Hadoop学习笔记2
Hadoop学习笔记2
- 3 Hadoop集群搭建
- 3.1 创建第一台虚拟机
- 3.1.1 网络配置
- 3.1.2 Hosts文件设置
- 3.1.3 安装JDK
- 3.2 克隆虚拟系统
- 3.3 配置免密登录
- 3.3.1免密登录机制
- 3.3.2 Master主机生成密钥
- 3.3.3 Master主机发送数据
- 3.4 安装Hadoop
- 3.4.1下载Hadoop安装包
- 3.4.2 上传Hadoop安装包
- 3.4.3 解压Hadoop安装包
- 3.4.4 创建Hadoop安装目录的软链接
- 3.4.5 Hadoop目录结构介绍
- 3.4.5.1 etc目录
- 3.4.5.2 sbin目录
- 3.4.5.3 bin目录
- 3.4.5.4 share目录
- 3.4.5.5 libexec目录
- 3.4.5.6 include与lib目录
- 3.4.5.7 src目录
- 3.5 修改配置文件
- 3.5.1 修改/etc/profile文件
- 3.5.2 修改hadoop配置文件
- 3.5.2.1 core-site.xml
- 3.5.2.2 hadoop-env.sh
- 3.5.2.3 hdfs-site.xml
- 3.5.2.4 mapred-site.xml
- 3.5.2.5 yarn-site.xml
- 3.5.2.6 slaves
- 3.5.3 格式化NameNode
- 3.5.4 集群节点间复制hadoop目录
- 3.5.5 关闭防火墙
- 3.5.6 搭建成功测试
- 3.5.6.1 单独启动/停止HDFS
- 3.5.6.2 单独启动/停止Yarn
- 3.5.6.2 启动/停止整个集群
3 Hadoop集群搭建
3.1 创建第一台虚拟机
3.1.1 网络配置
CentOS6.10 Mini版默认是没有生成主机IP的,需要手工配置。
(1)动态生成IP
Step1:修改/etc/sysconfig/network-scripts/ifcfg-eth0文件,将ONBOOT的值修改为yes。
Step2:修改完毕后,重启网络服务:service network restart。
(2)指定静态IP
Step1:查看默认网关地址
Step2:修改网关地址为1号地址。当然,可以不修改。
Step3:修改/etc/sysconfig/network-scripts/ifcfg-eth0文件:
ONBOOT=yes
IPADDR=指定的IP(要与网关在同一网段)
NETMASK=255.255.255.0
GATEWAY=查看的网关
Step4:重启网络服务:service network restart
注意这里使用的是MINI最小化安装
https://mirrors.aliyun.com/centos/6.10/isos/x86_64/
3.1.2 Hosts文件设置
Hosts文件的作用是相当于本地的DNS服务器,将IP与主机名作一对一映射。
1)Linux系统中设置hosts文件修改/etc/hosts文件,在文件最后添加IP与主机名的对应关系:
192.168.64.11 node01
192.168.64.22 node02
192.168.64.33 node03
- Windows系统中设置hosts文件
修改C:\Windows\System32\drivers\etc\hosts文件,在最后添加如下内容:
192.168.64.11 node01
192.168.64.22 node02
192.168.64.33 node03
3.1.3 安装JDK
Step1:创建目录。在/usr下创建tools与apps目录。其中/usr/tools目录用于存放安装包,软件均安装到/usr/apps目录。
Step2:上传安装包到/usr/tools目录
Step3:解压JDK安装包到/usr/apps目录。
tar –zxvf /usr/tools/jdk1.8.0_144 -C /usr/apps
Step4:创建软链接。软链接就是一个别名,相当于Windows中的快捷方式。
ln –s /usr/apps/jdk1.8.0_144 /usr/apps/jdk
Step5:修改/etc/profile文件。在最后添加如下内容:
export JAVA_HOME=/usr/apps/jdk
export PATH=$JAVA_HOME/bin:$PATH
保存修改后,执行source命令
source /etc/profile
3.2 克隆虚拟系统
Step1:克隆虚拟机
Step2:修改主机名。修改/etc/sysconfig/network文件中的HOSTNAME后,重启系统
Step3:修改网卡。网卡信息在/etc/udev/rules.d/70-persistent-net.rules文件中。克隆来的系统中默认具有两块儿网卡,其中第一块的MAC地址与克隆源主机的网卡MAC相同,需要将其删除,保留第二块网卡。但要记下第二块网卡的MAC地址,后面要使用。还需要将第二块网卡的name修改为eth0。
Step4:修改网卡的MAC地址。克隆来的系统中默认的网卡MAC地址与克隆源的相同,现在要修改为上面第二块网卡的MAC。打开/etc/sysconfig/network-scripts/ifcfg-eth0文件,修改HWADDR的值为第二块MAC的址。
Step5:修改静态IP。若克隆源采用的是动态IP,那么无需修改IP,因为克隆系统也采用的是动态IP,系统在启动时会自动生成一个动态的IP。若克隆源采用的是静态IP,那么,克隆系统中默认的静态IP与克隆源的是相同的,需要修改/etc/sysconfig/network-scripts/ifcfg-eth0文件中的IPADDR即可。
Step6:重启系统
注意:克隆的时候需要关机
3.3 配置免密登录
3.3.1免密登录机制
1)公钥与私钥
1、公钥与私钥加密是一种“不对称加密方式”,是对传统的“对称加密方式”的功能增强。
2、公钥与私钥是成对出现的,即一个公钥对应一个私钥。
3、使用公钥加密后,只能使用其对应的私钥解密。它们的关系类似于“锁与钥匙”的关系。公钥相当于“锁”,是公开的,是要发送给别人的;私钥相当于“钥匙”,是私有的,不能公开的,只能由公钥的发出者保存
2)免密登录原理
免密登录机制由两部分构成:免密构建与免密验证。

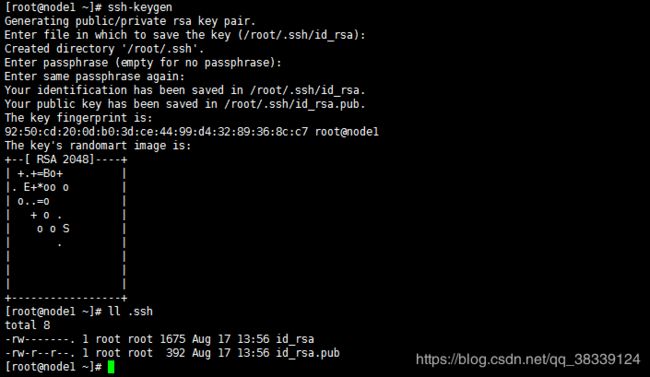
3.3.2 Master主机生成密钥
Master主机使用ssh-keygen命令可以生成密钥。默认保存在~/.ssh目录中。其中id_rsa文件为私钥文件,id_rsa.pub为公钥文件。
ssh-keygen
3.3.3 Master主机发送数据
Master主机使用“ssh-copy-id 从机”命令可以将包含公钥与用户信息的数据发送给指定从机。指定从机会将数据保存到~/.ssh/authorized_keys文件中。需要注意,node1也要向自己创建免密登录,因为我们的集群中node1同时作为Master与Slave出现。
ssh-copy-id


3.4 安装Hadoop
3.4.1下载Hadoop安装包
可以从Hadoop官网下载安装包及源码包。http://hadoop.apache.org
3.4.2 上传Hadoop安装包
将Hadoop安装包上传到node1的/usr/tools中。
3.4.3 解压Hadoop安装包
将/usr/tools中的安装包解压到/usr/apps中。
tar -zxvf /usr/tools/hadoop-2.7.4.tar.gz -C /usr/apps
3.4.4 创建Hadoop安装目录的软链接
ln -s /usr/apps/hadoop-2.7.4/ /usr/apps/hadoop
3.4.5 Hadoop目录结构介绍
3.4.5.1 etc目录
该目录中只包含一个子目录hadoop,其中存放着Hadoop的重要配置文件。xxx-env.sh是运行环境配置文件,xxx-site.xml是设置配置文件。
3.4.5.2 sbin目录
sbin,super binary,只有root用户才可访问的目录。该目录中存放着大量的重要命令,命令即脚本。其中重要的命令有:
1、hadoop-daemon.sh:用于启动/停止指定的进程,namenode、secondarynamenode、datanode
hadoop-daemon.sh start namenode:启动了namenode进程
hadoop-daemon.sh stop namenode:启动了namenode进程
2、yarn-daemon.sh:用于启动/停止指定的进程,resourcemanager与nodemanager
3、start-all.sh:用于启动整个Hadoop集群
4、start-dfs.sh:用于启动HDFS框架
5、start-yarn.sh:用于启动Yarn框架
6、stop-all.sh:用于停止整个Hadoop集群
7、stop-dfs.sh:用于停止HDFS框架
8、stop-yarn.sh:用于停止Yarn框架
3.4.5.3 bin目录
其中也存放着很多重要的命令(脚本)。sbin目录中的命令的实际功能实现者其实是bin目录中的这些命令。即sbin目录中的命令实际调用了bin目录中的命令。
3.4.5.4 share目录
该目录中包含两个子目录,一个是doc,存放着hadoop的文档,一般会删除;另一个是hadoop目录,存放着hadoop各个模块编译后的jar包,是hadoop运行的真正程序所在。
3.4.5.5 libexec目录
存放着Hadoop的shell程序所依赖的shell配置文件。
3.4.5.6 include与lib目录
这两个目录都是为使用C++开发Hadoop应用所提供的头文件与动态链接库文件。注意,Linux系统中的动态链接库文件为.so文件,类似于Windows中的.dll文件。
3.4.5.7 src目录
Hadoop的源码目录
3.5 修改配置文件
3.5.1 修改/etc/profile文件
将hadoop的安装目录下的bin与sbin目录注册到系统环境变量PATH中,即修改/etc/profile文件。修改完毕后,需source一下,将修改后的文件重新加载。
由于后边修改的配置文件较多,所以此处使用Editplus软件远程连接Linux服务器进行配置文件的修改。

export HADOOP_HOME=/usr/apps/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
3.5.2 修改hadoop配置文件
注意hadoop配置文件中不要出现中文注释
3.5.2.1 core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://node1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/data/hadoopvalue>
property>
configuration>
3.5.2.2 hadoop-env.sh
修改第25行为:
export JAVA_HOME=/usr/apps/jdk
3.5.2.3 hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.secondary.http.addressname>
<value>node2:50090value>
property>
configuration>
3.5.2.4 mapred-site.xml
首先将hadoop安装目录下的/etc/hadoop中的mapred-site.xml.template文件重命名为mapred-site.xml后,再修改。
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
3.5.2.5 yarn-site.xml
一般将yarn作为一台独立的主机,或者将yarn和namenode放在一台机器上
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>node1value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
3.5.2.6 slaves
node1
node2
node3
注意这里node1既是namenode 又是datanode还是ResourceManage
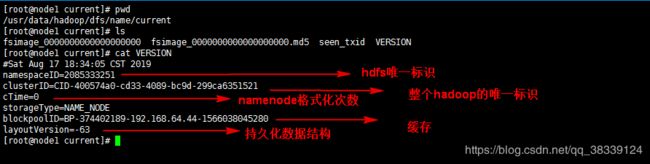
3.5.3 格式化NameNode
式化命令:
hadoop namenode -format

格式化后,会根据core-site.xml生成/usr/data/hadoop/dfs/name/current/目录,其中包含四个文件:1、fsimage:文件系统镜像,存放当前文件系统的状态,即元数据信息
2、md5:是同名fsimage文件的校验文件
3、seen_txid:这个文件的数字和faimage的文件名后缀数字做对比,用来判断image文件是否丢失,数字会随着namenode的重启次数发生变化
4、VERSION:记录当前NameNode的版本信息。
尝试启动namenode
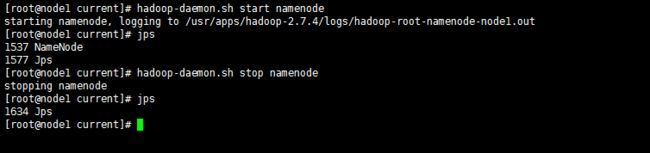
hadoop-daemon.sh start namenode
hadoop-daemon.sh stop namenode
3.5.4 集群节点间复制hadoop目录
集群中每一台节点机中都要有与node1中相同的hadoop目录及配置,这样集群才可协调工作。所以需要将node1中的hadoop目录复制到node2与node3。复制到node2命令:
scp –r /usr/apps/hadoop-2.7.4 node2:/usr/apps
复制完毕后,需要为该hadoop-2.7.4目录创建软链接
ln –s /usr/apps/hadoop-2.7.4 /usr/apps/hadoop
3.5.5 关闭防火墙
Linux系统默认开放的只有22端口号,但Hadoop在运行时,主机间访问需要用到很多其它的端口号,所以我们需要将防火墙关闭,以放开所有端口。关闭防火墙可以使用service iptables stop命令,但其为临时关闭,一旦系统重启,防火墙会自动开启。所以我们一般使用永久关闭命令:
chkconfig iptables off
另外,在Linux的根目录下还有一个目录selinux,即Security Enhanced Linux,是Linux中的一个安全增强子系统,其功能类似于一个防火墙,其也要关闭。集群中的每一台主机都要将它们关闭。可将所有主机上的防火墙及selinux关闭。
chkconfig iptables off && setenforce 0

3.5.6 搭建成功测试
在此Hadoop集群环境已经搭建完毕,可以启动集群了。但需要注意,只能在node1上启动集群。因为只有node1上配置了免密登录,可以免密访问node2与node3,但反之不行。另外,node2与node3中的hadoop的bin与sbin目录没有注册到系统环境变量PATH中。
3.5.6.1 单独启动/停止HDFS
启动:
start-dfs.sh
停止:
stop-dfs.sh
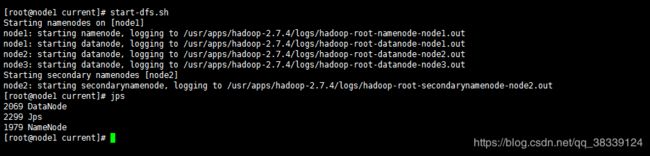
注意:node1既是namenode,也是datanode

注意:node2既是datanode,也是SecondaryNameNode

注意:node3仅仅是datanode
停止:
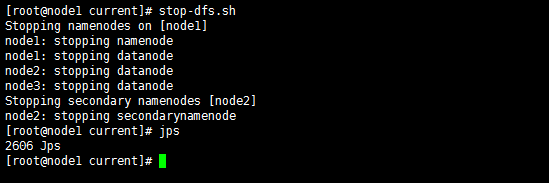


3.5.6.2 单独启动/停止Yarn
启动:
start-yarn.sh
停止:
stop-yarn.sh

注意:node1既是ResourceManage,也是NodeManage

注意:node2是NodeManage

注意:node3是NodeManage
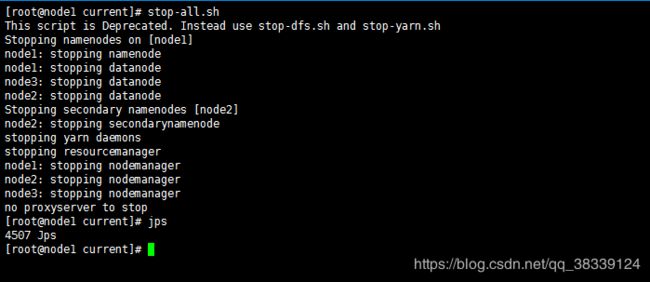
3.5.6.2 启动/停止整个集群
两种方式:
第一种(推荐):分别启动HDFS与Yarn,分别停止HDFS与Yarn。
第二种(不推荐):
启动:start-all.sh
停止:stop-all.sh



停止