JAVA 并发编程(一)基础
java并发编程基础
- JAVA 并发编程-基础
- 基本概念
- 并发问题的背景
- CPU多级缓存
- CPU高速缓存
- 缓存一致性 (MESI)
- 状态变更图
- 乱序执行优化
- JAVA 内存模型 (Java Memory Model,JMM)
- JAVA 内存模型的规范
- JAVA内存模型图示
- 计算机硬件架构的简单图示
- JAVA内存模型与硬件架构之间的关联
- Java 内存模型抽象结构图
- java内存模型同步规则
- 并发的优势和风险
- 优势
- 劣势
JAVA 并发编程-基础
基本概念
- 并发 : 同时拥有两个或者多个线程,如果程序在单核处理器上运行,多个线程将交替地换人或者换出内存,这些线程是同时 “存在“ 的,每个线程都处于执行过程中的某个状态,如果运行在多核处理器上,此时,程序中的每个线程都将分配到一个处理器核上,因此,可以同时进行
- 高并发 : 是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求
并发问题的背景
这些年,我们的CPU、内存、I/O设备都在不断迭代,不断朝着更快的方向努力。但是,在这个快速发展的过程中,有一个核心矛盾一直存在,就是这三者的速度差异。CPU和内存的速度差异可以形象地描述为:CPU是天上一天,内存是地上一年(假设CPU执行一条普通指令需要一天,那么CPU读写内存得等待一年的时间)。内存和I/O设备的速度差异就更大了,内存是天上一天,I/O设备是地上十年。
程序里大部分语句都要访问内存,有些还要访问I/O,根据木桶理论(一只水桶能装多少水取决于它最短的那块木板),程序整体的性能取决于最慢的操作——读写I/O设备,也就是说单方面提高CPU性能是无效的
为了合理利用CPU的高性能,平衡这三者的速度差异,计算机体系机构、操作系统、编译程序都做出了贡献,主要体现为:
- CPU增加了缓存,以均衡与内存的速度差异;
- 操作系统增加了进程、线程,以分时复用CPU,进而均衡CPU与I/O设备的速度差异;
- 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用。
CPU多级缓存

多级缓存的演变过程
数据的读取和存储都经过高速缓存,CPU核心与高速缓存有一条特殊的快速通道。主存与高速缓存都是连接在系统总线上(Bus),这条总线同时还用于其他组件的通信。由于高速缓存与主存之间的速度差异被拉大,使得系统变得愈加复杂,所以引入了二级缓存甚至有些系统拥有三级缓存
CPU高速缓存
CPU高速缓存是用于减少处理器访问内存所需的平均时间的组件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处 理器的频率。
CPU缓存的意义 : CPU 的频率太快了,快到主存跟不上,这样在处理器时钟周期内,CPU常常需要等待主存,浪费资源。 所以cache 的出现,是为了缓解 CPU 和内存之间速度的不匹配问题 结构:cpu-> cache-> memory).
缓存出现的原理 :
- 时间局部性 : 如果某个数据被访问,那么在不久的将来它很可能再次被访问
- 空间局部性 : 如果某个数据被访问,那么与它相邻的数据很快也可能被访问
缓存一致性 (MESI)
用于保证多个CPU cache 之间共享数据的一致
- M: Modified 修改,指的是该缓存行只被缓存在该cpu的缓存中,并且使被修改过的,因此他与主存中的数据是不一致的,该缓存行中的数据需要在未来的某个时间点(允许其他CPU 读取主存相应中的内容之前) 写会主存,然后状态变为E(独享)
- E: Exclusive 独享 缓存行只被缓存在该CPU 的缓存中,是未被修改过的,与主存的数据是一致的,可以在任何时刻当有其他CPU 读取改内存时,变成 S (共享)状态,当CPU 修改该缓存行的内容时,变成M(被修改) 的状态
- S: Share 共享 : 意味着该缓存行的数据可能会被多个CPU 进行缓存,并且缓存中的数据与主存中的数据是一致的,当有一个CPU 修改该缓存行是,其他CPU 是可以被作废的,变成I (无效的)
- I : Invaild 无效的,代表这个缓存是无效的,可能是有其他CPU 修改了该缓存行
在一个典型的操作系统中,可能会有几个缓存(在多核系统中,每个核心都会有自己的缓存) 共享缓存主线,每个相应的 CPU 会发出读写请求,而缓存的目的是为了减少 CPU 读写 共享主存的次数。
一个缓存除在 Invalid 状态外 都可以满足cpu的读请求,一个 Invalid 的缓存行必须从主存中读取 (变成s 或者 E状态) 来满足该cpu 的读请求
一个写请求 只有在该缓存行是M或者E状态时 才能被执行,如果缓存行处于S 状态,必须先将其他缓存中该缓存行变成Invalid 状态(也就是不允许不同cpu 同时修改同一缓存行,即使修改该缓存行中不同位置的数据也不允许)。该操作经常作用广播的方式来完成。
缓存可以随时将一个非M 状态的缓存行 作废,或者变成 Invalid 状态,而一个 M 状态的缓存行必须先被写回主存。
一个处于 M 状态的缓存行必须时刻监听其他缓存使改缓存行无效或者独享改缓存行的请求,并将该缓存变成无效 (Invalid)
一个处于 E 状态的缓存行也必须监听其他缓存读主存中该缓存行的操作,一旦有这种操作,该缓存行需要变成 S 状态
对于 M 和 E 状态而言 总数精确的,他们和该缓存行真是状态是一致的,而 S 状态 可能是非一致的,如果一个缓存将处于 S 状态的缓存行作废了,而另一个缓存实际上可能已经独享了该缓存行,但是该缓存却不会将该缓存行升迁为E状态,这是因为其它缓存不会广播他们作废掉该缓存行的通知,同样由于缓存并没有保存该缓存行的copy的数量,因此(即使有这种通知)也没有办法确定自己是否已经独享了该缓存行。
状态变更图

触发事件
| 触发事件 | 描述 |
|---|---|
| 本地读取(Local read) | 本地cache 读取本地cache数据 |
| 本地写入(Local write) | 本地cache 写入cache数据 |
| 远端读取(Remote read) | 其他cache 读取本地cache数据 |
| 远端写入(Remote write) | 其他cache 写入本地cache数据 |
Cache 分类
前提:所有的cache 共同缓存了主内存中的某一条数据
- 本地 Cache : 指当前cpu的 Cache
- 触发 Cache: 触发读写事件的 Cache
- 其他 Cahce:指除了以上两种之外的 Cache
备注:本地的事件触发 本地 Cache 和触发 Cache 为相同
| 状态 | 触发本地读取 | 触发本地写入 | 触发远端读取 | 触发远端写入 |
|---|---|---|---|---|
| M | 本地 cache : M 其他 Cache : I |
本地 cache : M 其他 Cache : I |
本地 cache : M ->E->S 触发 Cache : I->S 其他 Cache : I->S 当其他 Cache 读取该缓存行时,首先同步主存 其次修改为 E 独享 最后 同步修改 所有缓存了该缓存行的 CPU Cache 为 S状态 |
本地 cache : M->E->S->I 触发 Cache : I->S->E->M 其他 Cache : I -> S ->I 同步和读取一样,同步完成后触发cache改为M,本地、其他cache改为I |
| E | 本地 cache : E 其他 Cache : I |
本地 cache : E->M 其他 Cache : I |
本地 Cache :E->S 触发 Cache I->S 其他 Cache I->S |
本地 Cache :E->S->I 触发 Cache I->S->M 其他 Cache I->S->I 当触发cache修改本地cache独享数据时时,将本地、触发、其他cache修改为S共享.然后触发cache修改为独享,其他、本地cache修改为I(无效),触发cache再修改为M |
| S | 本地 cache : S 其他 Cache : S |
本地 Cache : S->E->M 其他 Cache : S->I |
本地 Cache :S 触发 Cache:S 其他 Cache :S |
本地 Cache :S->I 触发 Cache:S->E->I 其他 Cache :S->I 当触发cache要修改本地共享数据时,触发cache修改为E(独享),本地、其他cache修改为I(无效),触发cache再次修改为M(修改) |
| I | 本地 cache I->S(其他 Cache 有该缓存行的值 ) 或者 I->E (其他 Cache 没有改缓存行的值) 其他 Cache : E、M、I ->S 或者 I |
本地 cache : I->S->E->M 其他 Cache : M、E、S->S->I |
既然是本cache是I,其他cache操作与它无关 | 既然是本cache是I,其他cache操作与它无关 |
当一个cache line的调整的状态的时候,另外一个cache line 需要调整的状态。
| M | E | S | I | |
|---|---|---|---|---|
| M | × | × | × | √ |
| E | × | × | × | √ |
| S | × | × | √ | √ |
| I | × | √ | √ | √ |
例如:
cache 1 有一个变量 X = 0 的 cache line 处于 s 状态,那么其他拥有x变量的cache 2,chahe 3 等 x的cache line 调整为s状态 或者调整为 I 状态
乱序执行优化
处理器为提高运算速度而做出违背代码原有顺序的优化
java 双重检查 创建单例对象
public class Singleton {
static Singleton instance;
static Singleton getInstance(){
if (instance == null) {
synchronized(Singleton.class) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}
编译优化之前new 操作 执行的步骤
- 分配一块内存 M;
- 在内存M上初始化Singleton 对象
- 然后M的地址赋值给 instance 变量
优化之后的步骤
- 分配一块内存M;
- 将M的地址赋值给instance变量;
- 最后在内存M上初始化Singleton对象
我们假设线程A先执行getInstance()方法,当执行完指令2时恰好发生了线程切换,切换到了线程B上;如果此时线程B也执行getInstance()方法,那么线程B在执行第一个判断时会发现 instance != null ,所以直接返回instance,而此时的instance是没有初始化过的,如果我们这个时候访问 instance 的成员变量就可能触发空指针异常。

JAVA 内存模型 (Java Memory Model,JMM)
JAVA 内存模型的规范
- 规定了一个线程如何和何时可以看到其他线程修改过后的共享变量的值
- 如何及何时同步的访问共享变量值
JAVA内存模型图示

Heap(堆):Java里的堆是一个运行时的数据区,堆是由垃圾回收来负责的,堆的优势是可以动态的分配内存大小,生存期也不必事先告诉编译器,他是在运行时动态分配内存的,Java的垃圾回收器会定时收走
不用的数据,
缺点:由于要在运行时动态分配,所有存取速度可能会慢一些
Stack(栈):栈的优势是存取速度比堆要快,仅次于计算机里的寄存器,栈的数据是可以共享的,
缺点:是存在栈数据的大小与生存期必须是确定的,缺乏一些灵活性栈中主要存放一些基本类型的
变量,比如:int、short、long、bytedouble、float、boolean、char、对象句柄,
Java内存模型要求调用栈和本地变量存放在线程栈(Thread Stack)上,对象存放在堆上。
一个本地变量可能存放一个对象的引用,这时引用变量存放在本地栈上,但是对象本身存放在堆上
成员变量跟随着对象存放在堆上,而不管是原始类型还是引用类型,静态成员变量跟随着类的定义一起存在在堆上
存在堆上的对象,可以被持有这个对象的引用的线程访问
如果两个线程同时访问同一个对象的私有变量,这时他们所拥有的是这个对象的私有拷贝
计算机硬件架构的简单图示
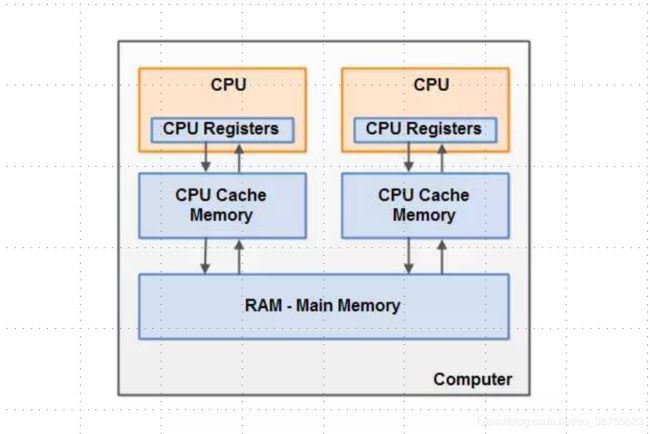
运作原理:通常情况下,当一个CPU要读取主存(RAM - Main Mernory)的时候,他会将主存中的数据读取到CPU缓存中,甚至将缓存内容读到内部寄存器里面,然后再寄存器执行操作,当运行结束后,会
将寄存器中的值刷新回缓存中,并在某个时间点将值刷新回主存
JAVA内存模型与硬件架构之间的关联

(Computer)硬件内存模型是没有区分线程 Stack栈 和 Heap堆,对于硬件而言,所有的栈和堆分
布在主存寸里面,部分栈和堆有时候可能出现在CPU缓存中中和CPU内部的寄存器里面
Java 内存模型抽象结构图

每个线程之间共享变量都存放在主内存里面,每个线程都有一个私有的本地内存
本地内存是Java内存模型中抽象的概念,并不是真实存在的(他涵盖了缓存写缓冲区。寄存器,以及其他硬件的优化)
本地内存中存储了以读或者写共享变量的拷贝的一个副本
从一个更低的层次来说,线程本地内存,他是CPU缓存,寄存器的一个抽象描述,而JVM的静态内存存储模型,
他只是一种对内存模型的物理划分而已,只局限在内存,而且只局限在JVM的内存
如果线程A和线程B要通信,必须经历两个过程:
1、A将本地内存变量刷新到主内存
2、B从主内存中读取变量

状态说明
1.Lock(锁定):作用于主内存的变量,把一个变量标识变为一条线程独占状态
2.Unlock(解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定
3.Read(读取):作用于主内存的变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
4.Load(载入):作用于工作内存的变量,它把Read操作从主内存中得到的变量值放入工作内存的变量副本中
5.Use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎
6.Assign(赋值):作用于工作内存的变量,它把一个从执行引擎接受到的值赋值给工作内存的变量
7.Store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作
8.Write(写入):作用于主内存的变量,它把Store操作从工作内存中一个变量的值传送到主内存的变量中
java内存模型同步规则
1.如果要把一个变量从主内存中赋值到工作内存,就需要按顺序得执行 read 和 load 操作,如果把变量从工作内
存中同步回主内存中,就要按顺序得执行 store 和 write 操作,但 java 内存模型只要求上述操作必须按顺
序执行,没有保证必须是连续执行,也就是说 Read 和 Load 、Store 和 Write之间是可以插入其他指令的
2.不允许 read 和 load 、store 和 write操作之一单独出现
3.不允许一个线程丢弃他的最近 assign 的操作,即变量在工作内存中改变了之后必须同步到主内存中
4.不允许一个线程无原因地(也就是说必须有 assgin 操作)把数据从工作内存同步到主内存中
5.一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化( load 或 assign)的变量。即就是对一个变量实施 use 和 store 操作之前,必须先执行过了 load 和 assign 操作
6.一个变量在同一时刻只允许一条线程对其进行 lock 操作,但 lock 操作可以同时被一条线程重复执行多次,多次执行 lock 后,只有执行相同次数的 unlock 操作,变量才会解锁,lock 和 unlock 必须成对出现
7.如果一个变量执行 lock 操作,将会清空工作内存中此变量的值,在执行引擎中使用这个变量前需要重新执行 load 或 assign 操作初始化变量的值
8.如果一个变量事先没有被 lock 操作锁定,则不允许他执行 unlock 操作,也不允许去 unlock 一个被其他线程锁定的变量
9.对一个变量执行 unlock 操作之前,必须先把此变量同步到主内存中(其实就是执行 store 和 write 操作之后)
并发的优势和风险
优势
- 速度
系统可以同时处理多个请求,等待的时间变短,那么相应的响应更快;
另一方面,复杂的操作可以分成多个进程同时进程;- 设计
- 资源利用
CPU能够在等待IO的时候做一些其他的事情
劣势
- 安全性
多个线程共享数据时可能会产生于期望不相符的结果- 活跃性
某个操作无法继续进行下去时,就会发生活跃性问题。比如死锁、饥饿等问题…- 性能
线程过多时会使得:CPU 频繁切换,调度时间增多;同步机制;消耗过多内存
(当 CPU 调度不同线程时,它需要更新当前执行线程的数据,程序指针,以及下一个线程的相关信息。这种切换会有额外的时间、空间消耗,我们在开发中应该避免频繁的线程切换。
多环境情况下必须使用同步机制,这导致了很多编译器想做的优化被抑制。线程过多还会消耗过多内存)