Python多线程下载图片
文章目录
- 导包
- 模拟浏览器登录参数
- 一:单线程爬取
- 1.生成网页列表
- 2.爬取图片的网址
- 3.下载图片到本地
- 二:多线程下载图片
- 0.加锁
- 1.获取图片网址
- 2.下载图片
- 3.函数调用
- 4.问题
- 完整代码
导包
import re
import os
import urllib.request
import threading
模拟浏览器登录参数

headers ={
"Referer": "https://www.doutula.com/photo/list/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
}
一:单线程爬取
1.生成网页列表
我们以爬取斗图啦网页图片为例:
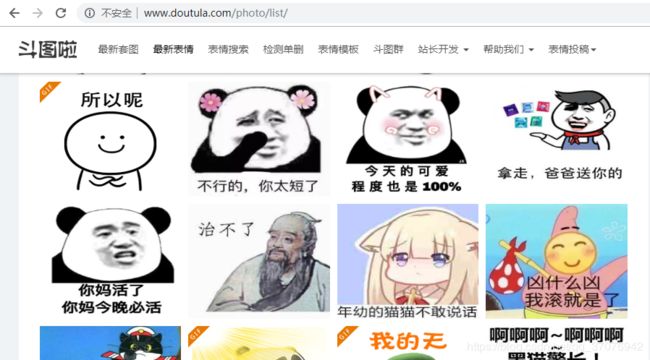
点击最新图片,就会就会显示每一页所有图片,通过观察每一页的网址我们可以找出规律
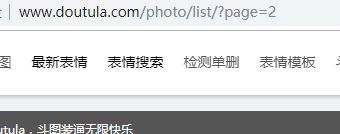
所以可以将每一页的网址都存入一个列表里,方便爬取时使用
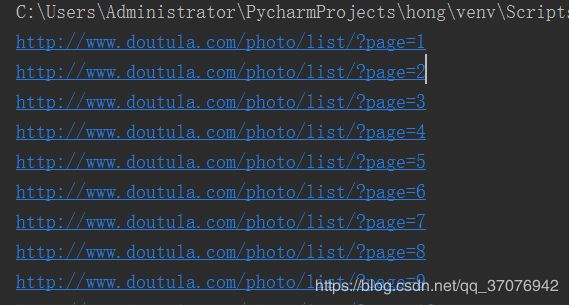
我们先以20页为例
url_list = []
http = "http://www.doutula.com/photo/list/?page="
for i in range(1,20):
url = http+str(i)
url_list.append(url)
for url in url_list:
print(url)
2.爬取图片的网址
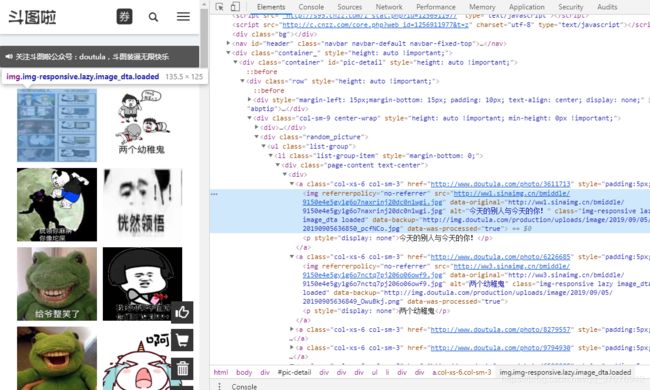
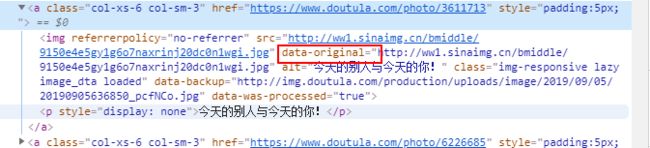
我们要获取的是上图标注的东西
for url in url_list:
res = urllib.request.Request(url,headers=headers)
res2 = urllib.request.urlopen(res).read().decode("UTF-8")
result = re.findall(re.compile(r'![]()
3.下载图片到本地
定义下载函数
#定义下载函数
def download_picture(url):
#修改文件名
split_list = url.split("/")
filename = split_list.pop()
path = os.path.join("doutu",filename) #文件夹要自己新建,不然会报错
#下载图片,保存本地
urllib.request.urlretrieve(url,filename=path)
调用函数
for url in url_list:
res = urllib.request.Request(url,headers=headers)
res2 = urllib.request.urlopen(res).read().decode("UTF-8")
result = re.findall(re.compile(r'![]()
二:多线程下载图片
多线程模式下可以很清楚的看到下载图片的快速
0.加锁
多线程在运行时,会出现同时访问某元素的情况,为避免数据变动后出现错误,需要在取数据的前后进行加锁与解锁
glock = threading.Lock()
1.获取图片网址
新建列表用来存储图片网址
pic_list = []
封装获取图片网址的函数
#生产者:源源不断产生图片网址并存入列表
def get_pic_url():
while True:
glock.acquire()
if len(url_list) == 0:
glock.release()
break
else:
page_url = url_list.pop()
glock.release()
res = urllib.request.Request(page_url,headers=headers)
res2 = urllib.request.urlopen(res).read().decode("UTF-8")
result = re.findall(re.compile(r'![]()
2.下载图片
封装下载函数
#消费者:从存储图片网址的列表中拿出网址,进行下载
def download_picture():
while True:
glock.acquire()
if len(pic_list) ==0:
glock.release()
continue
else:
url = pic_list.pop()
glock.release()
#修改文件名
split_list = url.split("/")
filename = split_list.pop()
path = os.path.join("doutu",filename)
#下载图片,保存本地
urllib.request.urlretrieve(url,filename=path)
3.函数调用
def main():
#创建两个线程作为生产者
for x in range(2):
product = threading.Thread(target=get_pic_url)
product.start()
#创建三个线程作为消费者
for x in range(3):
consumer = threading.Thread(target=download_picture)
consumer.start()
if __name__ == '__main__':
main()
代码运行没有出错,速度飞快
可以用时间函数计时
import time
if __name__ == '__main__':
d = time.time()
main()
d = time.time()-d
print(d)

4.问题
代码虽然可以多线程运行,但也出现不停止的情况,所以在条件判断的地方还要优化改进
完整代码
#coding: utf-8
import re
import os
import urllib.request
import threading
headers ={
"Referer": "https://www.doutula.com/photo/list/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
}
url_list = []
pic_list = []
glock = threading.Lock()
http = "http://www.doutula.com/photo/list/?page="
for i in range(1,10):
url = http+str(i)
url_list.append(url)
# for url in url_list:
# print(url)
#生产者:源源不断产生图片网址并存入列表
def get_pic_url():
while True:
glock.acquire()
if len(url_list) == 0:
glock.release()
break
else:
page_url = url_list.pop()
glock.release()
res = urllib.request.Request(page_url,headers=headers)
res2 = urllib.request.urlopen(res).read().decode("UTF-8")
result = re.findall(re.compile(r'![]()