典型 Web App 架构
![]()
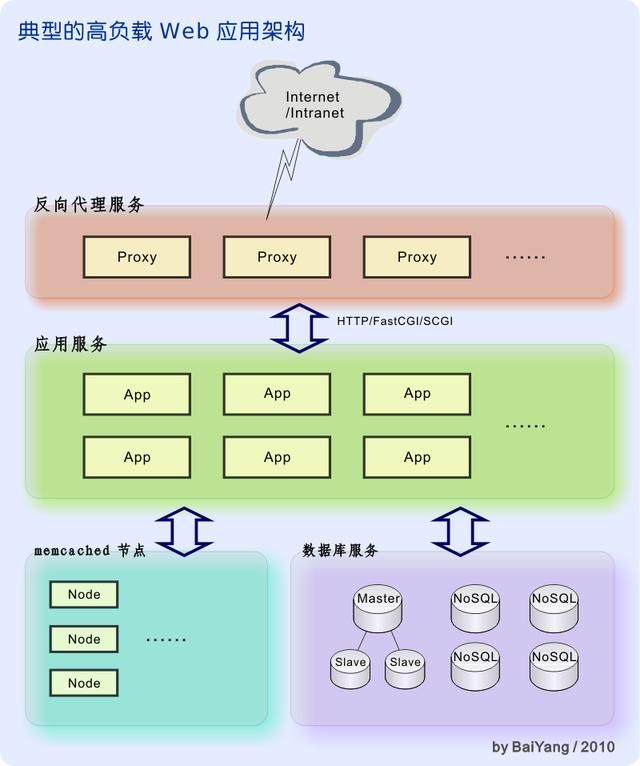
反向代理服务
![]()
| 以下是一个典型的高负载 web 应用示例: | 上图展示了一个典型的,三层架构的高性能 Web 应用。这种成熟的架构多年以来已被广泛部署于包括 Google、Yahoo、Facebook、Twitter、Wikipedia 在内的诸多大型 Web 应用中。 |
| 位于三层构架中最外层的反向代理服务器负责接受用户的接入请求,在实际应用中,代理服务器通常至少还要完成以下列表中的一部分任务: |
连接管理:分别维护客户端和应用服务器的连接池,管理并关闭已超时的长连接。
攻击检测和安全隔离:由于反向代理服务无需完成任何动态页面生成任务,所有与业务逻辑相关的请求都转发至后端应用服务器处理。因此反向代理服务几乎不会被应用程序设计或后端数据漏洞所影响。反向代理的安全性和可靠性通常仅取决于产品本身。在应用服务的前端部署反向代理服务器可以有效地在后端应用和远程用户间建立起一套可靠的安全隔离和攻击检测机制。
如果需要的话,还可以通过在外网、反向代理、后端应用和数据库等边界位置添加额外的硬件防火墙等网络隔离设备来实现更高的安全性保证。
负载均衡:通常使用轮转(Round Robin)或最少连接数优先等策略完成基于客户请求的负载均衡;也可以使用 SSI 等技术将一个客户请求拆分成若干并行计算部分分别提交到多个应用服务器。
分布式的 cache 加速:可以将反向代理分组部署在距离热点地区地理位置较近的网络边界上。通过在位于客户较近的位置提供缓冲服务来加速网络应用。这实际上就构成了 CDN 网络。
静态文件伺服:当收到静态文件请求时,直接返回该文件而无需将该请求提交至后端应用服务器。
动态响应缓存:对一段时间内不会发生改变的动态生成响应进行缓存,避免后端应用服务器频繁执行重复查询和计算。
数据压缩传输:为返回的数据启用 GZIP/ZLIB 压缩算法以节约带宽。
数据加密保护(SSL Offloading):为与客户端的通信启用 SSL/TLS 加密保护。
容错:跟踪后端应用服务器的健康状况,避免将请求调度到发生故障的服务器。
用户鉴权:完成用户登陆和会话建立等工作。
URL别名:对外建立统一的url别名信息,屏蔽真实位置。
应用混搭:通过SSI和URL映射技术将不同的web应用混搭在一起。
协议转换:为使用 SCGI 和 FastCGI 等协议的后端应用提供协议转换服务。
目前比较有名的反向代理服务包括:Apache httpd+mod_proxy / IIS+ARR / Squid / Apache Traffic Server / Nginx / Cherokee / Lighttpd / HAProxy 以及 Varnish 等等。 |
应用服务
![]()
应用服务层位于数据库等后端通用服务层与反向代理层之间,向上接收由反向代理服务转发而来的客户端访问请求,向下访问由数据库层提供的结构化存储与数据查询服务。
应用层实现了 Web 应用的所有业务逻辑,通常要完成大量的计算和数据动态生成任务。应用层内的各个节点不一定是完全对等的,还可能以 SOA、μSOA 等架构拆分为不同服务集群。
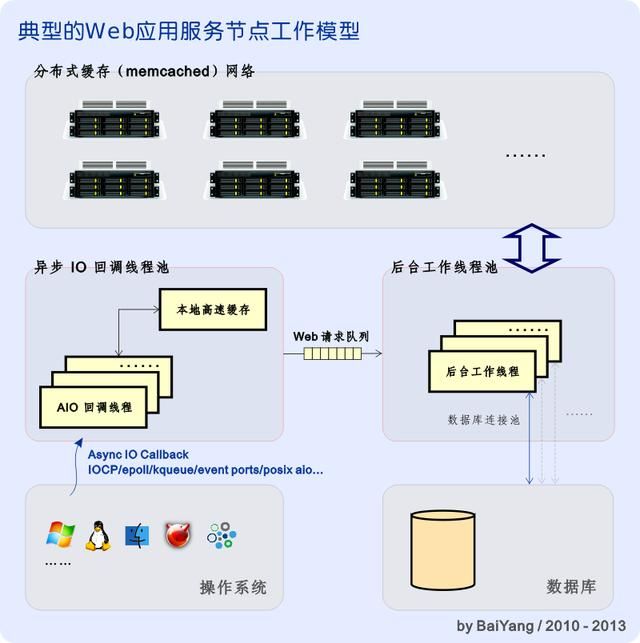
上图给出了一个典型的高并发、高性能应用层节点工作模型。每个 Web 应用节点(在图 5中由标有"App"字样的方框表示)通常都会工作在自己的服务器(物理服务器或VPS)之上,多个应用节点可以有效地并行工作,以方便地实现横向扩展。
在上图所示的例子中,Web 应用节点由 IO 回调线程池、Web 请求队列以及后台工作线程池等三个重要部分组成,其伺服流程如下:
当一个 Web 请求到达后,底层操作系统通过 IOCP、epoll、kqueue、event ports、real time signal (posix aio)、/dev/poll、pollset 等各类与具体平台紧密相关的 IO 完成(或 IO 就绪)回调机制通知 AIO(Asynchronous IO)回调线程,对这个已到达的 Web 请求进行处理。
在 AIO 回调池中的工作线程接收到一个已到达的 Web 请求后,首先尝试对该请求进行预处理。在预处理过程中,将会使用位于本地的高速缓存来避免成本较高的数据库查询。如果本地缓存命中,则直接将缓存中的结果(仍然以异步 IO 的方式)返回客户端,并结束本次请求。
如果指定的 Web 请求要求查询的数据无法被本地缓存命中,或者这个 Web 请求需要数据库写入操作,则该请求将被 AIO 回调线程追加到指定的队列中,等待后台工作线程池中的某个空闲线程对其进行进一步处理。
后台工作线程池中的每个线程都分别维护着两条长连接:一条与底层到数据库服务相连,另一条则连接到分布式缓存(memcached)网络。通过让每个工作线程维护属于自己的长连接,后台工作线程池实现了数据库和分布式缓存连接池机制。长连接(Keep-Alive)通过为不同的请求重复使用同一条网络连接大大提高了应用程序处理效率和网络利用率。
后台工作线程在 Web 请求队列上等待新的请求到达。在从队列中取出一个新的请求后,后台工作线程首先尝试使用分布式缓存服务命中该请求中的查询操作,如果网络缓存未命中或该请求需要数据库写入等进一步处理,则直接通过数据库操作来完成这个 Web 请求。
当一个 Web 请求被处理完成后,后台工作线程会将处理结果作为 Web 响应以异步 IO 的方式返回到指定客户端。
上述步骤粗略描述了一个典型 Web 应用节点的工作方式。值得注意的是,由于设计思想和具体功能的差异,不同的 Web 应用间,无论在工作模式或架构上都可能存在很大的差异。
需要说明的是,与 epoll/kqueue/event ports 等相位触发的通知机制不同,对于 Windows IOCP 和 POSIX AIO Realtime Signal 这类边缘触发的 AIO 完成事件通知机制,为了避免操作系统底层 IO 完成队列(或实时信号队列)过长或溢出导致的内存缓冲区被长时间锁定在非分页内存池,在上述系统内的 AIO 回调方式实际上是由两个独立的线程池和一个 AIO 完成事件队列组成的:一个线程池专门负责不间断地等待系统 AIO 完成队列中到达的事件,并将其提交到一个内部的 AIO 完成队列中(该队列工作在用户模式,具有用户可控的弹性尺寸,并且不会锁定内存);与此同时另一个线程池等待在这个内部 AIO 完成队列上,并且处理不断到达该队列的 AIO 完成事件。这样的设计降低了操作系统的工作负担,避免了在极端情况下可能出现的消息丢失、内存泄露以及内存耗尽等问题,同时也可以帮助操作系统更好地使用和管理非分页内存池。
作为典型案例:包括搜索引擎、Gmail 邮件服务在内的大部分 Google Web 应用均是使用 C/C++ 实现的。得益于 C/C++ 语言的高效和强大,Google 在为全球 Internet 用户提供最佳 Web 应用体验的同时,也实现了在其遍及全球的上百万台分布式服务器上完成一次 Web 搜索,总能耗仅需 0.0003 kW·h 的优异表现。关于 Google Web 应用架构以及硬件规模等进一步讨论,你可以加这个群获取:交流学习群:744642380里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化这些成为架构师必备的知识体系。还能领取免费的学习资源,目前受益良多
数据库和memcached服务
![]()
数据库服务为上层 Web 应用提供关系式或结构化的数据存储与查询支持。取决于具体用例,Web 应用可以使用数据库连接器之类的插件机制来提供对不同数据库服务的访问支持。在这种架构下,用户可以灵活地选择或变更最适合企业现阶段情况的不同数据库产品。例如:用户可以在原型阶段使用 SQLite 之类的嵌入式引擎完成快速部署和功能验证;而在应用的初期阶段切换到廉价的 MySql 数据库解决方案;等到业务需求不断上升,数据库负载不断加重时再向 Clustrix、MongoDB、Cassandra、MySql Cluster、ORACLE 等更昂贵和复杂的解决方案进行迁移。
Memcached 服务作为一个完全基于内存和
当然,我们也应该注意到:以 memcached 为代表的分布式缓存系统,其本质上是一种以牺牲一致性为代价来提升平均访问效率的妥协方案——缓存服务为数据库中的部分记录增加了分布式副本。对于同一数据的多个分布式副本来说,除非使用 Paxos、Raft 等一致性算法,不然无法实现强一致性保证。
矛盾的是,memory cache 本身就是用来提升效率的,这使得为了它使用上述开销高昂的分布式强一致性算法变得非常不切实际:目前的分布式强一致性算法均要求每次访问请求(无论读写)都需要同时访问包括后台数据库主从节点在内的多数派副本——显然,这还不如干脆不使用缓存来的有效率。
另外,即使是 Paxos、Raft 之类的分布式一致性算法也只能在单个记录的级别上保证强一致。意即:即使应用了此类算法,也无法凭此提供事务级的强一致性保证。
除此之外,分布式缓存也增加了程序设计的复杂度(需要在访问数据库的同时尝试命中或更新缓存),并且还增加了较差情形下的访问延迟(如:未命中时的 RTT 等待延迟,以及节点下线、网络通信故障时的延迟等)。
与此同时,可以看到:从二十年前开始,各主流数据库产品其实均早已实现了成熟、高命中率的多层(磁盘块、数据页、结果集等)缓存机制。既然分布式缓存有如此多的缺陷,而数据库产品又自带了优秀的缓存机制,它为何又能够成为现代高负载 Web App 中的重要基石呢?
其根本原因在于:对于十年前的技术环境来说,当时十分缺乏横向扩展能力的 RDBMS(SQL)系统已成为了严重制约 Web App 等网络应用扩大规模的瓶颈。为此,以 Google BigTable、Facebook Cassandra、MongoDB 为代表的 NoSQL 数据库产品,以及以 memcached、redis 为代表的分布式缓存产品纷纷粉墨登场,并各自扮演了重要作用。
与 MySQL、ORACLE、DB2、MS SQL Server、PostgreSQL 等当时的 "传统" SQL数据库产品相比,无论 NoSQL 数据库还是分布式缓存产品,其本质上都是以牺牲前者的强一致性为代价,来换取更优的横向扩展能力。
应当看到,这种取舍是在当时技术条件下做出的无奈、痛苦的抉择,系统因此而变得复杂——在需要事务和强一致性保障,并且数据量较少的地方,使用无缓存层的传统 RDBMS;在一致性方面有一定妥协余地,并且读多写少的地方尽量使用分布式缓存来加速;在对一致性要求更低的大数据上使用 NoSQL;如果数据量较大,同时对一致性要求也较高,就只能尝试通过对 RDMBS 分库分表等方法来尽量解决,为此还要开发各种中间件来实现数据访问的请求分发和结果集聚合等复杂操作……各种情形不一而足,而它们的相互组合和交织则再次加剧了复杂性。
回顾起来,这是一个旧秩序被打破,新秩序又尚未建立起来的混乱时代——老旧 RMDBS 缺乏横向扩展能力,无法满足新时代的大数据处理需求,又没有一种能够替代老系统地位,可同时满足大部分用户需求的普适级结构化数据管理方案。
这是一个青黄不接的时代,而 BigTable、Cassandra、memcached 等产品则分别是 Google、Facebook 以及 LiveJournal 等厂商在那个时代进行 "自救" 的结果。这样以:"花费最小代价,满足自身业务需求即可" 为目标的产物自然不太容易具备很好的普适性。
然而今天(2015),我们终于就快要走出这个窘境。随着 Google F1、MySQL Cluster(NDB)、Clustrix、VoltDB、MemSQL、NuoDB 等众多 NewSQL 解决方案的逐步成熟以及技术的不断进步,横向扩展能力逐渐不再成为 RDBMS 的瓶颈。今天的架构设计师完全可以在确保系统拥有足够横向扩展能力的同时,实现分布式的事务级(XA)强一致性保证:
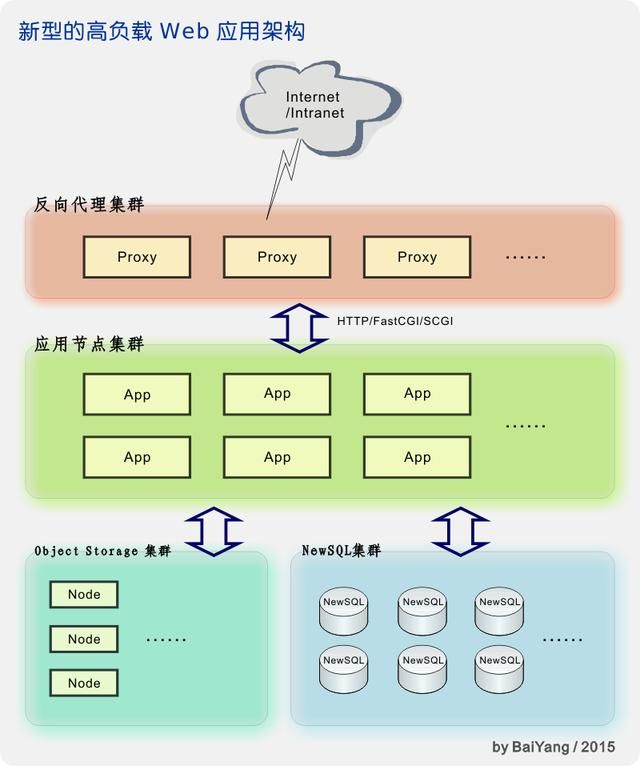
如上图所示,在 NewSQL 具备了良好的横向扩展能力后,架构中不再迫切需要分布式缓存和 NoSQL 产品来弥补这方面的短板,这使得设计和开发工作再次回归到了最初的简洁和清晰。而对象存储(Object Storage)服务则提供了对音频、视频、图片、文件包等海量非结构化BLOB数据的存储和访问支持。
这样简洁、清晰、朴素的架构使一切看起来仿佛回归到了多年以前,对象存储服务就像 FAT、NTFS、Ext3 等磁盘文件系统,NewSQL 服务则好像当年 MySQL、SQL Server 等 "单机版" 数据库。但一切却又已不同,业务逻辑、数据库和文件存储均已演进成为支持横向扩展的高可用集群,在性能、容量、可用性、可靠性、可伸缩性等方面有了巨大的飞跃:人类总是以螺旋上升的方式不断进步——在每一次看似回归的变迁中,实包含了本质的升华。
随着 GlusterFS、Ceph、Lustre 等可 mount 且支持 Native File API 的分布式文件系统越来越成熟和完善,也有望于大部分场合下逐渐替换现有的对象存储服务。至此 Web App 架构的演进才能算是完成了一次重生——这还算不上是涅槃,当我们能够在真正意义上实现出高效、高可用的多虚一(Single System Image)系统时,涅槃才真正降临。那时的我们编写分布式应用与如今编写一个单机版的多线程应用将不会有任何区别——进程天然就是分布式、高可用的!
三层架构的可伸缩性
![]()
小到集中部署于单台物理服务器或 VPS 内,大到 Google 遍及全球的上百万台物理服务器所组成的分布式应用。前文描述的三层 Web 应用架构体现出了难以置信的可伸缩性。
具体来说,在项目验证、应用部署和服务运营的初期阶段,可以将以上三层服务组件集中部署于同一台物理服务器或 VPS 内。与此同时,可通过取消 memcached 服务,以及使用资源开销小并且易于部署的嵌入式数据库产品来进一步降低部署难度和系统整体资源开销。
随着项目运营的扩大和负载的持续加重,当单服务器方案和简单的纵向扩展已无法满足项目运营负荷时,用户即可通过将各组件分布式地运行在多台服务器内来达到横向扩展的目的。例如:反向代理可通过 DNS CNAME 记录轮转或 3/4 层转发(LVS、HAProxy等)的方式实现分布式负载均衡。应用服务则可由反向代理使用基于轮转或最小负载优先等策略来实现分布式和负载均衡。此外,使用基于共享 IP 的服务器集群方案也能够实现负载均衡和容错机制。
与此类似,memcached 和数据库产品也都有自己的分布式运算、负载均衡以及容错方案。此外,数据库访问性能瓶颈可通过更换非关系式(NoSQL)的数据库产品,或使用主-从数据库加复制等方式来提升。而数据库查询性能则可通过部署 memcached 或类似服务来极大程度地改善。