Spark的Parquet向量化读取原理
起因:
测试过程中,发现一个spark的一个参数设置可以带来5倍以上的性能差异
参数:
spark.sql.parquet.enableVectorizedReader
SQL:
SELECT * FROM ad_tetris_dw.ad_insight_record_hourly_test WHERE page_url = "www.chengzijianzhan.com/tetris/page/52202031760/" and date = '20180805' and hour = '08'
运行结果:
![]()
参数设置为true运行时间22s,设置为false运行时间5.4min,于是好奇什么样的差异能带来如此大的性能提升,结果就接触到一个新的名词——向量化计算
向量化的搜索结果

搜索引擎搜索“向量化”结果经总结大致分为三类:
1,向量化运算
能够充分利用CPU性能的编程语言/库/API
2,词向量化
在深度学习领域使用的针对于文本的数据结构,将文本抽象成向量后可以使用各种针对于向量的数学理论和高性能向量化计算实践(即1)。
3,SQL引擎向量化
在SQL计算引擎中使用的和Code Generation相结合的技术
2,3依赖于1,2不是我的关注点,本文介绍向量化运算和SQL引擎向量化的主要思想和少量细节。
向量化运算:
解释不清楚但需要知道的前提:CPU层面存在复杂的指令优化,这些优化比高级语言层次的优化强大的多。其中做向量化计算的叫SIMD。
向量化运算是与四则运算,函数运算相对应的概念
1,一般运算:对一个变量进行一个四则运算或函数运算将结果存储于原来位置
2,向量化运算:对一组变量(一个向量)进行运算将结果存储于原来位置
举例:对于一个数组arr = [1,2,3,4,5,6,7,8,9,10]执行+1操作,一般运算需要使用循环逐个处理,而支持向量化运算的语言可以使用arr+1。到达CPU指令集层面,一般运算需要调用10次指令集,控制寄存器执行“+”操作,而向量化运算,可能只需要一次将arr加载到CPU cache,然后使用多个寄存器并行执行“+”操作。显然,这是一个时间和空间都节约的方式(向量化计算带来变量减少,代码简洁,减少调用栈)。
因此对于性能有需求的语言和类库都会对指令进行优化,比如java语言会将简单的for循环展开为向量化指令SIMD。而python的高性能计算库numpy底层是C实现的,较比python原生有数十上百倍的速度提升。
例子:

向量化运算既省时间,又省空间,因此成为板蓝根,常备。
SQL引擎向量化
查询执行引擎 (query execution engine) 是数据库中的一个核心组件,用于将查询计划转换为物理计划,并对其求值返回结果。查询执行引擎对数据库系统性能影响很大,目前主要的执行引擎有如下四类:Volcano-style,Block-oriented processing,Column-at-a-time,Vectored iterator model。下面分别介绍这四种执行引擎。详细介绍见http://www.infoq.com/cn/articles/an-article-mastering-sql-on-hadoop-core-technology 本文只解释最基本的火山模型和向量化模型,另两个模型都是在演化过程中的中间产物。
火山式模型
任何SQL引擎都要将SQL转化为执行计划,执行计划是一个由算子组成的tree或者DAG。其中每一个 operator 包含三个函数:open,next,close。Open 用于申请资源,比如分配内存,打开文件,close 用于释放资源,next 方法递归的调用子 operator 的 next 方法生成一个元组。下图描述了 select id,name,age from people where age >30 的火山模型的查询计划,该查询计划包含 User,Project,Select,Scan 四个 operator,每个 operator 的 next 方法递归调用子节点的 next,一直递归调用到叶子节点 Scan operato,Scan Operator 的 next 从文件中返回一个元组。
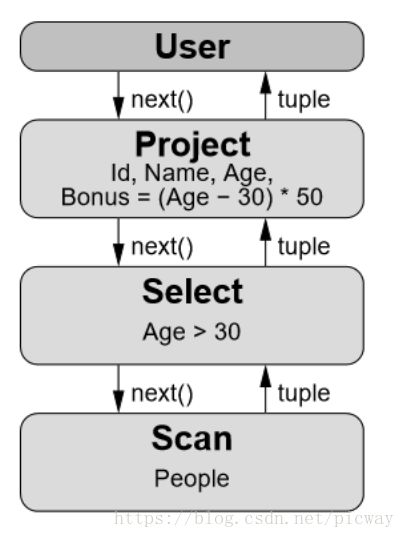
向量化模型
火山模型清晰合理,然而存在很大性能浪费,每处理一个元组(tuple)最少需要调用一次next(),next()函数是由编译器调用虚函数实现的。虚函数调用是非常消耗性能的,何况对于OLAP要调用数亿万次。因此优化目标明确——减少虚函数调用次数。这就回到了上面说到的向量化运算。如果将逐个的元组操作转化为向量化操作,每次读取next操作读取多条数据,就可以节约大量CPU时间。例如以下是Spark的向量化读取代码:
/**
* Advances to the next batch of rows. Returns false if there are no more.
*/
public boolean nextBatch() throws IOException {
columnarBatch.reset();
if (rowsReturned >= totalRowCount) return false;
checkEndOfRowGroup();
int num = (int) Math.min((long) columnarBatch.capacity(), totalCountLoadedSoFar - rowsReturned);
for (int i = 0; i < columnReaders.length; ++i) {
if (columnReaders[i] == null) continue;
columnReaders[i].readBatch(num, columnarBatch.column(i));
}
rowsReturned += num;
columnarBatch.setNumRows(num);
numBatched = num;
batchIdx = 0;
return true;
}顾名知意,是分 batch拉去数据的。
这就是SQL引擎的向量化,但这还远远不够,完整的向量化模型是结合列式存储,向量化计算,代码生成的综合优化方案。
列式存储:
列式存储在OLAP应用中意义不必多说,减少数据读取量,按列压缩获取更高的压缩率和IO效率等等。在向量化计算层面也有意义,上面说到每次next()都读取多条数据,如果是行式存储,则意味着一次性读入多行,然而实际计算中,对于不同的字段计算过程当然是不同的,因此同时存在于CPU Cache的数据不能用同样的操作处理,但如果是列式存储,读入cache的数据就可以一并操作,这就提高了CPU Cache的命中率,性能显然会得到提升。
Code Generation:
一个事实是:如想实现select id,name,age from people where age >30的结果,一个大学生也可以手写代码搞出比上面的算子实现性能高得多的程序,如下图:

这是因为:
1、没有虚函数调用:手写版本的代码没有虚函数调用。上面已经说过了虚函数调用是性能浪费的罪魁祸首
2、内存和CPU寄存器中的临时数据:在Volcano模型中,每次一个算子给另外一个算子传递元组的时候,都需要将这个元组存放在内存中;而在手写版本的代码中,编译器实际上将临时数据存放在CPU寄存器中。访问内存中的数据所需要的CPU时间比直接访问在寄存器中的数据要大一个数量级!
3、循环展开(Loop unrolling)和SIMD:当运行简单的循环时,现代编译器和CPU是令人难以置信的高效。编译器会自动展开简单的循环,甚至在每个CPU指令中产生SIMD指令来处理多个元组。CPU的特性,比如管道(pipelining)、预取(prefetching)以及指令重排序(instruction reordering)使得运行简单的循环非常地高效。然而这些编译器和CPU对复杂函数调用图的优化极少,而这些函数正是Volcano模型依赖的。
因此,一个自然的想法就是要把SQL解析完的执行计划转化成手写代码的样子,就可以避免诸多不必要计算了。这个功能就是自动代码生成,Spark中叫whole stage code generation(WSCG),这样可以避免上述的问题1和问题3。
关于whole-stage code generation技术的JIRA可以到SPARK-12795里查看;而关于vectorization技术的JIRA可以到SPARK-12992查看。
代码简析:
ParquetRecordReader和VectorizedParquetRecordReader
列式数据存储的读取的基类是RecordReader,RecordReader是Hadoop提供的抽象类,定义如下:
package org.apache.hadoop.mapreduce;
import java.io.Closeable;
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience.Public;
import org.apache.hadoop.classification.InterfaceStability.Stable;
@Public
@Stable
public abstract class RecordReader implements Closeable {
public RecordReader() {
}
public abstract void initialize(InputSplit var1, TaskAttemptContext var2) throws IOException, InterruptedException;
public abstract boolean nextKeyValue() throws IOException, InterruptedException;
public abstract KEYIN getCurrentKey() throws IOException, InterruptedException;
public abstract VALUEIN getCurrentValue() throws IOException, InterruptedException;
public abstract float getProgress() throws IOException, InterruptedException;
public abstract void close() throws IOException;
} 从方法看:initialize,nextKeyValue,close,基本能够和上文火山模型的open,next,close对应。
Hadoop原生使用的是Parquet项目提供的ParquetRecordReader,ParquetRecordReader没有实现向量化。Parquet向量化读写本应是Parquet本身应该支持的功能,但从社区JIRA上来看(如PARQUET-131 https://issues.apache.org/jira/browse/PARQUET-131)貌似出于搁置状态,各种SQL引擎都自行实现了向量化。
Spark的Parquet向量化读取实现是:VectorizedParquetRecordReader,继承SpecificParquetRecordReaderBase,SpecificParquetRecordReaderBase继承RecordReader,在VectorizedParquetRecordReader中增加了initBatch,nextBatch,resultBatch的Batch方法。

ParquetFileFormat
VectorizedParquetRecordReader的调用是在ParquetFileFormat的buildReaderWithPartitionValues方法,方法中有一个if判断,判断逻辑如下:
if (enableVectorizedReader) {
val vectorizedReader = new VectorizedParquetRecordReader(
convertTz.orNull, enableOffHeapColumnVector && taskContext.isDefined)
......
} else {
logDebug(s"Falling back to parquet-mr")
// ParquetRecordReader returns UnsafeRow
val reader = if (pushed.isDefined && enableRecordFilter) {
val parquetFilter = FilterCompat.get(pushed.get, null)
new ParquetRecordReader[UnsafeRow](new ParquetReadSupport(convertTz), parquetFilter)
} else {
new ParquetRecordReader[UnsafeRow](new ParquetReadSupport(convertTz))
}
......
}根据enableVectorizedReader的真假选择Reader的实现,为真使用VectorizedParquetRecordReader,为假使用ParquetRecordReader。其中enableVectorizedReader是通过conf配置的,即我们最开始提到的参数:spark.sql.parquet.enableVectorizedReader
val enableVectorizedReader: Boolean =
sqlConf.parquetVectorizedReaderEnabled &&
resultSchema.forall(_.dataType.isInstanceOf[AtomicType])总结
以上就是关于向量化计算的一点学习成果。总结来说:向量化计算就是充分利用CPU计算能力(提高计算并行度,提高Cache命中率)的编程实践;SQL引擎的向量化模型是结合列式存储,代码生成和向量化编解码的综合优化方案,参考的博客很好,有时间要读。
参考
http://www.infoq.com/cn/articles/an-article-mastering-sql-on-hadoop-core-technology
https://www.iteblog.com/archives/1679.html
http://www.infoq.com/cn/articles/columnar-databases-and-vectorization
https://www.zhihu.com/question/67652386
https://en.wikipedia.org/wiki/Vectorization
https://www.jianshu.com/p/ad8933dd6407
https://animeshtrivedi.github.io/spark-parquet-reading