hadoop基础----hadoop实战(二)-----hadoop操作hdfs---hdfs文件系统常用命令
我们在前面已经介绍过了 hadoop 1.0是由2大部分组成的:
hdfs + mapreduce
也对hdfs做了相关介绍。
hadoop基础----hadoop理论(三)-----hadoop分布式文件系统HDFS详解
因为上一章我们已经安装好了hadoop1.0的环境
hadoop基础----hadoop实战(一)-----hadoop环境安装---手动安装官方1.0版本
本章就来尝试实际操作 hdfs的命令。
如果熟悉linux的命令的话 你会发现hdfs会有很多相似的命令。
hdfs模拟了很多linux命令,用法也很类似:
hadoop fs +类似linux命令
更多命令详细可参考官网。
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html
这里尝试常用的一些命令:
HDFS命令格式
hadoop fs -cmd args
cmd:具体的操作,基本上与UNIX的命令行相同
args:参数
HDFS资源URI格式
格式
也就是命令格式中的args参数,我们有时候需要填写路径path。这里讲解一下hdfs中path的格式。
比如:
hadoop fs -cat hdfs://host1:port1/file1 hdfs://host2:port2/file2
hadoop fs -cat file:///file3 /user/hadoop/file4
这里hdfs://hadoop0:port1/file1就是路径path。
hdfs中没有当前工作目录这样一个概念,也没有cmd这样的命令。所以一般需要用绝对路径。格式如下:
scheme://authority/path
scheme:协议名(file或hdfs)
authority:namenode主机名(hadoop0:9000或者192.168.30.180:9000)
path:路径
示例
hdfs://192.168.30.180:9000/user/joe/test.txt
假设已经在core-site.xml里配置了 fs.default.name=hdfs://192.168.30.180:9000,则仅使用/user/joe/test.txt即可。
我们回头看看安装篇中的设置,我们是有设置的。如图:
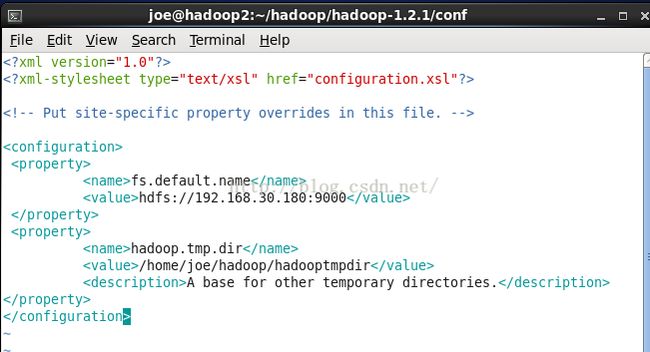
hdfs默认工作目录为 /user/$USER,$USER是当前的登录用户名。只有将文件放入HDFS上(也就是工作目录)后,才可以运行Hadoop程序来处理它。
常用命令
进入bin目录
现在我们来实际操作常用命令。未配置全局路径时必须进入hadoop安装路径的bin目录下才能运行常用hdfs命令。
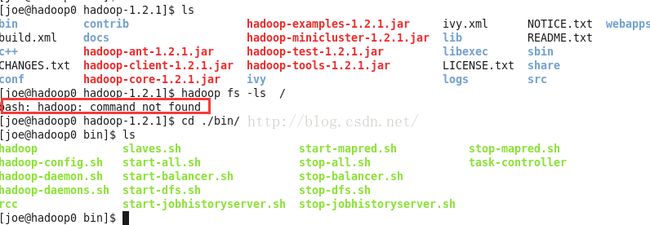
否则会报 command not found.
cd /home/joe/hadoop/hadoop-1.2.1/bin/查看hdfs支持的所有命令fs
hadoop fs如图所示:

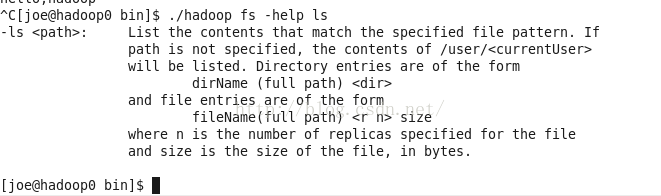
查看某个命令的帮助文档fs -help
./hadoop fs -help ls查看命令ls的帮助文档。
列出目录和文件fs -ls
列出hadoop工作目录下的内容--目录和文件-包括文件名,权限,所有者,大小和修改时间。
./hadoop fs -ls /
ps:hadoop工作目录的内容是集群一致的,也就是说在集群中的任意机子中hadoop0或者hadoop1或者hadoop2中运行,显示的内容都是一样的。
./hadoop dfs -ls /
PS: hadoop dfs -ls 作用跟hadoop fs -ls 作用类似,也是列出工作目录下的内容。区别可见下一节。
fs与dfs的区别
fs涉及到一个通用的文件系统,可以指向任何的文件系统如local,HDFS等。但是dfs仅是针对HDFS的。
那么什么时候用FS呢?可以在本地与hadoop分布式文件系统的交互操作中使用。特定的DFS指令与HDFS有关。
这两个命令依赖于模式的配置。当使用绝对URI(如scheme://a/b)这两个命令的效果是相同的。
只有默认的模式配置参数对dfs和fs起作用。
hadoop fs:使用面最广,可以操作任何文件系统。
hadoop dfs与hdfs dfs:只能操作HDFS文件系统相关(包括与Local FS间的操作),前者已经Deprecated,一般使用后者。hdfs dfs是hadoop2.0版本中的命令。我们现在的1.0版本是没有该命令的。反正用法是类似的。
详细分析可参考:http://blog.csdn.net/pipisorry/article/details/51340838
循环列出目录、子目录及文件信息 fs -lsr
./hadoop fs -lsr /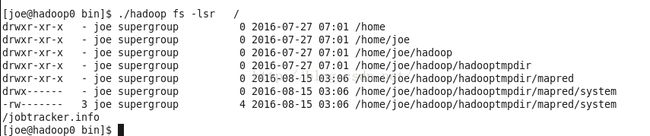
建立目录fs -mkdir
./hadoop fs -mkdir /joe/examples![]()
查看一下是否创建成功,我们在hadoop0创建目录,在hadoop1中查看。证明了hadoop的工作目录是集群式的,不是本机的。也就是 在hadoop0创建和hadoop1中创建效果是一样的。
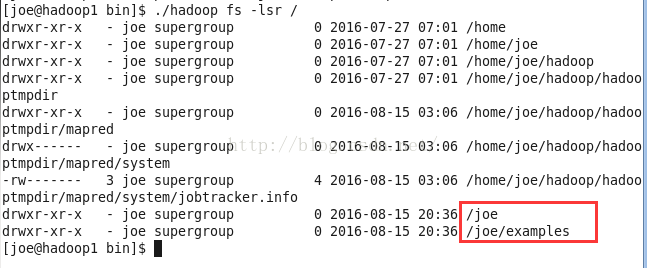
ps:Hadoop的mkdir命令会自动创建父目录。
上传文件fs -put
我们在使用hadoop的过程中,经常会需要把本地文件上传到hdfs中进行处理分析。
hdfs可以把本地文件上传到hdfs中,也就是把本地文件变成集群式的文件。
我们先在本地当前目录(也就是bin目录下)创建一个test.txt
vim test.txt输入内容hello,hadoop
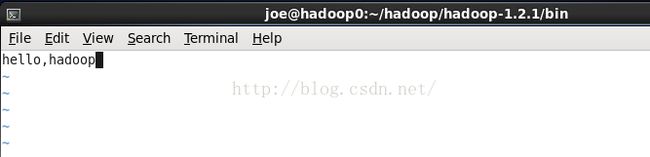

开始上传
./hadoop fs -put test.txt . 最后一个参数是句点,相当于放入了默认的工作目录,等价于hadoop fs -put test.txt /user/joe。
把test.txt文件放入hdfs默认文件夹中(也就是默认工作目录 /user/joe)。
我们也可以指定给文件重命名,例如test.txt上传成test2.txt。
./hadoop fs -put test.txt test2.txt 也可以不放在默认工作目录,而是指定目录/joe/examples
./hadoop fs -put test.txt /joe/examples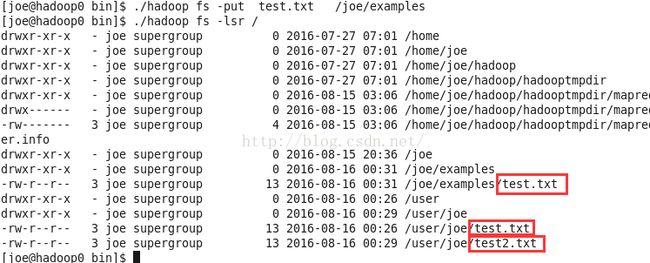
这个时候我们在hadoop1中查看也是看到同样的文件。所以文件已经在hdfs系统中了。也就是集群式的。
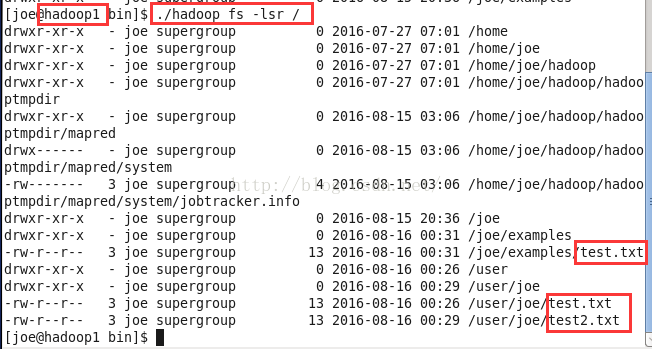
上传文件fs -copyFromLocal
将本地文件上传到hdfs文件系统中,等同与fs -put命令。
还是新建一个文件123.txt
vim 123.txt./hadoop -copyFromLocal 123.txt .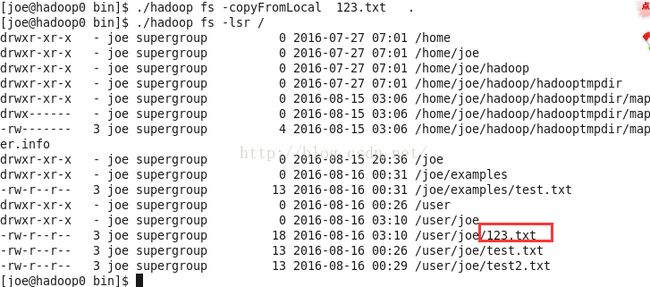
下载文件fs -get
我们刚才学习了上传文件到hdfs集群文件系统中,当然也有反向操作,把文件从集群中下载到本地。
./hadoop fs -get test2.txt .最后的参数是句点,代表当前目录,把hdfs默认目录(/user/joe)中的test2.txt下载到当前目录。

当然路径文件什么的我们都可以做相应调整,例如:
./hadoop fs -get /joe/examples/test.txt /home/joe下载文件fs -copyToLocal
把hdfs文件系统中的文件下载到本地,等同于fs -get。
./hadoop fs -copyToLocal 123.txt /home/joe将hdfs文件系统中的123.txt下载到本地 /home/joe目录中。
列出指定名称的目录和文件fs -ls /目录或文件名
列出HDFS系统中下名为joe的目录
./hadoop fs -ls /joe列出HDFS系统中下名为test.txt的文件
./hadoop fs -ls test.txt
查看hdfs中的文件内容fs -cat
查看文件内容
比如上面放到集群中的test.txt文件,如果我们要看里面写的什么
./hadoop fs -cat test.txt
可以看到里面的内容 就是我们创建文件时写的hello,hadoop
查看目录内容(*号)
我们还可以一次性查看某个目录下所有文件的内容,例如:
/user/joe/目录中有test.txt和test2.txt这2个文件。
./hadoop fs -cat /user/joe/*
用*号代表所有文件。
查看hdfs中的文件内容fs -text
./hadoop fs -text test.txt显示文件的内容,当文件为文本文件时,等同于cat,文件为压缩格式(gzip以及hadoop的二进制序列文件格式)时,会先解压缩。
查看hdfs中的文件内容fs -tail
查看文件尾部1K字节的内容,支持-f配置,也就是 持续输出。可以起到监控作用。
./hadoop fs -tail -f test.txt改变目录或文件所属组fs -chgrp
设置hdfs文件系统中的文件或目录属于哪个组,路径递归设置的话使用参数 -R。命令的使用者必须是文件的所有者或者超级用户。
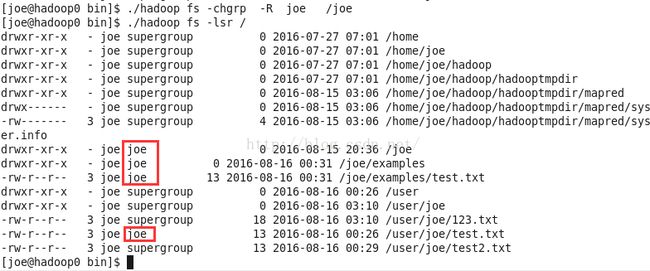
./hadoop fs -chgrp joe test.txt 设置test.txt为joe组拥有。
./hadoop fs -chgrp -R joe /joe递归设置目录joe和目录下的所有子目录examples和文件test.txt为joe组拥有。
如下图:本来所属组都是supergroup 现在相应目录和文件的组已经修改成了joe。
改变目录或文件所属人fs -chown
设置hdfs文件系统中的文件或目录属于哪个用户,路径递归设置的话使用参数-R。命令的使用者必须是文件的所有者或者超级用户。
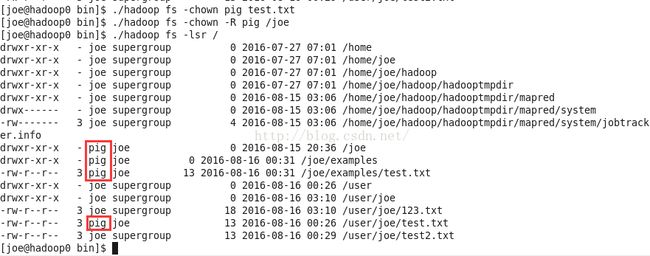
./hadoop fs -chown pig test.txt设置test.txt为pig用户拥有。
./hadoop fs -chown -R pig /joe递归设置joe目录和joe目录下的子目录和文件为pig用户拥有。
修改目录或文件的操作权限fs -chmod
设置hdfs文件系统中的文件或目录操作的权限是什么,路径递归设置的话使用参数-R。命令的使用者必须是文件的所有者或者超级用户。相应权限的3位数或+/-{rwx},跟linux的一样。详情可见:
linux基础(七)----linux命令系统学习----系统安全相关命令 这篇文章中的chmod参数详解。
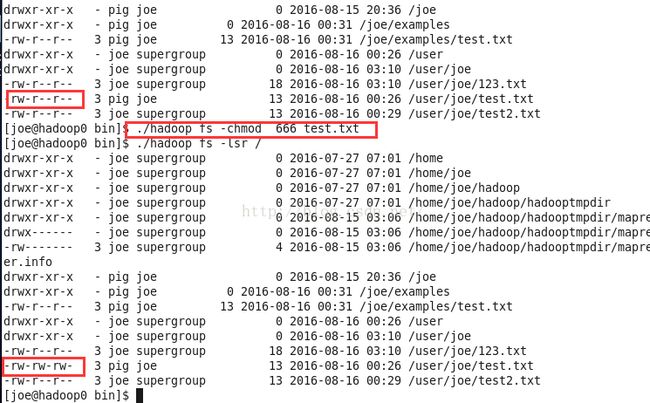
./hadoop fs -chmod 666 test.txt设置test.txt的权限为666,即所有用户所有组对它有读写权限。
查看目录文件数量fs -count
./hadoop fs -count /统计默认工作目录下的目录文件数量

显示为目录个数,文件个数,文件总计大小,输入路径。
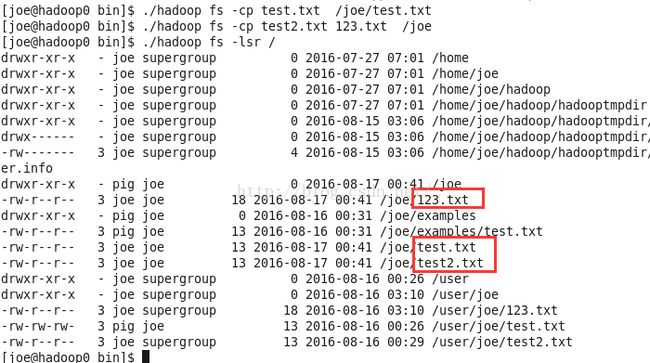
复制文件fs -cp
cp命令是将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
./hadoop fs -cp test.txt /joe/test.txt把test.txt复制到joe目录下。
./hadoop fs -cp test2.txt 123.txt /joe把test2.txt和123.txt复制到joe目录下。因为这里是多个源路径 所以 目标路径必须是一个目录/joe。
查看目录或者文件大小fs -du
./hadoop fs -du /joe显示joe目录中每个文件或目录的大小。

查看目录或者文件总大小fs -dus
./hadoop fs -dus /joe类似于du,参数为目录时,会显示该目录的总大小 。

检测目录文件是否存在fs -test
hadoop fs -test -[ezd] PATH
在 Linux 下,不管你是启动一个桌面程序也好,还是在控制台下运行命令,所有的程序在结束时,都会返回一个数字值,这个值叫做返回值,或者称为错误号 ( Error Number )。
在控制台下,有一个特殊的环境变量 $?,保存着前一个程序的返回值。
./hadoop fs -test -e /joe
echo $?
./hadoop fs -test -e test.txt
echo $?
./hadoop fs -test -z test.txt
echo $?
./hadoop fs -test -d test.txt
echo $?
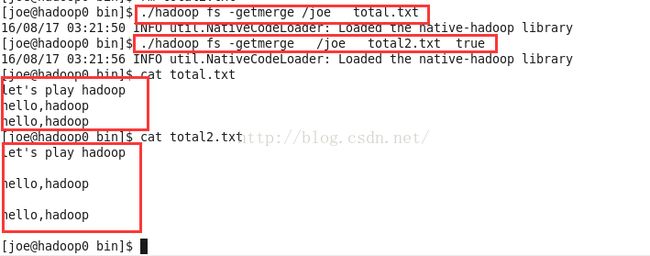
合并下载文件fs -getmerge
./hadoop fs -getmerge /joe total.txt 把hdfs文件系统中的所有文件合并为文件total.txt,total.txt位于当前目录,不在hdfs中,是本地文件。
./hadoop fs -getmerge /joe total2.txt true加上addnl的true后,合并到local file中的hdfs文件之间会空出一行.
ps:新版本中不用true了,改成了用-nl参数。
./hadoop fs -getmerge -nl /joe total2.txt详情可见:
Modify the option of FsShell getmerge from [addnl] to [-nl] for consistency
创建空文件fs -touchz
./hadoop fs -touchz /joe/blank.txt在/joe目录下创建一个空文件blank.txt

删除空目录或者文件fs -rm
从HDFS文件系统删除test.txt文件,rm命令也可以删除空目录
./hadoop fs -rm test.txt
删除目录以及子目录和文件fs -rmr
./hadoop fs -rmr /joe删除joe目录下的所有目录和文件。

清空回收站fs -expunge
清空回收站,文件被删除时,它首先会移到临时目录.Trash/中,当超过延迟时间之后,文件才会被永久删除,该命令能马上进行删除。
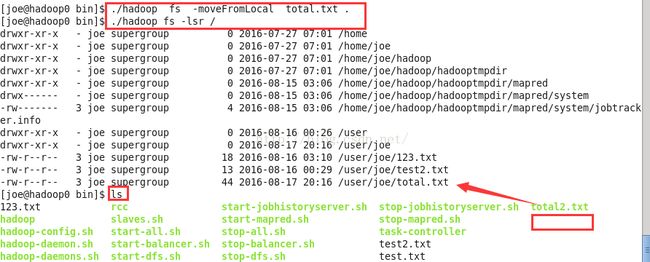
./hadoop fs -expunge 上传文件并删除原文件fs -moveFromLocal
和fs -put命令类似,上传目录或者源文件到hdfs中,但是源文件拷贝之后自身被删除。
./hadoop fs -moveFromLocal total.txt .将total.txt文件上传到hdfs的当前工作目录。并删除本地的total.txt文件。
下载文件并删除hdfs中的文件fs -moveToLocal
与fs -get命令相似,下载hdfs中的文件到本地目录,但拷贝结束后,删除HDFS上原文件。
./hadoop fs -moveToLocal total.txt .将hdfs系统默认工作目录(/user/joe)中的total.txt下载到本地当前目录并删除原文件。

当前1.0版本的hadoop中hdfs未实现该方法。后续版本中我们可以尝试。
移动文件fs -mv
将hdfs系统中的文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
./hadoop fs -mv test2.txt /home/test2.txt将默认工作目录中的test2.txt移动到home目录下。
./hadoop fs -mv total.txt 123.txt /home将默认工作目录中的total.txt和123.txt

改变副本数fs -setrep
设置副本数
fs setrep命令可以改变一个文件的副本系数。加-R参数可以递归的改变目录下所有文件的副本系数。
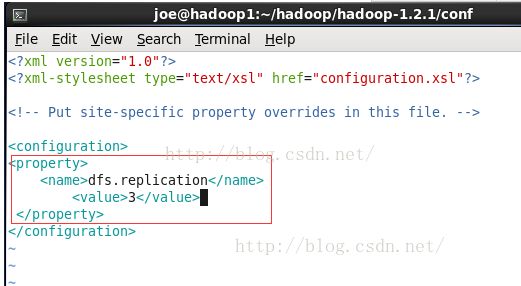
我们在安装篇配置hdfs-site.xml配置文件的时候 其实已经对副本数做了配置,这个命令是修改某个目录或者文件的副本数。
./hadoop fs -setrep 2 /home/123.txt将home目录中的123.txt的副本数设置为2。
./hadoop fs -setrep 2 -R /home将home目录下的所有目录文件的副本数递归设置为2。
查看当前hdfs的副本数
./hadoop fsck -locations
查看某个文件的副本数
可以通过ls中的文件描述符看到
./hadoop fs -ls /home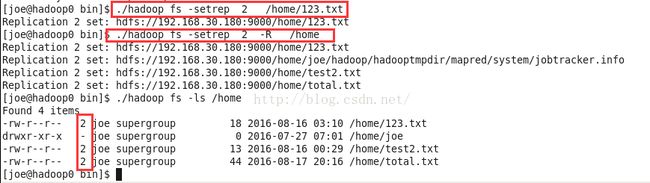
查看文件或者目录的统计信息fs -stat
返回对应路径的状态信息。可以通过与C语言中的printf类似的格式化字符串定制输出格式,这里支持的格式字符有:
%b:文件大小
%o:Block大小
%n:文件名
%r:副本个数
%y或%Y:最后一次修改日期和时间
默认情况输出最后一次修改日期和时间。
./hadoop fs -stat /home
./hadoop fs -stat '%b %o %n %r %y' /home
归档文件archive
./hadoop archive -archiveName gs.har -p /home har 命令中参数 -archiveName:压缩文件名,自己任意取;
-p:归档文件所在的父目录;
/home:要归档的文件名----如果不加文件名则是归档整个目录。
har:归档文件存放路径,这里用表示hdfs的默认目录也就是/user/joe下面的har目录。

查看har文件是否生成
./hadoop fs -ls har
可以看到已经生成了gs.har文件。
显示har的内容可以用如下命令
./hadoop fs -ls har/gs.har
显示har压缩的是那些文件可以用如下命令
./hadoop fs -ls -R har:///user/joe/har/gs.har
另外,我们可以像其它文件系统一样,操作har文件的下级目录,比如如上图中的joe目录:
./hadoop fs -ls -R har:///user/joe/har/gs.har/joe
远程操作归档文件也是很方便,只需要把主机名和端口写上就行了。---把hadoop0和端口以及路径换成自己对应的master使用的主机名和端口以及相应har路径就行。
./hadoop fs -ls -R har://hdfs-hadoop0:9000/user/joe/har/gs.har/joe
注意:har文件不能进行二次压缩。如果想给.har加文件,只能找到原来的文件,重新创建一个。har文件中原来文件的数据并没有变化,har文件真正的作用是减少NameNode和DataNode过多的空间浪费。
删除归档文件
./hadoop fs -rmr har/gs.har
hdfs管理与更新
启动hdfs
./start-dfs.sh关闭hdfs
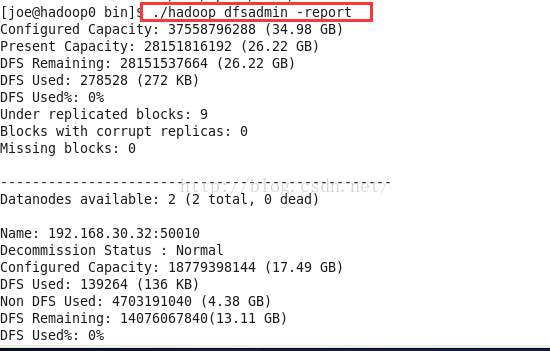
./stop-dfs.sh查看HDFS的基本统计信息
./hadoop dfsadmin -reportps:这里的dfs不能换成fs。
退出安全模式
NameNode在启动时会自动进入安全模式。安全模式是NameNode的一种状态,在这个阶段,文件系统不允许有任何修改。
系统显示Name node in safe mode,说明系统正处于安全模式,这时只需要等待十几秒即可,也可通过下面的命令退出安全模式:
./hadoop dfsadmin -safemode leaveps:这里的dfs不能换成fs。

进入安全模式
在必要情况下,可以通过以下命令把HDFS置于安全模式:
./hadoop dfsadmin -safemode enterps:这里的dfs不能换成fs。
![]()
节点添加
添加一个新的DataNode节点,先在新加节点上安装好Hadoop,要和NameNode使用相同的配置(可以直接从NameNode复制),修改$HADOOP_HOME/conf/master文件,加入NameNode主机名。然后在NameNode节点上修改$HADOOP_HOME/conf/slaves文件,加入新节点名,再建立新加节点无密码的SSH连接,运行启动命令为:
./start-all.sh负载均衡
HDFS的数据在各个DataNode中的分布可能很不均匀,尤其是在DataNode节点出现故障或新增DataNode节点时。新增数据块时NameNode对DataNode节点的选择策略也有可能导致数据块分布不均匀。用户可以使用命令重新平衡DataNode上的数据块的分布:
./start-balancer.sh![]()
格式化hdfs系统
./hadoop namenode -format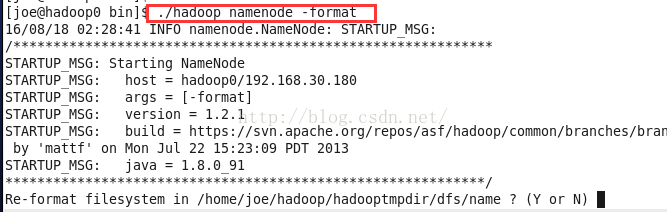
hdfs命令任意目录执行
我们之前操作hadoop命令首先第一步就是进入hadoop安装的bin目录。
为了每次执行hadoop的时候,不用进入hadoop的安装的bin目录,也不用加上hadoop的安装的bin路径,要做的事情就是将其安装路径加入到PATH(全局路径)中,这样就可以直接执行hadoop命令。
操作如下:
我这里的安装路径是
/home/joe/hadoop/hadoop-1.2.1/bin/
需要先切换到root角色
su -vim /etc/profile在最后加入一句
export HADOOP_INSTALL=/home/joe/hadoop/hadoop-1.2.1这里的路径对应自己的安装路径。
注意这里要写HADOOP_INSTALL,因为如果写HADOOP_HOME会在执行命令的时候提醒该已经deprecated
然后将其bin加入到PATH中,再加上一句:
export PATH=$HADOOP_INSTALL/bin:$PATH
让配置文件生效
source /etc/profile把用户切换回 joe
su joe这个时候在任意路径都可以尝试之前的操作命令。不需要在bin目录执行./hadoop了。
任意命令执行hadoop 命令就行。
如下:
hadoop fs -ls /
我不在bin目录 也可以执行hadoop命令了。
简化hdfs命令
简化hdfs命令其实就是作一些简化的命令声明。
因为我们现在需要输入hadoop fs - 这样的格式才能执行hadoop命令。
命令比较长,如果我们想简化的话:
先切换到root 用户
su -在用户根目录下
vim .bashrc
alias fs='hadoop fs'
alias fsa='hadoop dfsadmin'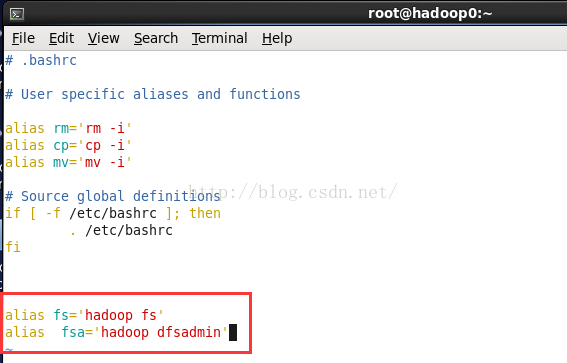
source .bashrcfs -ls
fs -mkdir input
fsa -safemode leave
组操作
sudo addgroup hadoop#添加一个hadoop组
sudo usermod -a -G hadoop zzq #将当前用户zzq加入到hadoop组
sudo gedit etc/sudoers#将hadoop组加入到sudoer
在root ALL=(ALL) ALL后 hadoop ALL=(ALL) ALL