apache calcite 新手入门 hello world
简述
业务员与开发人员经常口述 能不能帮我导点 xxx数据,隔几个小时又来能不能给我导 xxx数据。反复接收到这样的任务心里一万个CNM。那能不能智能点呢,如果业务人员会SQL,你就会想能不能写个能识别SQL语句的功能让她想导什么就导什么。如,文件太大,她想用SQL查看抽样信息。在比如,内存redis想看内存的数据信息。还有hbase敲命令好复杂,我能不能自己写个SQL语法解析器来转换成命令执行呢。还可能 关系型数据库与nosql数据库使用SQL关联查询。如果自己写个简单的SQL语法解析器还好,关联查询复杂嵌套各种函数相结合的SQL自己解析可能是恶魔。俗话说不要重复造轮子,把自己的逻辑思想核心代码全部投入业务中去。calcite的出现可以解决该问题。
介绍
开发人员使用SQL查询数据,相信大家都执行过相关操作,大家之前可能查询的都是DBMS, 玩大数据的应该都使用过phoenix、hive、spark on sql 、elasticsearch on sql 等相关的SQL操作。但是如果想 玩redis sql相信大家就苦恼了,没有开源支持。
apache calcite是一个行业标准的SQL解析器,对编写的SQL智能优化,任何数据任何地方都可以集成SQL功能,这就是它的强大。
背景
官方解释
Apache Calcite是一个动态的数据管理框架,它包含许多构成典型数据库管理系统的部分,但省略了一些关键功能:数据存储,数据处理的算法以及存储元数据的存储库。
工具
废话不多说,这里先编写个最简单的hello world,让大家小试牛刀有个大概的了解。
官网链接:https://calcite.apache.org/
想要深入的可以研究官方例子:https://github.com/apache/calcite/tree/master/example/csv/src/main/java/org/apache/calcite/adapter/csv
需要工具,IDEA,JDK8,maven
项目目录
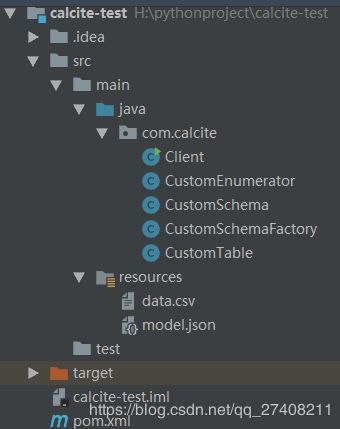
说明
- Client.java # 客户端
- CustomEnumerator.java # 数据输出类
- CustomSchema # 数据库映射类
- CustomScheamFactory # 数据库工厂类
- CustomTable # 数据表类
- data.csv # 数据文件
- model.json # 映射文件,也可以通过字符串传入
- pom.xml代码依赖如图
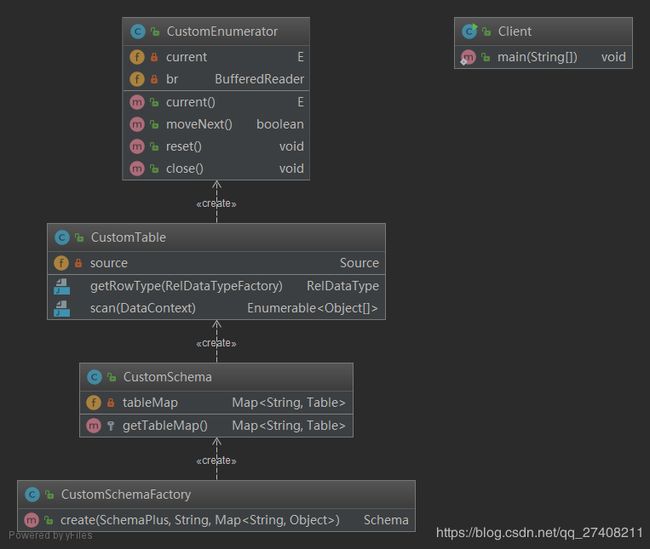
先上代码
pom.xml
4.0.0
com.calcite
calcite-test
1.0-SNAPSHOT
calcite-test
UTF-8
1.8
1.8
org.apache.calcite
calcite-core
1.18.0
资源文件
resources
data.csv
hello,worldmodel.json
{
"version": "1.0",
"defaultSchema": "TEST",
"schemas": [{
"name": "TEST",
"type": "custom",
"factory": "com.calcite.CustomSchemaFactory",
"operand": {}
}
]
}源代码
src/main/java/
com/calcite
如果使用model.json文件可以把注释放开,注释下面两行即可。执行SQL 框架会自动转成大写,Schema设置表名Key的时候注意也要大写
Client.java
package com.calcite;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLDecoder;
import java.sql.*;
/**
* Hello world!
*/
public class Client {
public static void main(String[] args) {
try {
/**
* 用文件的方式
* */
// URL url = Client.class.getResource("/model.json");
// String str = URLDecoder.decode(url.toString(), "UTF-8");
// Properties info = new Properties();
// info.put("model", str.replace("file:", ""));
// Connection connection = DriverManager.getConnection("jdbc:calcite:", info);
/**
* 测试的时候用字符串
* defaultSchema 默认数据库
* name 数据库名称
* type custom
* factory 请求接收类,该类会实例化Schema也就是数据库类,Schema会实例化Table实现类,Table会实例化数据类。
* operand 动态参数,ScheamFactory的create方法会接收到这里的数据
* */
String model = "{\"version\":\"1.0\",\"defaultSchema\":\"TEST\",\"schemas\":[{\"name\":\"TEST\",\"type\":\"custom\",\"factory\":\"com.calcite.CustomSchemaFactory\",\"operand\":{}}]}";
Connection connection = DriverManager.getConnection("jdbc:calcite:model=inline:" + model);
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("select * from test01");
while (resultSet.next()) {
System.out.println("data => ");
System.out.println(resultSet.getObject("value"));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
CustomEnumerator.java
package com.calcite;
import org.apache.calcite.linq4j.Enumerator;
import org.apache.calcite.util.Source;
import java.io.BufferedReader;
import java.io.IOException;
/**
* 数据输出
* */
public class CustomEnumerator implements Enumerator {
private E current;
private BufferedReader br;
public CustomEnumerator(Source source) {
try {
this.br = new BufferedReader(source.reader());
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public E current() {
return current;
}
@Override
public boolean moveNext() {
try {
String line = br.readLine();
if(line == null){
return false;
}
current = (E)new Object[]{line}; // 如果是多列,这里要多个值
} catch (IOException e) {
e.printStackTrace();
return false;
}
return true;
}
/**
* 出现异常走这里
* */
@Override
public void reset() {
System.out.println("报错了兄弟,不支持此操作");
}
/**
* InputStream流在这里关闭
* */
@Override
public void close() {
}
}
数据库的映射类,由它例化表
CustomSchema.java
package com.calcite;
import com.google.common.collect.ImmutableMap;
import com.google.common.collect.Multimap;
import org.apache.calcite.linq4j.tree.Expression;
import org.apache.calcite.rel.type.RelProtoDataType;
import org.apache.calcite.schema.*;
import org.apache.calcite.schema.impl.AbstractSchema;
import org.apache.calcite.util.Source;
import org.apache.calcite.util.Sources;
import java.io.File;
import java.io.UnsupportedEncodingException;
import java.net.URL;
import java.net.URLDecoder;
import java.util.Map;
import java.util.Set;
/**
* 类似数据库,Schema表示数据库
* */
public class CustomSchema extends AbstractSchema {
private Map tableMap;
@Override
protected Map getTableMap() {
URL url = CustomSchema.class.getResource("/data.csv");
Source source = Sources.of(url);
if (tableMap == null) {
final ImmutableMap.Builder builder = ImmutableMap.builder();
builder.put("TEST01",new CustomTable(source)); // 一个数据库有多个表名,这里初始化,大小写要注意了,TEST01是表名。
tableMap = builder.build();
}
return tableMap;
}
}
工厂类实例化Schema类
CustomSchemaFactory.java
package com.calcite;
import org.apache.calcite.schema.Schema;
import org.apache.calcite.schema.SchemaFactory;
import org.apache.calcite.schema.SchemaPlus;
import java.util.Map;
/**
* 自定义schemaFacoty 入口
* 由配置文件配置工厂类
* ModelHandler 会调这个工厂类
* */
public class CustomSchemaFactory implements SchemaFactory {
/**
* parentSchema 他的父节点,一般为root
* name 数据库的名字,它在model中定义的
* operand 也是在mode中定义的,是Map类型,用于传入自定义参数。
* */
@Override
public Schema create(SchemaPlus parentSchema, String name, Map operand) {
return new CustomSchema();
}
}
数据表的映射类,
ScannableTable 扫描表,实现scan方法,不用担心,框架会调用scan方法
AbstractTable 是一个抽象类,大多方法已经实现,在这里只需要实现 getRowType 设置列名和类型即可,框架会调用
CustomTable.java
package com.calcite;
import org.apache.calcite.DataContext;
import org.apache.calcite.adapter.java.JavaTypeFactory;
import org.apache.calcite.linq4j.AbstractEnumerable;
import org.apache.calcite.linq4j.Enumerable;
import org.apache.calcite.linq4j.Enumerator;
import org.apache.calcite.rel.type.RelDataType;
import org.apache.calcite.rel.type.RelDataTypeFactory;
import org.apache.calcite.schema.ScannableTable;
import org.apache.calcite.schema.impl.AbstractTable;
import org.apache.calcite.sql.type.SqlTypeName;
import org.apache.calcite.util.Pair;
import org.apache.calcite.util.Source;
import java.util.ArrayList;
import java.util.List;
public class CustomTable extends AbstractTable implements ScannableTable {
private Source source;
public CustomTable(Source source) {
this.source = source;
}
@Override
public RelDataType getRowType(RelDataTypeFactory relDataTypeFactory) {
JavaTypeFactory typeFactory = (JavaTypeFactory)relDataTypeFactory;
List names = new ArrayList<>();
names.add("value");
List types = new ArrayList<>();
types.add(typeFactory.createSqlType(SqlTypeName.VARCHAR));
return typeFactory.createStructType(Pair.zip(names,types));
}
@Override
public Enumerable scan(DataContext dataContext) {
return new AbstractEnumerable() {
@Override
public Enumerator enumerator() {
return new CustomEnumerator<>(source);
}
};
}
}