Hadoop3+zookeeper3 HA高可用集群搭建
文章目录
- 安装软件包
- java环境配置
- Linux系统环境设置
- Hadoop完全分布式(full)
- Hadoop HDFS高可用集群搭建(NameNode HA With QJM)
- Hadoop YARN高可用集群搭建(ResourceManager HA)
安装软件包
| jdk | jdk-8u192-linux-x64.tar.gz |
|---|---|
| hadoop | hadoop-3.1.2.tar.gz |
| zookeeper | zookeeper-3.4.13.tar.gz |
java环境配置
# vi + /etc/profile
在末尾添加以下内容:
# JAVA_HOME
export JAVA_HOME=/opt/tools/java/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
使文件生效
# source /etc/profile
Linux系统环境设置
- 关闭并禁用防火墙(开机不自启)
# service ntpd stop
# chkconfig iptables off
- 禁用selinux
# vi /etc/sysconfig/selinux
修改 selinux=disabled
- 设置文件打开数量和用户最大进程数(每台都要设置)
# vi /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
* soft nproc 32000
* hard nproc 32000
- 集群系统的时间同步
1.检查是否有时间同步的插件:# rpm -qa | grep ntp
2.没有就安装(每台都要安装):# yum -y install ntp ntpdate
3.选择一台服务器作为集群的时间服务器
比如:node1:时间服务器,node2、node3、node4时间同步node1
4.查看Linux中的ntpd时间服务(这里只要开启第一台机器的ntpd服务,其他的不用开)
# service ntpd status
# service ntpd start
5.开机启动设置(在第一台设置,其他不要设置)
# chkconfig ntpd on
6.修改时间服务器的配置文件
# vi /etc/ntp.conf
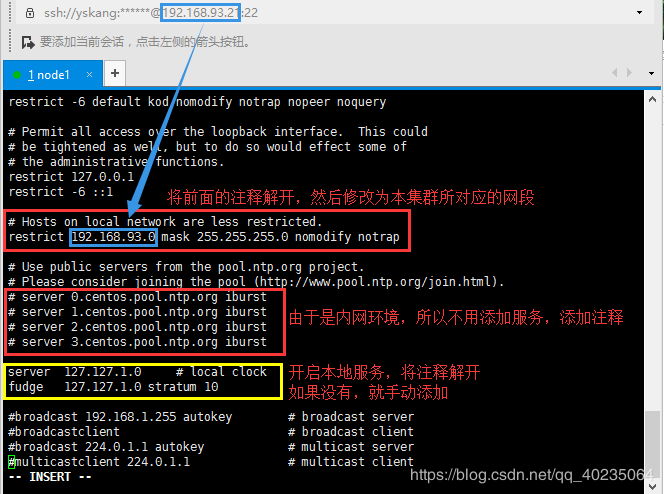
【第一处】修改为本集群的网段,注意将前面的#去掉,生效
# Hosts on local network are less restricted.
restrict 192.168.93.0 mask 255.255.255.0 nomodify notrap
【第二处】由于是内网环境不用添加服务,前面加上注释
#server 0.centos.pool.ntp.org
#server 1.centos.pool.ntp.org
#server 2.centos.pool.ntp.org
【第三处】开启本地服务(没有就手动添加),注意将前面的#去掉,生效
# local clock
server 127.127.1.0
fudge 127.127.1.0 stratum 10
保存文件,重启ntpd服务
#service ntpd restart
配置文件修改如下图所示:
7.更新本地时间 #ntpdate -u 202.120.2.101
注:可用于同步时间的网站
us.pool.ntp.org
cn.pool.ntp.org
ntp.sjtu.edu.cn 202.120.2.101 (上海交通大学网络中心NTP服务器地址)
s1a.time.edu.cn 北京邮电大学
s1b.time.edu.cn 清华大学
8.查看本地硬件时钟时间,并进行更新
# hwclock --localtime
# hwclock --localtime -w 或者 # hwclock --systohc //系统时间同步给硬件时间
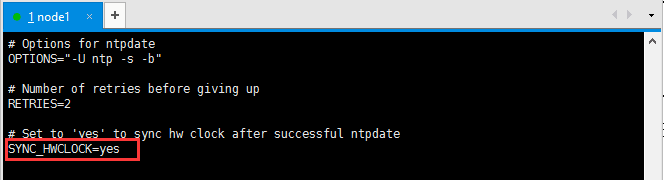
9.设置服务器启动后自动将硬件时钟时间同步给系统时间
# vi /etc/sysconfig/ntpd
添加: SYNC_HWCLOCK=yes
如图:
10.设置让系统时间自动同步给本地硬件时钟时间
# vi /etc/sysconfig/ntpdate
SYNC_HWCLOCK=yes
如图:
11.其他的服务器与这台时间服务器进行时间同步(剩余3台所有机器)
# crontab -e
## 每10分钟同步一次时间
0-59/10 * * * * /sbin/service ntpd stop
0-59/10 * * * * /usr/sbin/ntpdate -u node1
0-59/10 * * * * /sbin/service ntpd start

- ssh免密登陆配置
在4台机器上都执行
$ ssh-keygen -t rsa
然后三次回车,运行结束会在~/.ssh下生成两个新文件:
id_rsa.pub和id_rsa就是公钥和私钥
然后也是在4台机器上都执行:
$ ssh-copy-id node1;ssh-copy-id node2;ssh-copy-id node3;ssh-copy-id node4
测试是否可以免密登录
[yskang@node1 ~]$ ssh node2
[yskang@node2 ~]$
Hadoop完全分布式(full)
- 集群规划
| hostname | 配置 |
|---|---|
| node1 | namenode |
| node2 | secondarynamenode、datanode |
| node3 | datanode |
| node4 | datanode |
- 在node1节点上,配置hadoop
将hadoop解压到/opt/modules/full-hadoop目录下
$ tar -zxvf hadoop-3.1.2.tar.gz -C /opt/modules/full-hadoop
删掉doc文件夹
$ cd /opt/modules/full-hadoop/hadoop-3.1.2/share
$ rm -rf doc/
进入到$HADOOP_HOME/etc/hadoop/目录下,修改以下文件
- hadoop-env.sh
export JAVA_HOME=/opt/tools/java/jdk1.8
export HDFS_NAMENODE_USER=yskang
export HDFS_DATANODE_USER=yskang
export HDFS_SECONDARYNAMENODE_USER=yskang
##说明:yskang是指你当前集群的用户,如果是root用户,就写root,如果是普通用户,就写对应的普通用户名即可
- mapred-env.sh
export JAVA_HOME=/opt/tools/java/jdk1.8
- yarn-env.sh
export JAVA_HOME=/opt/tools/java/jdk1.8
- core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://node1:9820value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/datas/hadoop/full-hadoopvalue>
property>
configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node2:9868value>
property>
configuration>
- workers
node2
node3
node4
- 再把修改配置后的hadoop分发到其他节点的相同目录下
$ scp -r /opt/modules/full-hadoop/hadoop-3.1.2 node2:`pwd`
$ scp -r /opt/modules/full-hadoop/hadoop-3.1.2 node3:`pwd`
$ scp -r /opt/modules/full-hadoop/hadoop-3.1.2 node4:`pwd`
- 格式化(namenode所在的节点)
$ bin/hdfs namenode -format
- 启动
$ sbin/hadoop-daemon.sh start namenode
$ sbin/start-dfs.sh
Hadoop HDFS高可用集群搭建(NameNode HA With QJM)
- 集群规划
| hostname | namenode-1 | namenode-2 | datanode | zookeeper | zkfc | journalnode |
|---|---|---|---|---|---|---|
| node1 | √ | √ | √ | √ | ||
| node2 | √ | √ | √ | √ | √ | |
| node3 | √ | √ | √ | |||
| node4 | √ | √ |
- 安装Zookeeper
- 进入主机node1,解压zookeeper到 /opt/modules 目录下
1.解压
$ tar -zxvf /opt/softwares/zookeeper-3.4.13.tar.gz -C /opt/modules
2.修改zookeeper配置文件
$ cd /opt/modules/zookeeper-3.4.13/conf/
$ cp zoo_sample.cfg zoo.cfg
$ vi + zoo.cfg
修改:
dataDir=/opt/datas/zookeeper/zkData
并在末尾加入:
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
server.4=node4:2888:3888
3.在dataDir=/opt/datas/zookeeper/zkData目录下,新建myid文件(文件名必须是这个),输入1(这里的1与server.1是一一对应的)
$ cd /opt/datas/zookeeper/zkData/
$ vi myid
1
- 将zookeeper分发到node2、node3、node4,分别修改其myid文件值为2、3、4。
$ scp -r /opt/modules/zookeeper-3.4.13 node2:`pwd`
$ scp -r /opt/datas/zookeeper/zkData node2:`pwd`
$ scp -r /opt/modules/zookeeper-3.4.13 node3:`pwd`
$ scp -r /opt/datas/zookeeper/zkData node3:`pwd`
$ scp -r /opt/modules/zookeeper-3.4.13 node4:`pwd`
$ scp -r /opt/datas/zookeeper/zkData node4:`pwd`
- 启动4台zookeeper服务
$ cd /opt/modules/zookeeper-3.4.13
$ bin/zkServer.sh start //启动zookeeper
$ bin/zkServer.sh status //查看zookeeper的状态
$ bin/zkCli.sh //zookeeper客户端连接
- 开启zookeeper集群,可以看到一台主机是leader,其他3台主机是follower,则说明zookeeper集群搭建成功
- 在node1节点上,配置hadoop
将hadoop解压到/opt/modules/ha-hadoop目录下
$ tar -zxvf hadoop-3.1.2.tar.gz -C /opt/modules/ha-hadoop
删掉doc文件夹
$ cd /opt/modules/ha-hadoop/hadoop-3.1.2/share
$ rm -rf doc/
进入到$HADOOP_HOME/etc/hadoop/目录下,修改以下文件
- hadoop-env.sh
export JAVA_HOME=/opt/tools/java/jdk1.8
export HDFS_NAMENODE_USER=yskang
export HDFS_DATANODE_USER=yskang
export HDFS_JOURNALNODE_USER=yskang
export HDFS_ZKFC_USER=yskang
- mapred-env.sh
export JAVA_HOME=/opt/tools/java/jdk1.8
- yarn-env.sh
export JAVA_HOME=/opt/tools/java/jdk1.8
- core-site.xml
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://myclustervalue>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/datas/hadoop/ha-hadoopvalue>
property>
<property>
<name>hadoop.http.staticuser.username>
<value>yskangvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>node1:2181,node2:2181,node3:2181,node4:2181value>
property>
configuration>
- hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
<property>
<name>dfs.nameservicesname>
<value>myclustervalue>
property>
<property>
<name>dfs.ha.namenodes.myclustername>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1name>
<value>node1:8020value>
property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2name>
<value>node2:8020value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1name>
<value>node1:9870value>
property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2name>
<value>node2:9870value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://node1:8485;node2:8485;node3:8485/myclustervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/opt/datas/hadoop/ha-hadoop/journaldatavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.myclustername>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/yskang/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
configuration>
- workers
node2
node3
node4
- 再把修改配置后的hadoop分发到其他节点的相同目录下
$ scp -r /opt/modules/ha-hadoop/hadoop-3.1.2 node2:`pwd`
$ scp -r /opt/modules/ha-hadoop/hadoop-3.1.2 node3:`pwd`
$ scp -r /opt/modules/ha-hadoop/hadoop-3.1.2 node4:`pwd`
- 启动集群(严格按照以下步骤依次执行)
1.启动zookeeper 4台(出现一个leader,三个follower,启动成功)
$ bin/zkServer.sh start
$ bin/zkServer.sh status
2.启动journalnode(分别在node1、node2、node3上执行)
$ cd /opt/modules/ha-hadoop/hadoop-3.1.2/
$ bin/hdfs --daemon start journalnode
或者以下命令也是开启journalnode
$ sbin/hadoop-deamon.sh start journalnode
$ jps
1360 JournalNode
1399 Jps
1257 QuorumPeerMain
出现JournalNode则表示journalnode启动成功。
3.格式化namenode(只要格式化一台,另一台同步,两台都格式化,你就做错了!!如:在node1节点上)
$ bin/hdfs namenode -format
如果在倒数4行左右的地方,出现这一句就表示成功
INFO common.Storage: Storage directory /opt/datas/hadoop/ha-hadoop/dfs/name has been successfully formatted.
启动namenode
$ bin/hdfs --daemon start namenode
$ jps
1540 NameNode
1606 Jps
1255 QuorumPeerMain
1358 JournalNode
$ cat /opt/datas/hadoop/ha-hadoop/dfs/name/current/VERSION
#Sun Apr 07 21:03:48 CST 2019
namespaceID=1601166314
clusterID=CID-d2490688-522d-4fbc-a9a1-df2b035bfa04
cTime=1554642228113
storageType=NAME_NODE
blockpoolID=BP-260299858-192.168.93.21-1554642228113
layoutVersion=-64
4.同步node1元数据到node2中(必须先启动node1节点上的namenode)
在node2主机上执行:
$ bin/hdfs namenode -bootstrapStandby
如果出现:INFO common.Storage: Storage directory /opt/datas/hadoop/ha-hadoop/dfs/name has been successfully formatted.说明同步成功
$ cat /opt/datas/hadoop/ha-hadoop/dfs/name/current/VERSION
#Sun Apr 07 21:13:21 CST 2019
namespaceID=1601166314
clusterID=CID-d2490688-522d-4fbc-a9a1-df2b035bfa04
cTime=1554642228113
storageType=NAME_NODE
blockpoolID=BP-260299858-192.168.93.21-1554642228113
layoutVersion=-64
node1和node2显示的信息一致,则namenode数据同步成功
5.格式化ZKFC(在node1上执行一次即可)
$ bin/hdfs zkfc -formatZK
若在倒数第4行显示:INFO ha.ActiveStandbyElector: Successfully created /hadoop-ha/mycluster in ZK.则表示ZKFC格式化成功
6.启动HDFS(在node1上执行)
$ sbin/start-dfs.sh
7.访问node1:9870,node2:9870
Hadoop YARN高可用集群搭建(ResourceManager HA)
- 集群规划
| hostname | namenode-1 | namenode-2 | datanode | zookeeper | zkfc | journalnode | resourcemanager | nodemanager |
|---|---|---|---|---|---|---|---|---|
| node1 | √ | √ | √ | √ | ||||
| node2 | √ | √ | √ | √ | √ | √ | ||
| node3 | √ | √ | √ | √ | √ | |||
| node4 | √ | √ | √ | √ |
- hadoop-env.sh
末尾添加 :
export YARN_RESOURCEMANAGER_USER=yskang
export YARN_NODEMANAGER_USER=yskang
- mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node1:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node1:19888value>
property>
configuration>
- yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yrcvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>node3value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>node4value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>node3:8088value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>node4:8088value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>node1:2181,node2:2181,node3:2181,node4:2181value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>106800value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
configuration>
- 将以上修改文件分发到其他节点相同目录
- 启动yarn
先启动zookepper:zkServer.sh start
再启动hdfs:start-dfs.sh
启动yarn:start-yarn.sh
- 观察web 8088端口
当node3的ResourceManager是Active状态的时候,访问node4的ResourceManager会自动跳转到node3的web页面
测试HA的可用性
./yarn rmadmin -getServiceState rm1 ##查看rm1的状态
./yarn rmadmin -getServiceState rm2 ##查看rm2的状态