谷歌 AI 自动编程效率超研发工程师,作为工程师的我感到了森森的压力

TNW一则热门新闻炸开了锅:Google AutoML 系统近日居然自己写了一串机器学习代码,其效率竟然超过了专业的研发工程师。这让我们人类的优越感何存?你们这些机器人学生啊,学习能力不要太强哦
作者 | 周翔
人工智能可谓是目前最热门的行业,与此同时,相关人才的身价也跟着水涨船高。根据拉勾网的数据,2017 年,人工智能招聘领域,2000 人以上大公司平均薪酬 25.2k。
而领英的数据则显示,截至 2017 年一季度,基于领英平台的全球AI领域技术人才数量已经超过 190 万,排名全球第一的美国相关人才总数超 85 万,相较而言,位列第七的中国只有 5 万人左右,缺口巨大。
在高需求和高薪资的双重刺激下,不管是学生物的,还是学材料的,想要转战 AI 的人越来越多,这也从侧面验证了为什么吴恩达等 AI 大牛每次推出新的在线课程都能引发一轮“集体高潮”。
不过,想要转行的同学要抓紧了,AI 既然可以速记员,取代翻译,未来有没有可能取代程序员呢?
5 个月前,谷歌开发出的 AI 自主设计的深度学习模型已经比创造它的工程师还要好了,如今这个 AI 系统又更进一步,在某些复杂任务上的表现也超越了人类工程师。
对此,你怎么看?
在人工智能的浪潮下,深度学习模型已经广泛应用于语音识别、机器翻译、图像识别等诸多领域,并取得了非常不错的成果。但是深度学习模型的设计却是一个艰辛且繁复的过程,因为所有可能组合模型背后的搜索空间非常庞大,比如一个典型的 10 层神经网络就有![]() 种神经网络组合,为了应对这样庞大的数量级,神经网络的设计不仅耗时,而且需要机器学习专家积累大量的先验知识。
种神经网络组合,为了应对这样庞大的数量级,神经网络的设计不仅耗时,而且需要机器学习专家积累大量的先验知识。
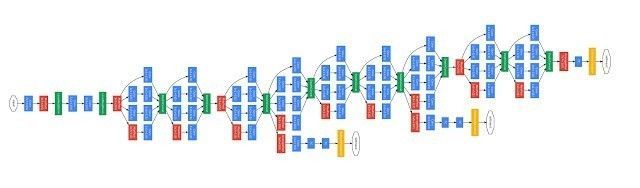
GoogleNet 架构,从最初的卷积架构开始,这种神经网络的设计需要进行多年的细心试验和调试。
在人工智能顶级人才匮乏的情况下,为了让机器学习模型的设计过程更加简单,提升研发效率,谷歌于今年 5 月推出了“AutoML”,顾名思义,AutoML 实际上就是一种让模型设计过程自动化的机器学习软件,该系统会进行数千次模拟来确定代码的哪些方面可以作出改进,并在改变后继续该过程,直到达成目标。
为了测试 AutoML,谷歌将其自行设计的模型用在了专注图像识别的 CIFAR-10 与语言建模的 Penn Treebank 两大数据集上。实验证明,AutoML 设计的模型的性能表现与目前机器学习专家所设计的先进模型不相上下。令人尴尬的是,有些模型甚至还是 AutoML 团队的成员设计的,也就是说,AutoML 在某种程度上超越了自己的缔造者。
5 个月过后,AutoML 又往前迈进了一部。据外媒 TheNextWeb 报导,在某个图像识别任务中,AutoML 设计的模型实现了创纪录的 82% 的准确率。即使在一些复杂的人工智能任务中,其自创建的代码也比人类程序员更好,比如,在为图像标记多个对象的位置这一任务中,它的准确率达到了 42%;作为对比,人类打造的软件只有 39% 。
AutoML 的进展超出了很多人的预期,那么为何机器在设计深度学习模型这一任务上表现的如此出色?先让我们来了解下 AutoML 的工作原理。
AutoML 是如何设计模型的?
作为 AI 领域的领头羊,谷歌其实暗地里做了不少尝试,包括进化算法(evolutionary algorithms)和强化学习算法(reinforcement learning algorithms)等,并且都展现了不错的前景,而 AutoML 则是谷歌大脑团队利用强化学习取得的成果。
在 AutoML 架构中,有一个名为“the controller(控制器)”的 RNN(循环神经网络),它可以设计出一种被称为“child”的模型架构(子模型),而这个“子模型”在训练后可以通过特定任务来进行质量评估。随后,反馈的结果返回到控制器中,以此来帮助提升下一次循环中的训练设定。如下图所示:
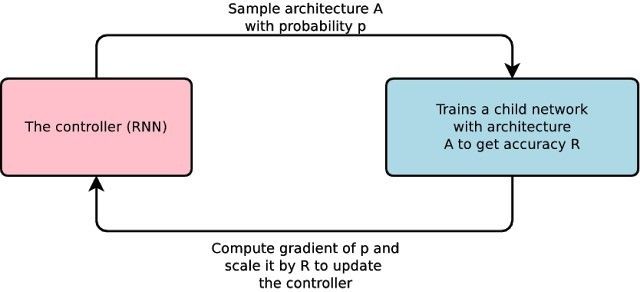
生成新的架构、测试、把反馈传送给控制器以吸取经验——这一过程将重复几千次,最终,控制器会倾向于设计那些在数据集上取得更好的准确性的架构。
AI工程师古筱凡表示,AutoML 的运作过程实际上可以分成以下两部分:
-
元学习的热启动:在机器学习框架中寻找效果好的算法;计算不同数据集之间的相似度,相似的数据可以采取类似的超参数。
-
超参数优化,算法包括:Hyperopt(TPE 算法);SMAC(基于随机森林);Spearmint。输入不同的超参数为,以损失函数为准确率,调优器会在随机选择一些值的基础上,利用贪心算法去寻优。
下图的两个模型是基于 Penn Treebank 数据集设计的预测模型,其中左边是人类专家设计的,右边则是 AutoML 设计的。
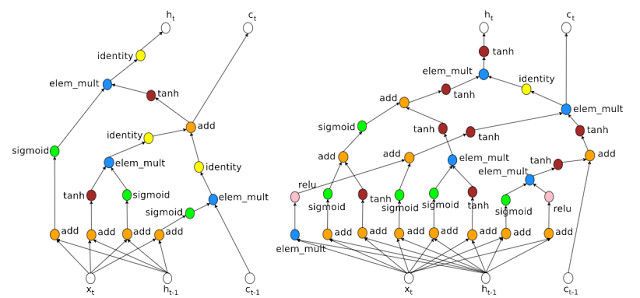
谷歌团队表示,机器自行选择架构的过程其实和人类设计模型架构的过程是有共通之处的,比如两者都采用了合并输入,并借鉴了前向的隐藏层。不过,AutoML 也有一些值得一提的亮点,比如机器选择的架构包含了乘法组合( multiplicative combination),比如上图中 AutoML 设计的模型的最左边的“elem_mult”。对 RNN 而言,出现这种组合的情况并不常见,可能是因为研究人员并没有发现这种组合有什么明显优势。但是有意思的地方在于,近来正好有人提议过这种方法,并认为乘法组合能够有效缓解梯度消失/爆炸的问题。这意味着,机器选择的架构对探索新的神经网络架构有很大的帮助。
此外,这种方法或许还能教会人类:为何某些特定类型神经网络的效果更好?比如上图右边的架构有非常多的 channels,因此梯度可以向后传递,这也解释了为何 LSTM RNNs 的表现比标准 RNNs 的性能更好。
AutoML 开源地址是 https://github.com/automl,感兴趣的读者可以自己动手尝试一下。
AutoML 会取代 AI 工程师吗?
AutoML 能在短时内取得显著进步,证明了用机器设计模型这个方向是有前途的,但是 AutoML 的终极目的是为了取代 AI 工程师吗?
现如今,AI 专家必须通过本能和试错来不断调试神经网络的内部架构。加州大学伯克利分校研究员 Roberto Calandra 表示 :“工程师的很大一部分工作本质上非常无聊,需要尝试各种配置来看哪些(神经网络)效果更好。”Calandra 认为,因为要解决的问题越来越难,神经网络也越来越深,未来设计一个深度学习模型的将会是一个艰巨的挑战。
而从理论上来讲,AutoML 未来设计一个深度神经网络所耗费的时间,与人类专家相比几乎可以忽略不计,而且这个由机器设计的模型的效果也会更好,显然 AutoML 将大有可为。
但是,这并不意味着 AutoML 会将人类从 AI 系统的开发过程中剔除出去。
实际上,AutoML 的主要目的会降低机器学习的门槛,促进 AI 的民主化。要知道,即便实力雄厚如谷歌,也不敢说自己已经拥有足够的 AI 人才,因此降低门槛,提高效率,对 AI 行业的发展至关重要。
谷歌首席执行官 Sundar Pichai 在上周的发布会上表示:“如今,这些(AI 系统)都是机器学习专家亲手搭建的,而全世界只有几千名科学家能够做到这一点。我们希望让成千上万的开发者也能够做到这一点。”
因此,虽然 AutoML 可能没有继承谷歌顶尖工程师的理论基础和数学才华,但是它却可以帮助 AI 工程师节省时间,或者启发他们,为他们提供灵感。
古筱凡也认为,AutoML 是真正的机器学习,它把经验性的工作自动化,现在的机器学习只是半成品。AutoML 能极大地降低未来机器学习的门槛,将是普通人使用机器学习的利器。
据悉,AutoML 团队将会对机器所设计的架构进行深入的分析和测试,帮助 AI 工程师重新审视自身对这些架构的理解。如果谷歌成功,这意味着 AutoML 将有可能引发新的神经网络类型的诞生,也能让一些非专业研究人员根据自己的需要创造神经网络,造福全人类。
AutoML 可能不会取代 AI 工程师,但是机器都这么努力了,你还有什么借口偷懒!
就在这篇文章的留言区,好几条评论称:“作为AI工程师的我,感到了深深的压力。机器学习能力照着么发展下去,没准饭碗儿就真丢了......”
参考资料:
https://research.googleblog.com/2017/05/using-machine-learning-to-explore.html
https://thenextweb.com/artificial-intelligence/2017/10/16/googles-ai-can-create-better-machine-learning-code-than-the-researchers-who-made-it/#
https://zhuanlan.zhihu.com/p/27792859
https://www.wired.com/story/googles-learning-software-learns-to-write-learning-software/
SDCC 2017“人工智能技术实战线上峰会”将在CSDN学院以直播互动的方式举行。
作为SDCC系列技术峰会的一部分,来自阿里巴巴、微软、商汤科技、第四范式、微博、出门问问、菱歌科技的AI专家,将针对机器学习平台、系统架构、对话机器人、芯片、推荐系统、Keras、分布式系统、NLP等热点话题进行分享。先行者们正在关注哪些关键技术?如何从理论跨越到企业创新实践?你将从本次峰会找到答案。每个演讲时段均设有答疑交流环节,与会者和讲师可零距离互动。

