Sigmod/Softmax变换
http://blog.csdn.net/pipisorry/article/details/7781662
Logistic/Softmax变换
sigmoid函数/Logistic 函数
取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。
sigmoid 的导数表达式为:
sigmoid 原函数及导数图形如下:
Note: 从导数表达式可知,logit梯度最大为0.25。
logistic函数用于数据归一化
新数据=1/(1+e^(-原数据))
P(i)=11+exp(−θTix)
这个函数的作用就是使得P(i)在负无穷到0的区间趋向于0,在0到正无穷的区间趋向于1。同样,函数(包括下面的softmax)加入了e的幂函数正是为了两极化:正样本的结果将趋近于1,而负样本的结果趋近于0。这样为多类别分类提供了方便(可以把P(i)看作是样本属于类别i的概率)。
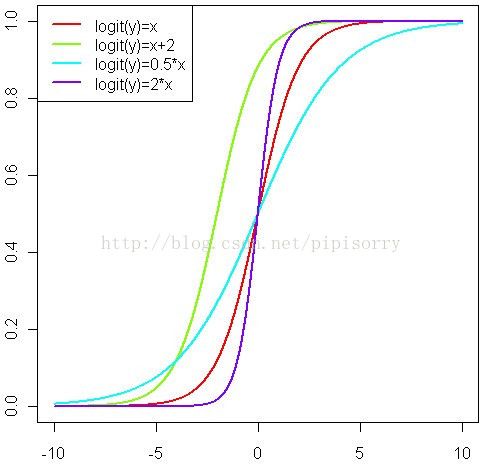
logit(P) = log(P / (1-P)) = a + b*x 以及 probit(P) = a + b*x
这两个连接函数的性质使得P的取值被放大到整个实数轴上。
事实上可以把上面的公式改写一下:
P = exp(a + b*x) / (1 + exp(a + b*x)) 或者 P = pnorm(a + b*x)(这个是标准正态分布的分布函数)
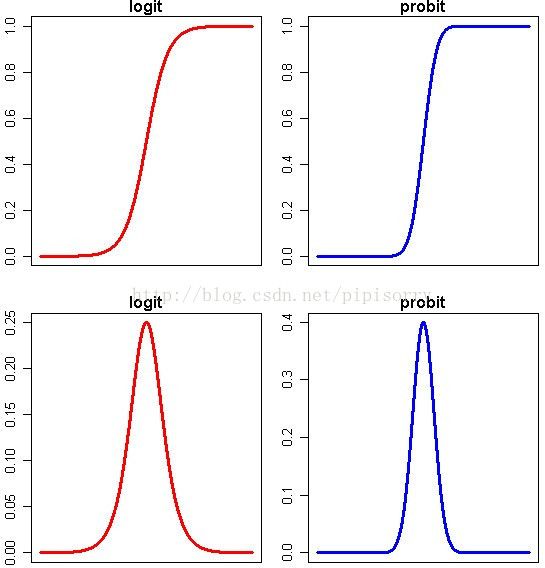
Note: 上半部分图形显示了概率P随着自变量变化而变化的情况,下半部分图形显示了这种变化的速度的变化。可以看得出来,概率P与自变量仍然存在或多或少的线性关系,主要是在头尾两端被连接函数扭曲了,从而实现了[0,1]限制。同时,自变量取值靠近中间的时候,概率P变化比较快,自变量取值靠近两端的时候,概率P基本不再变化。这就跟我们的直观理解相符合了,似乎是某种边际效用递减的特点。
[logistic回归的一些直观理解(1.连接函数 logit probit)]
神经网络中的激活函数:sigmoid函数/Logistic 函数-软饱和和硬饱和
[神经网络中的激活函数 ]
逻辑回归中的sigmod函数
[Machine Learning - VI. Logistic Regression逻辑回归 (Week 3) ]
数据的标准化(normalization)和归一化中的应用
[数据标准化/归一化normalization ]
某小皮
Softmax函数
Softmax函数是logistic函数的一种泛化。Softmax - 用于多分类神经网络输出。二类分类当然也可以用,但是如果只输出一个神经元可以使用sigmod函数。
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的Softmax值就是
也就是说,是该元素的指数,与所有元素指数和的比值。
举个例子来看公式的意思:
就是如果某一个 zj 大过其他 z, 那这个映射的分量就逼近于 1,其他就逼近于 0,主要应用就是多分类。
为什么要取指数?
第一个原因是要模拟 max 的行为,所以要让大的更大;第二个原因是需要一个可导的函数。
被称为 softmax 函数,因为它表示“ max ”函数的一个平滑版本。这是因为,如果对于所有的 j != k 都有 a_k ≫ a_j ,那么 p(C k | x) ≃ 1 且 p(C j | x) ≃ 0 。
通过softmax函数,可以使得P(i)的范围在[0,1]之间。在回归和分类问题中,通常θ是待求参数,通过寻找使得P(i)最大的θi作为最佳参数。
此外Softmax函数同样可用于非线性估计,此时参数θ可根据现实意义使用其他列向量替代。
Softmax函数得到的是一个[0,1]之间的值,且∑Kk=1P(i)=1,这个softmax求出的概率就是真正的概率,换句话说,这个概率等于期望。
Sigmoid 和 Softmax 区别
sigmoid将一个real value映射到(0,1)的区间,用来做二分类。
而 softmax 把一个 k 维的real value向量(a1,a2,a3,a4….)映射成一个(b1,b2,b3,b4….)其中 bi 是一个 0~1 的常数,输出神经元之和为 1.0,所以相当于概率值,然后可以根据 bi 的概率大小来进行多分类的任务。
二分类问题时 sigmoid 和 softmax 是一样的,求的都是 cross entropy loss,而 softmax 可以用于多分类问题
softmax建模使用的分布是多项式分布,而logistic则基于伯努利分布
多个logistic回归通过叠加也同样可以实现多分类的效果,但是 softmax回归进行的多分类,类与类之间是互斥的,即一个输入只能被归为一类;多个logistic回归进行多分类,输出的类别并不是互斥的,即"苹果"这个词语既属于"水果"类也属于"3C"类别。
[Softmax 函数及其作用(含推导)]
[常用激活函数比较]
softmax代码实现
最新版的scipy中有这个函数及其示例
[scipy.special.softmax¶]
当然tensorflow中也有这个函数,只是输入输出是tensor。
from: http://blog.csdn.net/pipisorry/article/details/77816624
ref: