40%左右,使用压缩则可以进一步将这个数字降到10%~20%。
orc默认使用zlip的压缩格式,可以支持zlip和snappy压缩格式。
=====================================================================================
不配压缩测试:
建表:
hive> create table t_orc row format delimited fields terminated by ','
>stored as orc tblproperties("orc.compress"="none")
>as select * from t_text;
统计大小:
hive> dfs -du -h -s /user/hive_remote/warehouse/t_orc;
4.3 M /user/hive_remote/warehouse/t_orc
#####难以置信
相同查询读取的hdfs数据量大小:
hive> select count(1) from t_orc where imei='359681';
HDFS Read: 2050278 ####约为2.0MB
====================================================================================
配压缩测试:
建表:
hive>create table t_orc_zlip row format delimited fields terminated by ','
>stored as orcfile
>as select * from t_text;
####默认自带zlip压缩
统计大小:
hive> dfs -du -h -s /user/hive_remote/warehouse/t_orc_zlip;
3.4 M /user/hive_remote/warehouse/t_orc_zlip
相同查询读取的hdfs数据量大小:
hive> select count(1) from t_orc_zlip where imei='359681';
HDFS Read: 1809697 #####约为1.7MB
===============================================================================
查看hadoop支持的压缩格式:
cd /opt/apps/hadoop-2.6.5/bin && hadoop checknative
设置压缩的两种形式:
hive>set orc.compression=zlip;
建表时properties("orc.compress"="zlip")
PARQUET
parquet:
存储大小为TEXTFILE的60%~70%,压缩后在20%~30%之间。
===========================================================================
不配压缩测试:
建表:
hive> create table t_par row format delimited fields terminated by ','
>stored as parquet
>as select * from t_text;
统计大小:
hive> dfs -du -h -s /user/hive_remote/warehouse/t_par;
4.4 M /user/hive_remote/warehouse/t_par
相同查询读取的hdfs数据量大小:
hive> select count(1) from t_par where imei='359681';
HDFS Read: 1825494 #####约为1.7MB
===============================================================================
配压缩测试:
建表:
hive> create table t_par_zlip row format delimited fields terminated by ','
>stored as parquet tblproperties("orc.compress"="zlip")
>as select * from t_text;
统计大小:
hive> dfs -du -h -s /user/hive_remote/warehouse/t_par_zlip;
3.4 M /user/hive_remote/warehouse/t_par_gzip
相同查询读取的hdfs数据量大小:
hive> select count(1) from t_par_zlip where imei='359681';
HDFS Read: 1708876 #####约为1.6MB
============================================================================
总结
统计大小:
54.7 M /user/hive_remote/warehouse/t_text
65.6 M /user/hive_remote/warehouse/t_seq
44.0 M /user/hive_remote/warehouse/t_rc
4.3 M /user/hive_remote/warehouse/t_orc
4.4 M /user/hive_remote/warehouse/t_par
3.4 M /user/hive_remote/warehouse/t_orc_zlip
3.4 M /user/hive_remote/warehouse/t_par_gzip
相同查询读取的hdfs数据量大小:
HDFS Read: 57410034 ####约为54.7MB t_text
HDFS Read: 68785223 #####约为65.6MB t_seq
HDFS Read: 6622900 #####约为6.3MB t_rc
HDFS Read: 2050278 ####约为2.0MB t_orc
HDFS Read: 1825494 #####约为1.7MB t_par
HDFS Read: 1809697 #####约为1.7MB t_orc_zlip
HDFS Read: 1708876 #####约为1.6MB t_par_gzip
存储格式不仅对于存储空间存在很大的影响,对于相同SQL语句的查询性能上也有着巨大的影响。
在生产上,我们优先采用表的是parquet和orc的存储格式,再试集群压力决定是否配置压缩。
######
在本测试中,orc和parquet未采用压缩存储空间上有这十分巨大的减小,这和本人使用的数据有关。
但不可置疑的是,最好用的两种存储格式依然是orc和parquet,当然,orc是要优于parquet的。