MYSQL---日志
本文将探讨以下几个问题。
一、思考
- 问题一:MYSQL执行流程中会产生哪些日志?
相信大家都接触过binlog,redolog,undolog这些字眼,那么这些日志究竟在何时产生,存放于什么位置呢?
- 问题二:这些日志的作用是什么?
MYSQL产生这些日志的目的在于什么,或者说每一个日志能带来什么作用?
二、分析
2.1binlog
-
binlog功能开启
可通过以下命令检查binlog功能是否开启:

如果log_bin的value为OFF,可通过修改配置文件my.ini开启:
![]()
该值为binlog日志文件名称,可随意填,日志文件路径为datadir参数值。修改配置文件后,需要重启mysql服务方可生效。当开启之后会在log_bin_basename所在目录产生以下两个文件:

mylog.000001:binlog日志文件,记录了所有的DDL(数据定义语言)和DML(数据操纵语言,不包含数据查询语言)。
mylog.index:binlog索引文件,记录所有的二进制文件。
-
binlog查看方式
直接打开该文件为乱码,安装MYSQL时,其为我们提供了查看此日志的工具,即mysqlbinlog.exe。该工具位于mysql服务安装目录bin目录之下。使用方式:
mysqlbinlog --no-defaults mylog.000001,该命令查看的日志具体SQL部分被进行base64编码,可通过
mysqlbinlog --no-defaults --base64-output=decode-rows -v .\mylog.000001 > .\binlog.txt,将base64解码后的文件写到mylog.txt查看。
-
binlog产生时机和内容
当进行以下操作时,会将操作内容记录到binlog。
- 数据定义:即CREATE、ALTER、DROP、TRUNCATE、RENAME操作。
- 数据操作:INSERT、UPDATE、DELETE。
接下来,我们以INSERT为例,查看binlog记录的内容:
插入语句为:INSERT INTO role (`name`,`desc`) VALUES ('a','b');
通过mysqlbinlog工具打开mylog.0000001文件内容如下:
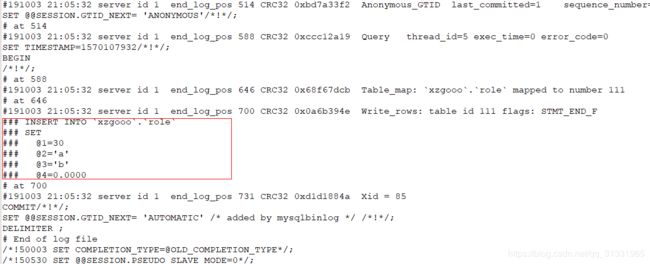
-
binlog文件作用
- 主从复制。
- 数据恢复。
这里只是了解,后面会专门写一篇主从复制和数据恢复相关内容。
2.2redolog
-
redolog产生背景
当修改DB某一行数据时,会先将该数据从磁盘读取到内存中的缓冲池进行修改,这时内存中的值与磁盘中的值相比就有了差异,这种有差异性的数据也被称之为“脏页”。这种差异性导致,当内存中的缓冲数据还未刷新到磁盘中,此时如果系统崩溃,便会造成数据丢失。redolog便是为了解决这样的问题。
-
redolog存放位置
datadir目录/ib_logfile*文件中。
-
redolog产生的时机和内容
- 产生时机:事务完全提交之前。当我们提交一个事务时,InnoDB会先将修改的数据写入到日志文件中,再去修改内存中的缓冲区的数据。
- 内容:redolog主要记录了数据被修改之后的值。用于宕机之后的数据恢复。
-
redolog的产生流程
我们先看一下redolog的设计架构:

redolog_buffer为InnoDB层面的缓存,os_buffer为操作系统层面的缓存。fsync函数的作用便是将os_buffer中的缓存刷新到磁盘,设置缓存的目的也是为了避免每次都写入磁盘而带来的开销。
对于redo_log_buffer,这里借用《MYSQL实战45讲》中的举例说明:
酒馆老板有一个账本,假如每次客人赊账时,酒馆老板都找到账本,再找到对应的客人记一笔记录,那在客流量较大时,效率则会非常慢。于是酒店老板弄了个小黑板,每次客人赊账时,先将记录直接写到小黑板上,待打烊时,将黑板的内容写到账本中。如果小黑板内容已满,则先空下来,将小黑板内容写到账本。
这个过程在MYSQL的实现中也称为WAL技术(Writing-Ahead logging),即先写日志,再写磁盘。而这里的小黑板类比redo_log_buffer,账本类比redo_log_file。
在介绍redolog产生流程之前,我们有必要了解一个参数,其控制了redolog的写入策略。

该参数共有三个取值,分别代表三种不同策略:
0:事务提交时,仅将日志写到redo_log_buffer,不会直接写入到os_buffer中,而是每秒从redo_log_buffer中写到os_buufer中,并调用fsync刷新到磁盘。
1(默认):事务提交时,将日志写到redo_log_buffer,同时将redo_log_buffer中的日志写到os_buffer,再调用fsync刷新到磁盘。
2:事务提交时,不写入redo_log_buffer,而是直接写入os_buffer,然后每秒调用fsync刷新到磁盘。
那么这三个不同的取值会带来什么影响呢?我们从DB故障和操作系统故障两个方面分析一下。
0:其每隔一秒从os_buffer刷新到磁盘,假如刚好在一秒的间隙内,此时DB故障,redo_log_buffer的内容会丢失,导致这一秒间隙内的数据将丢失。
2:日志将直接写入到os_buffer中,这样当操作系统发生故障时,日志还未从os_buffer刷新到磁盘,造成数据丢失。
1:此时每次redo_log_buffer和os_buffer中都有数据。只要当DB故障和操作系统故障恢复,都能将数据重新写入磁盘。
有了以上内容,我们再分析一下当一个更新事务来临时,redolog的产生流程是怎样的?
- 查询磁盘数据到内存中的缓存区。
- 修改数据,依然保存到缓存。
- 事务提交时,先生成一条redolog日志。
- 根据innodb_flush_log_at_trx_commit参数,执行对应的策略,将日志写入到文件。
- 提交事务。
- 将内存中的更新后的数据写入到文件。
-
redolog的作用
redolog可以进行数据恢复,因为其保存了数据被修改之后的值,这样当DB故障或者操作系统故障修复之后,便能通过该日志恢复之前的操作。事务的持久性也是通过redolog实现的,这种机制被称之为“Force log at commint”,即事务在提交之前必须成功写入redolog。
后面会写一篇博文专门分析事务的实现原理。
2.3undolog
在上一小节我们介绍了redolog,其主要用来实现持久性。那么如果事务执行过程中出错,那么我们如何得到事务开始时的数据呢,这就要用到接下来所说的undolog。
-
undolog存放位置
datadir目录/ibdata*(即默认存在于系统表空间),也可通过一下参数修改:

-
undolog产生的时机和内容
- 产生时机:在数据修改时,会记录相应的undolog。如果操作的非临时表,则记录undolog的操作也会记录redolog。
- 内容:老版本数据。可以认为当delete一条记录时,undo log中会记录一条对应的insert记录,反之亦然,当update一条记录时,它记录一条对应相反的update记录。
-
undolog的作用
redolog保证了事务一旦提交,则其所有的修改必然同步到数据文件。而undolog则是针对事务失败情况,将赎回恢复到事务开始状态。
- 事务回滚。
- MVCC。
三、其他
- 日志分层
binlog属于Server层产生,所有存储引擎都有。而redolog和undolog是InnoDB引擎特有。
- redolog和binlog写入顺序,redolog的两阶段提交(引用《MYSQL实战45讲》02篇)
假设有这样一条SQL:UPDATE t SET x=x+1 WHERE id=1,其执行流程如下:
- 执行器将命令发送给执行引擎InnoDB。
- InnoDB引擎从磁盘上查询到t表id=1对应的行数据并将其加载到内存返回给执行器。
- 执行器拿到数据之后将x值加1,产生一个新的数据行,并调用InnoDB引擎的接口写入这个数据行。
- InnoDB引擎将这行新数据保存到内存,并记录一条redo_log日志,此时redolog处于prepare状态。
- InnoDB引擎告知执行器可以随时提交事务。
- 执行器生成这个操作的binlog。并把binlog写入磁盘。
- 执行器调用InnoDB引擎的事务提交接口,并将redolog状态改为commit,更新完成。
可以看出“两阶段提交”体现在:redolog处于prepare状态---写binglog---redolog处于commit状态。这样做的目的也是为了保证数据一致性,即binlog中的操作和数据文件中对应的数据是一致的,以免日后利用binlog做数据恢复时,数据不完整。我们借用《MYSQL实战45讲》02篇的反证法来说明一下,假如不按照两阶段提交,会有什么问题:
- 假如先写完redolog再写binlog。这种情况当redolog写完之后,如果MYSQL服务故障,导致没有写入binlog。。当MYSQL服务故障恢复之后,可以根据redolog将数据恢复,但是binlog将永远丢失这条数据。日后如果根据binlog做数据恢复,那该条数据流丢失。
- 假如先写完binlog再写redolog。这种情况当binlog写完之后,如果MYSQL服务故障,导致没有写入redolog。当MYSQL服务故障恢复之后,由于redolog中没有该条记录,这条数据将不存在。但是binlog确有这条数据。日后如果根据binlog做数据恢复,那将会多出这条数据。
本文只是简单介绍了InnoDB引擎的三种日志。后续也会专门写事务和MVCC的博文,来探索事务是如何借助日志来实现其特性的,以及MVCC的实现原理。
如果你想进一步了解,例如各种日志的数据结构,请参考一下文章:
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
参考文章:
- <
>02篇 - redolog是什么:https://zhuanlan.zhihu.com/p/35355751
- 详细分析MySQL事务日式:https://www.cnblogs.com/DataArt/p/10209573.html
- InnoDB.undolog漫游:http://mysql.taobao.org/monthly/2015/04/01/
- InnoDB.redolog漫游:http://mysql.taobao.org/monthly/2015/05/01/