标准化与归一化 (机器学习)
归一化和标准化经常被搞混,程度还比较严重,非常干扰大家的理解。
为了方便后续的讨论,必须先明确二者的定义。
1.线性归一化
如果要把输入数据转换到[0,1]的范围,可以用如下公式进行计算:
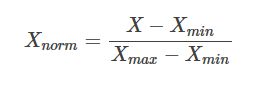
按以上方式进行归一化以后,输入数据转换到[0,1]的范围。
有时候我们希望将输入转换到[-1,1]的范围,可以使用以下的公式
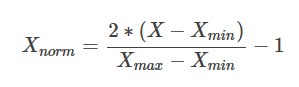
以上两种方式,都是针对原始数据做等比例的缩放。其中Xnorm 是归一化以后的数据,X是 原始数据大小,Xmax Xmin 分别是原始数据的最大值与最小值。公式简单明了,很容易懂。
除了将数据缩放到[0,1]或[-1,1]的范围,实际中还经常有其他缩放需求。
例如在进行图像处理的过程中,获得的灰度图像的灰度值在[0,255]之间。常用的处理方式之一就是将像素值除以255,就缩放到了[0,1]之间。而在RGB图像转灰度图像的过程中,经常就将灰度值限定在[0,255]之间。
2.均值归一化/标准化
0均值归一化将输入的原始数据集归一化为均值为0,方差为1的数据集。具体的归一化公式如下:
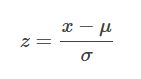
其中,μ,σ是原始 数据集的均值与标准差。
进一步明确二者含义:
归一化和标准化的相同点都是对某个特征(column)进行缩放(scaling)而不是对某个样本的特征向量(row)进行缩放。对特征向量进行缩放是毫无意义的(坑1),比如三列特征:身高、体重、血压。每一条样本(row)就是三个这样的值,对这个row无论是进行标准化还是归一化都是好笑的,因为你不能将身高、体重和血压混到一起去!
在线性代数中,将一个向量 除以向量的长度,也被称为标准化,不过这里的标准化是将向量变为长度为1的单位向量,它和我们这里的标准化不是一回事儿,不要搞混哦(坑2)。
2、 标准化和归一化的对比分析
首先明确,在机器学习中,标准化是更常用的手段,归一化的应用场景是有限的。我总结原因有两点:
-
1、标准化更好保持了样本间距。当样本中有异常点时,归一化有可能将正常的样本“挤”到一起去。比如三个样本,某个特征的值为1,2,10000,假设10000这个值是异常值,用归一化的方法后,正常的1,2就会被“挤”到一起去。如果不幸的是1和2的分类标签还是相反的,那么,当我们用梯度下降来做分类模型训练时,模型会需要更长的时间收敛,因为将样本分开需要更大的努力!而标准化在这方面就做得很好,至少它不会将样本“挤到一起”。
-
2、标准化更符合统计学假设对一个数值特征来说,很大可能它是服从正态分布的。标准化其实是基于这个隐含假设,只不过是略施小技,将这个正态分布调整为均值为0,方差为1的标准正态分布而已。
3、逻辑回归必须要进行标准化吗?
真正的答案是,这取决于我们的逻辑回归是不是用正则。
如果你不用正则,那么,标准化并不是必须的,如果你用正则,那么标准化是必须的。(坑3)
为什么呢?
因为不用正则时,我们的损失函数只是仅仅在度量预测与真实的差距,加上正则后,我们的损失函数除了要度量上面的差距外,还要度量参数值是否足够小。而参数值的大小程度或者说大小的级别是与特征的数值范围相关的。
举例来说,我们用体重预测身高,体重用kg衡量时,训练出的模型是:
身高 = 体重*x
x就是我们训练出来的参数。
当我们的体重用吨来衡量时,x的值就会扩大为原来的1000倍。
在上面两种情况下,都用L1正则的话,显然对模型的训练影响是不同的。
假如不同的特征的数值范围不一样,有的是0到0.1,有的是100到10000,那么,每个特征对应的参数大小级别也会不一样,在L1正则时,我们是简单将参数的绝对值相加,因为它们的大小级别不一样,就会导致L1最后只会对那些级别比较大的参数有作用,那些小的参数都被忽略了。
如果不用正则,那么标准化对逻辑回归有什么好处吗?
答案是有好处,进行标准化后,我们得出的参数值的大小可以反应出不同特征对样本label的贡献度,方便我们进行特征筛选。如果不做标准化,是不能这样来筛选特征的。
做标准化有什么注意事项吗?
最大的注意事项就是先拆分出test集,不要在整个数据集上做标准化,因为那样会将test集的信息引入到训练集中,这是一个非常容易犯的错误!
4、决策树需要标准化吗?
答不需要!标准化。因为决策树中的切分依据,信息增益、信息增益比、Gini指数都是基于概率得到的,和值的大小没有关系。另外同属概率模型的朴素贝叶斯,隐马尔科夫也不需要标准化。
5、什么时候用归一化?什么时候用标准化?
可以看看这篇文章:https://www.jianshu.com/p/95a8f035c86c