Oracle 数据库基础
数据库:
oraclgez连接方式:
SQL*Plus
PL/SQL Developer
oracle数据类型:
oracle数据类型共有
四种:
字符数据类型;
数值数据类型;
日期数据类型;
lob数据类型;
字符数据类型:
char 存储固定长度的数据类型
varchar2 存储可变数据类型的字符串
nchar
和
nvarchar2
存储unicode字符集数据类型
数值数据类型:
number 整形和浮点型 格式: NUMBER(p,s)
p表示有效位数,从左往右第一个不为0的数开始,
s表示小数点后面的位数。
例如:
将0.01存入 number(3,4) 小数点后面应该有4位,那么这个数就是0.0100,有效位数应该是3位,从左往右不为0,1开始,共有3位刚好,正确。
日期时间数据类型:
date 存储日期和时间的数据类型 每个字节存储 世纪,年,月,日,小时,分,秒。
oracle中的
sysdate函数的功能就是返回当前的日期和时间。
timestamp 存储日期的数据类型 和上面一样,唯一的区别是此数据类型其中
秒值精确到小数点后6位,该数据类型同时包含时区信息,
systimestamp函数的功能就是返回当前日期,时间和时区。
LOB数据类型:(大对象)
1
clob(character lob 字符lob)
存储大量字符数据,非结构化,xml文档,新闻,内容介绍等大量含文字内容的文档。
2
blob(binary lob,二进制lob)
可以存储较大的二进制对象,如图形,视频剪辑和声音剪辑等。
3
bfile(binary file,二进制文件)
能够将二进制文件存储在数据库外部操作系统文件中。bfile有个定位器,指向服务器文件系统上的二进制文件,最大为4GB.
4
nclob
如1
不建议使用varchar integer float ,double等类型
oracle中的伪列:(2个,唯一)
ROWID
可以以最快的方式访问表中的一行。
能显示表的行是如何存储的。
可以作为表中行的唯一标识。 select rowid,ename,from scott.emp where ename='smith';
ROWNUM
对于一个额查询返回的每一行,rownm伪列返回一个数值代表行的次序。第一行为1
查询第一行可以 where rownum =1 但是第二行不可以,<3可以如果只想要第二条:
select * from (select * from emp ) s where s.rownum =? ;
SQL 语言简介:
数据定义语言 数据操纵语言 事务控制语言 数据控制语言
数据定义语言 数据操纵语言 事务控制语言 数据控制语言
数据定义语言 ddl data define language
定义
definition; delimiting; define; circumscription; definiens
创建表:

--------------------------------------------
表名:
首字母应该为字母
不能使用oracle保留字作为表名
最大长度为30个字符
同一个模式不同的表应该有不同的名字
可以使用下划线,数字和字母,但不能使用空格和单引号。
添加约束:

添加/删除列:

修改列的定义:modify

删除表:
drop table tablename;
truncate table tablename;
数据操纵语言 data control language
1 语法
增删查改功能
查询:
distinct 选择无重复的行:将查询结果中所有重复的行只保留一行
列别名: select ename as '名 称',eage '年 龄',sal 薪水 from emp;
可以省略 as用空格代替,但是如果别名中间有空格,as也可以用空格代替只是这个别名需要用''包括起来。
利用现有表创建新表
create table newtable as select * from emp;
可以复制全部,或者部分列,或者部分内容,或者无数据复制
无数据:
create table newtable as select * from emp where 1=2;
2 技巧
查看表中行数:
select count(*) from emp;
select count(1) from emp;
前后者唯一区别:后者节省性能。
取出stuName,stuAge列不存在重复数据的记录


分组=>筛选
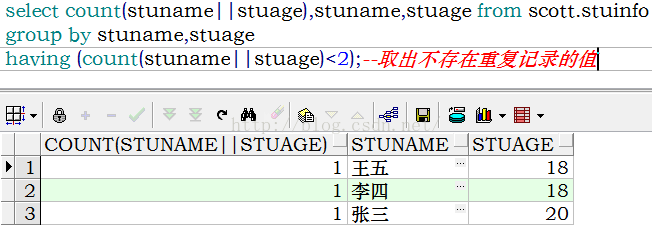
select stuName, stuAge from stuInfo
group by stuName,stuAge
HAVING(count(stuName||stuAge)<2);
“||”操作符为连接操作符,因为count函数只能有一个参数所以用连接操作符来连接。
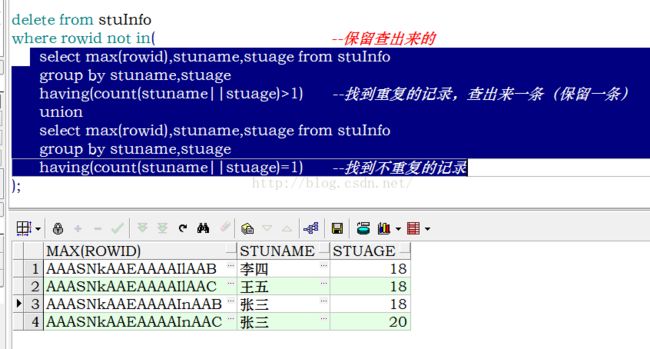
删除stuName,stuAge列重复的行(保留一行)
删除姓名和年龄都重复的数据,并且只保留一行: 将重复的查询,选一条,再将不重复的查询出来,再将两者放在一起,那么这就是想要的结果,现在就可以将除了这个结果外的给删掉,即可。★
查看当前用户所有数据量>100万的表的信息
select table_name from user_all_tables a where a.num_rows>100000;
事务控制语言 tran control language
tcl由以下部分组成
commit 提交事务,即把事务中对数据库的修改进行永久保存。
rollback 回滚事务,即取消对数据库所做的任何修改。
savepoint 在事务中创建存储点。
rollback to 将事务回滚到存储点。
insert a; insert b; savepoint first; insert c;
rollback to savepoint first; --此时有ab,没有c(保存点后回滚)
rollback; --此时没有abc(事务没有结束,事务结束必须以commit或rollback)
数据控制语言 data control language
数据控制语言为用户提供权限控制命令。
SQL操作符:
算数操作符 计算: + - * / 数据类型需要是number
比较操作符
比较:= != < > <= >= between'''and''' in like is null
逻辑操作符
组合/真假 and or not
集合操作符
将两个查询结果组合成一个结果集。
union(联合) 将两个查询结果放到一起,删除重复的行
union(联合所有) 将两个查询结果放在一起重复的也不例外
intersect(交集) 将两个查询结果相同的显示出来
minus(减集) 将两个结果中减去第二个select语句中公共的内容。
sqlserver 不支持后两个,用exists 也可以实现这种操作。
连接操作符
“||” 将一个字符串和字符串拼接成一个字符串,或者将字符串和数值拼接在一起。
example:
select job||'_'||ename from employee;
SQL函数
1 转换函数
TO_CHAR(1234.5,'$9999.9'
) =>
字符串类型
$1234.,5
TO_DATE('1980-01-01','yyyy-mm-dd') =>日期类型 01-1 月-80 fm:去掉0
TO_NUMBER('1234.5') =>数值类型 1234.5 一般会隐式转换
2 其它函数(单行函数)
NVL(exp1,exp2)如果1是null,则返回2的值
NVL2(exp1,exp2,exp3)如果1是null,返回3,否则2
DECODE(value,if1,then1,if2,then2,else )
3 分析函数(分组后遇到相同的数)
select ename,deptno,sal,
rank() over (partition by deptno order by sal desc) "RANK"
from employee;
分组后遇到相同的数的情况:
ROW_NUMBER
123 123
DENSE_RANK
112 122
RANK
113 1335
qq1843620566 欢迎交流
qq1843620566 欢迎交流