cuda学习从入门到精通-第一篇
CUDA从入门到精通(零):写在前面
在老板的要求下,本博主从2012年上高性能计算课程开始接触CUDA编程,随后将该技术应用到了实际项目中,使处理程序加速超过1K,可见基于图形显示器的并行计算对于追求速度的应用来说无疑是一个理想的选择。还有不到一年毕业,怕是毕业后这些技术也就随毕业而去,准备这个暑假开辟一个CUDA专栏,从入门到精通,步步为营,顺便分享设计的一些经验教训,希望能给学习CUDA的童鞋提供一定指导。个人能力所及,错误难免,欢迎讨论。
PS:申请专栏好像需要先发原创帖超过15篇。。。算了,先写够再申请吧,到时候一并转过去。
CUDA从入门到精通(一):环境搭建
NVIDIA于2006年推出CUDA(Compute Unified Devices Architecture),可以利用其推出的GPU进行通用计算,将并行计算从大型集群扩展到了普通显卡,使得用户只需要一台带有Geforce显卡的笔记本就能跑较大规模的并行处理程序。
使用显卡的好处是,和大型集群相比功耗非常低,成本也不高,但性能很突出。以我的笔记本为例,Geforce 610M,用DeviceQuery程序测试,可得到如下硬件参数:
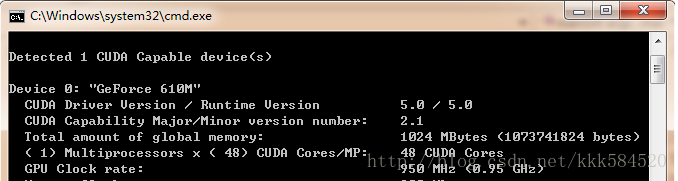
计算能力达48X0.95 = 45.6 GFLOPS。而笔记本的CPU参数如下:

CPU计算能力为(4核):2.5G*4 = 10GFLOPS,可见,显卡计算性能是4核i5 CPU的4~5倍,因此我们可以充分利用这一资源来对一些耗时的应用进行加速。
好了,工欲善其事必先利其器,为了使用CUDA对GPU进行编程,我们需要准备以下必备工具:
1. 硬件平台,就是显卡,如果你用的不是NVIDIA的显卡,那么只能说抱歉,其他都不支持CUDA。
2. 操作系统,我用过windows XP,Windows 7都没问题,本博客用Windows7。
3. C编译器,建议VS2008,和本博客一致。
4. CUDA编译器NVCC,可以免费免注册免license从官网下载CUDA ToolkitCUDA下载,最新版本为5.0,本博客用的就是该版本。
5. 其他工具(如Visual Assist,辅助代码高亮)
准备完毕,开始安装软件。VS2008安装比较费时间,建议安装完整版(NVIDIA官网说Express版也可以),过程不必详述。CUDA Toolkit 5.0里面包含了NVCC编译器、设计文档、设计例程、CUDA运行时库、CUDA头文件等必备的原材料。
安装完毕,我们在桌面上发现这个图标:

不错,就是它,双击运行,可以看到一大堆例程。我们找到Simple OpenGL这个运行看看效果:
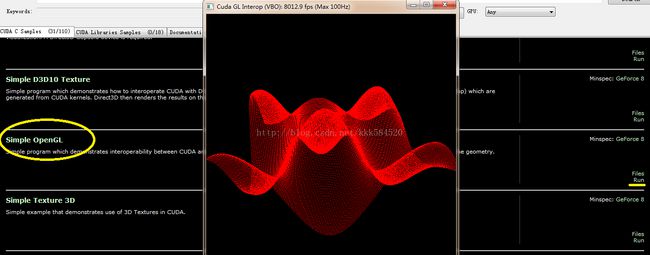
点右边黄线标记处的Run即可看到美妙的三维正弦曲面,鼠标左键拖动可以转换角度,右键拖动可以缩放。如果这个运行成功,说明你的环境基本搭建成功。
出现问题的可能:
1. 你使用远程桌面连接登录到另一台服务器,该服务器上有显卡支持CUDA,但你远程终端不能运行CUDA程序。这是因为远程登录使用的是你本地显卡资源,在远程登录时看不到服务器端的显卡,所以会报错:没有支持CUDA的显卡!解决方法:1. 远程服务器装两块显卡,一块只用于显示,另一块用于计算;2.不要用图形界面登录,而是用命令行界面如telnet登录。
2.有两个以上显卡都支持CUDA的情况,如何区分是在哪个显卡上运行?这个需要你在程序里控制,选择符合一定条件的显卡,如较高的时钟频率、较大的显存、较高的计算版本等。详细操作见后面的博客。
好了,先说这么多,下一节我们介绍如何在VS2008中给GPU编程。 CUDA从入门到精通(二):第一个CUDA程序
书接上回,我们既然直接运行例程成功了,接下来就是了解如何实现例程中的每个环节。当然,我们先从简单的做起,一般编程语言都会找个helloworld例子,而我们的显卡是不会说话的,只能做一些简单的加减乘除运算。所以,CUDA程序的helloworld,我想应该最合适不过的就是向量加了。
打开VS2008,选择File->New->Project,弹出下面对话框,设置如下:
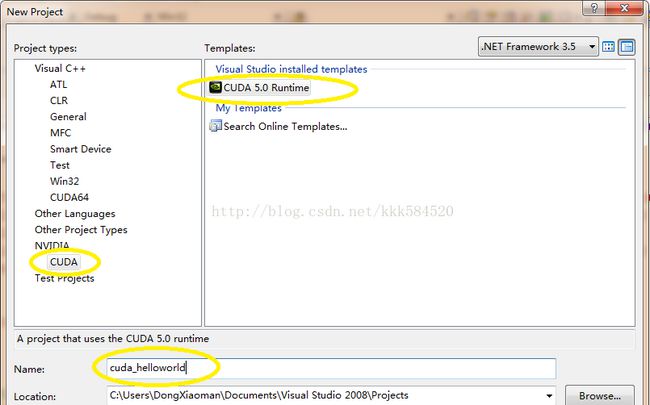
之后点OK,直接进入工程界面。
工程中,我们看到只有一个.cu文件,内容如下:
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size);
- __global__ void addKernel(int *c, const int *a, const int *b)
- {
- int i = threadIdx.x;
- c[i] = a[i] + b[i];
- }
- int main()
- {
- const int arraySize = 5;
- const int a[arraySize] = { 1, 2, 3, 4, 5 };
- const int b[arraySize] = { 10, 20, 30, 40, 50 };
- int c[arraySize] = { 0 };
- // Add vectors in parallel.
- cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
- printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
- c[0], c[1], c[2], c[3], c[4]);
- // cudaThreadExit must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaThreadExit();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaThreadExit failed!");
- return 1;
- }
- return 0;
- }
- // Helper function for using CUDA to add vectors in parallel.
- cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size)
- {
- int *dev_a = 0;
- int *dev_b = 0;
- int *dev_c = 0;
- cudaError_t cudaStatus;
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
- // Allocate GPU buffers for three vectors (two input, one output) .
- cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- // Copy input vectors from host memory to GPU buffers.
- cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- // Launch a kernel on the GPU with one thread for each element.
- addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
- // cudaThreadSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaThreadSynchronize();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- Error:
- cudaFree(dev_c);
- cudaFree(dev_a);
- cudaFree(dev_b);
- return cudaStatus;
- }
- __global__ void addKernel(int *c, const int *a, const int *b)
- {
- int i = threadIdx.x;
- c[i] = a[i] + b[i];
- }
这个函数就是在GPU上运行的函数,称之为核函数,英文名Kernel Function,注意要和操作系统内核函数区分开来。
我们直接按F7编译,可以得到如下输出:
- 1>------ Build started: Project: cuda_helloworld, Configuration: Debug Win32 ------
- 1>Compiling with CUDA Build Rule...
- 1>"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\nvcc.exe" -G -gencode=arch=compute_10,code=\"sm_10,compute_10\" -gencode=arch=compute_20,code=\"sm_20,compute_20\" --machine 32 -ccbin "C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\bin" -Xcompiler "/EHsc /W3 /nologo /O2 /Zi /MT " -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\include" -maxrregcount=0 --compile -o "Debug/kernel.cu.obj" kernel.cu
- 1>tmpxft_000000ec_00000000-8_kernel.compute_10.cudafe1.gpu
- 1>tmpxft_000000ec_00000000-14_kernel.compute_10.cudafe2.gpu
- 1>tmpxft_000000ec_00000000-5_kernel.compute_20.cudafe1.gpu
- 1>tmpxft_000000ec_00000000-17_kernel.compute_20.cudafe2.gpu
- 1>kernel.cu
- 1>kernel.cu
- 1>tmpxft_000000ec_00000000-8_kernel.compute_10.cudafe1.cpp
- 1>tmpxft_000000ec_00000000-24_kernel.compute_10.ii
- 1>Linking...
- 1>Embedding manifest...
- 1>Performing Post-Build Event...
- 1>copy "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart*.dll" "C:\Users\DongXiaoman\Documents\Visual Studio 2008\Projects\cuda_helloworld\Debug"
- 1>C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart32_50_35.dll
- 1>C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\cudart64_50_35.dll
- 1>已复制 2 个文件。
- 1>Build log was saved at "file://c:\Users\DongXiaoman\Documents\Visual Studio 2008\Projects\cuda_helloworld\cuda_helloworld\Debug\BuildLog.htm"
- 1>cuda_helloworld - 0 error(s), 105 warning(s)
- ========== Build: 1 succeeded, 0 failed, 0 up-to-date, 0 skipped ==========
可见,编译.cu文件需要利用nvcc工具。该工具的详细使用见后面博客。
直接运行,可以得到结果图如下:

如果显示正确,那么我们的第一个程序宣告成功!
刚入门CUDA,跑过几个官方提供的例程,看了看人家的代码,觉得并不难,但自己动手写代码时,总是不知道要先干什么,后干什么,也不知道从哪个知识点学起。这时就需要有一本能提供指导的书籍或者教程,一步步跟着做下去,直到真正掌握。
一般讲述CUDA的书,我认为不错的有下面这几本:

初学者可以先看美国人写的这本《GPU高性能编程CUDA实战》,可操作性很强,但不要期望能全看懂(Ps:里面有些概念其实我现在还是不怎么懂),但不影响你进一步学习。如果想更全面地学习CUDA,《GPGPU编程技术》比较客观详细地介绍了通用GPU编程的策略,看过这本书,可以对显卡有更深入的了解,揭开GPU的神秘面纱。后面《OpenGL编程指南》完全是为了体验图形交互带来的乐趣,可以有选择地看;《GPU高性能运算之CUDA》这本是师兄给的,适合快速查询(感觉是将官方编程手册翻译了一遍)一些关键技术和概念。
有了这些指导材料还不够,我们在做项目的时候,遇到的问题在这些书上肯定找不到,所以还需要有下面这些利器:

这里面有很多工具的使用手册,如CUDA_GDB,Nsight,CUDA_Profiler等,方便调试程序;还有一些有用的库,如CUFFT是专门用来做快速傅里叶变换的,CUBLAS是专用于线性代数(矩阵、向量计算)的,CUSPASE是专用于稀疏矩阵表示和计算的库。这些库的使用可以降低我们设计算法的难度,提高开发效率。另外还有些入门教程也是值得一读的,你会对NVCC编译器有更近距离的接触。
好了,前言就这么多,本博主计划按如下顺序来讲述CUDA:
1.了解设备
2.线程并行
3.块并行
4.流并行
5.线程通信
6.线程通信实例:规约
7.存储模型
8.常数内存
9.纹理内存
10.主机页锁定内存
11.图形互操作
12.优化准则
13.CUDA与MATLAB接口
14.CUDA与MFC接口