XLNet:通用自回归预训练方法
XLNet:通用自回归预训练方法
- AR和AE
- XLNet的比较优势
- Transformer-XL
- Transformer的特点和缺陷
- 语言模型里的Transformer
- XL是什么
- 相对位置编码
- XLNet的目标函数:排列语言模型(Permutation Language Modeling)
- 双流自注意力(Two-Stream Self Attention)
- 实验
BERT(前文有 介绍)火了以后 XLNet算是首个真正意义上能和其叫板的工作了。在20个任务上都超过BERT,其中很多还是大幅的超越。
AR和AE
作者首先对今天NLP的主流预训练方法进行了分类:自回归语言模型(AR)和自编码(AE)。这样就把ULMFit,ELMo, GPT,GPT2这些依靠传统的语言模型进行预训练的方法分成了一类(AR)。大名鼎鼎的BERT在它的独创性的MLM(Masked LM)中,利用corrupted版本的输入(即用[MASK]来遮住一些token的输入)来恢复原来的tokens,这本质上是denoising autoencoder,所以BERT属于自编码流派。
这两种方法到底孰优孰劣?作者提到了BERT在利用上下文的信息上有很大的灵活性,它不像AR语言模型只能利用单向的信息(或者forward或者backward),所以在很多下游的语言任务中有很大的提升。
然而作者也指出了BERT的两个缺陷:
- [MASK]在fine tuning的时候不存在,这导致了预训练-微调不一致性(pretrain-finetune discrepancy)。(注:BERT的原始论文也提到过这个问题,并且相应的有采取处理手段,所以我个人觉得这未必是个大问题。)
- 被预测的tokens都在输入中用[MASK]替代了,这意味着BERT假设这些tokens(在其他unmasked tokens存在的情况下)是相互独立的。(这个有点拗口,其实意思就是说如果同时mask了多个tokens,那么除了被预测的那个词,其他的被mask的词在训练时也用不上。)
我个人的看法:AE方法最大的一个限制是不方便当做decoder来使用(从名字上看,它是个auto “encoder”而不是decoder),所以在文本生成类的任务上不好用。比如BERT,它在预训练的时候利用了所有的环境信息,但是在生成文本的时候不可能去“向后看”得到未来的信息,这也算是一种训练和推断的不一致。但是像AR这一类利用LM预训练出的模型就很容易拿来作为decoder使用。
XLNet的比较优势
XLNet作为一种广义上的自回归方法,融合了AR和AE,取长补短,融汇贯通,成功的保留了两个流派的优点,并且避免了它们的局限。
下面是作者总结的XLNet的优点:
- XLNet把一个序列所有可能的排列都拿来作为LM的输入,这使得每一个位置上都能够利用到所有其他的位置的信息,从而真正的捕获了上下文。
- XLNet作为AR语言模型,不再依赖于data corruption。从而避免了上面提到的BRRT的两个缺陷。
另外,XLNet在架构上利用了Transformer-XL。Transformer-XL的创新之处在于它的segment recurrence机制和相对位置编码方法,这带来了它在处理长文本上效果的提升。
Transformer-XL
Transformer-XL值得单独拿出来讲一讲,我觉得在XLNet的成功一定会带动未来更多的工作采用Transformer-XL。它作为Transformer的改进版有逐渐取而代之的可能。篇幅所限,这里仅从high level上解释一下直觉上的意义。以下用XL代替Transformer-XL。
Transformer的特点和缺陷
首先我们得重新审视一下Transformer。它利用self-attenetion机制来产生long-range dependency,从而避免了LSTM里的recurrent的机制带来的vanishing/exploding gradient的问题。为了同时保有序列性,它引入了位置编码。而这些都完美的避开了LSTM里的序列性的计算,使其更易于并行化。
然而魔鬼在细节,如果我们审视一下Transformer的计算复杂度:(下图来自Transformer的原始论文attention is all you need)
 这里的n可以理解为输入的长度,d是每个token对应的表征维度,那么Self-Attention对应的复杂度是 O ( n 2 d ) O(n^2 d) O(n2d) (因为每个token都要attend to每一个其他的token),看上去竟然远大于Recurrent(即LSTM)类的 O ( n d 2 ) O(nd^2) O(nd2) 。
这里的n可以理解为输入的长度,d是每个token对应的表征维度,那么Self-Attention对应的复杂度是 O ( n 2 d ) O(n^2 d) O(n2d) (因为每个token都要attend to每一个其他的token),看上去竟然远大于Recurrent(即LSTM)类的 O ( n d 2 ) O(nd^2) O(nd2) 。
看样子,Transformer的计算效率比Recurrent类型的神经网络还要低!
在实际应用中,情况不是这样。因为d的取值往往远大于n。句子的长度一般是64或者128,但是d往往可以很大比如512或者1024,这样的话 O ( n 2 d ) O(n^2d) O(n2d)远小于 O ( n d 2 ) O(nd^2) O(nd2),Transformer的复杂度的确小于Recurrent Networks。
Github上发布的BERT Base和Large应该是用512的序列长度做的预训练,这已经是非常巨大的参数了。即使是直接把发布的BERT模型拿来(或经过fine tuning后)使用,在对inference的速度有要求的工业界,相信绝大部分人会有针对性的选择小的多的max sequence length。
如果我们能够理解Transformer在复杂度上的特点,我们也很容易理解它的缺陷了。那就是context fragmentation。简单说,就是Transformer只能选择固定长度的连续tokens做计算(根据前面的分析,这个固定长度往往有限),不能考虑到句子或者其他任何语义边界,从而缺乏必要的语境信息,这必然带来优化问题。看下面的例子。
语言模型里的Transformer
 这是一个语言模型。在训练阶段,信息不能在不同的分段(segment)之间流动。
这是一个语言模型。在训练阶段,信息不能在不同的分段(segment)之间流动。
作者提到这种训练方式会导致两个问题:
首先,最大可能的dependency length被分段长度给限制住了,这导致了模型不能够充分利用self-attention机制的优势。
注意图1(a)里的 x 5 x_5 x5,它和前一个分段里的 x 1 x_1 x1到 x 4 x_4 x4没有任何连接。前面的任何内容,在这个分段都不会存在任何记忆。
第二,如前所述,这种做法没有照顾到句子或者其他形式的语义边界,带来了语境碎片化问题(context fragmentation)。
如果图1(a)中的 x 1 x_1 x1到 x 8 x_8 x8恰好是一个独立的语义单位,比如说是一个完整的句子,那么上面的分段就导致了语境的碎片化。
在evaluation阶段,该语言模型每次向右移动一个单位,这种方式效率非常低。因为每一次移动都要重新进行处理当前的segment,而前面提到过,每层的计算复杂度是 O ( n 2 d ) O(n^2d) O(n2d)。
XL是什么
XL就是extremly long的意思。它旨在克服上面提到的Transformer的困难,从而使之能够处理非常长的信息。一句话总结XL:它是带有recurrence机制的Transformer。
原始论文里的图:
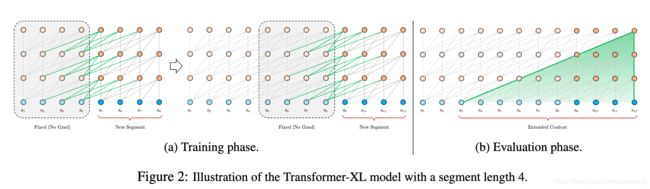 图(a)中的New Segment部分指的是当前正在进行处理的部分,阴影部分指的是在上一个时间步处理过的部分。显然这个处理过的部分也参与到了当前的计算。绿色的连接代表参与的方式:即隐藏层序列被固定在内存中,作为extended context传给当前部分。
图(a)中的New Segment部分指的是当前正在进行处理的部分,阴影部分指的是在上一个时间步处理过的部分。显然这个处理过的部分也参与到了当前的计算。绿色的连接代表参与的方式:即隐藏层序列被固定在内存中,作为extended context传给当前部分。
用数学公式表示更清楚一些:
假设有两个连续的长度都为L的分段 s τ = [ x τ , 1 , . . . , x τ , L ] s_{\tau}=[x_{\tau,1},...,x_{\tau,L}] sτ=[xτ,1,...,xτ,L]和 s τ + 1 = [ x τ + 1 , 1 , . . . , x τ + 1 , L ] s_{\tau+1}=[x_{\tau+1,1},...,x_{\tau+1,L}] sτ+1=[xτ+1,1,...,xτ+1,L],
假设 s τ s_{\tau} sτ的第n层的隐藏层序列为 h τ n ∈ R L × d h_{\tau}^n\in R^{L\times d} hτn∈RL×d,这里 d d d是hidden dimension。那么对应的, s τ + 1 s_{\tau+1} sτ+1的第n层输出如下:
 这里SG()代表stop-gradient,意味着前一个分段里的参数是不变的。 [ h u ∘ h v ] [h_u \circ h_v] [hu∘hv]代表两个隐藏序列的连接,具体方式是延展隐藏层的长度。所以extended context 即 h ~ τ + 1 n − 1 \tilde{h}_{\tau+1}^{n-1} h~τ+1n−1的维度是 2 L × d 2L\times d 2L×d。
这里SG()代表stop-gradient,意味着前一个分段里的参数是不变的。 [ h u ∘ h v ] [h_u \circ h_v] [hu∘hv]代表两个隐藏序列的连接,具体方式是延展隐藏层的长度。所以extended context 即 h ~ τ + 1 n − 1 \tilde{h}_{\tau+1}^{n-1} h~τ+1n−1的维度是 2 L × d 2L\times d 2L×d。
我们看到key k τ + 1 n k_{\tau+1}^n kτ+1n和value v τ + 1 n v_{\tau+1}^n vτ+1n都用到extended context h ~ τ + 1 n − 1 \tilde{h}_{\tau+1}^{n-1} h~τ+1n−1的值,也意味着它们用到了上一个分段的隐藏层 h τ n − 1 h_{\tau}^{n-1} hτn−1的值。这是标准的Transformer所不具有的特性。正因为XL有了这种recurrence的机制,它的有效语境可以远大于两个分段。如图所示,最大可能的dependency length应该是 O ( N × L ) O(N\times L) O(N×L),这里N是层数。
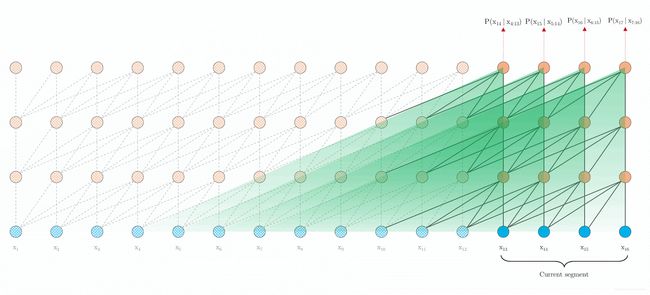
XL在evaluation阶段也有很大的优势。前面的segments产生的表征,因为放在内存中,全都可以拿来重用。图2(b)中的绿色部分代表了dependency。可以看出dependency length的跨度是 x 3 x_3 x3到 x 12 x_{12} x12,这包括了3个分段。其实只要GPU的内存允许,我们可以缓存更多的分段。作者在实验中就采取了这种做法,在evaluation阶段使用了更多的存储起来的分段,这成功的避免了语境碎片化并尽可能的完整保留了long-range dependency。这是一个非常合理的trade-off:内存的消耗带来的运算速度的提升。理论上讲,内存够大的话,应该把无穷长度的内容存储起来,比如把整本书都分段缓存下来,这样我们就不是做段落级别的阅读理解,而是更高级别的阅读理解。
作者的实验表明,在LM任务上,XL比vanilla Transformer在evaluation上可以快1800+倍。原因就在于缓存前面的segments可以避免在evaluation阶段的计算。下图显示XL在语言模型中evaluation的方式,依靠缓存的内容,它可以把整个segment同时处理掉,而不是Transformer那种逐个token移动并计算的方式。
相对位置编码
到这里为止XL的recurrence机制算是介绍完了。不过技术细节上还是没有完工。比如Transformer里的绝对位置编码在这里就不适用了。假设 U ∈ R L m a x × d U\in R^{L_{max}\times d} U∈RLmax×d里的第i行 U i U_i Ui代表分段中的第i个位置的编码,那么在XL中的不同的分段里,这样的位置编码会带来歧义,从而导致优化问题。
这里我们用名句"山下一群鹅,嘘声赶落河"举例。假设segment的长度 L = 5 L=5 L=5,并且不考虑标点符号,那么这两句正好被分在两个相邻的segment中。利用recurrence的机制,我们在处理"河"这个字的时候,不仅可以利用本分段里的信息(即"嘘声赶落"四个字),还能直接把前分段"山下一群鹅"的表征拿来使用。当我们把注意力放在本段第四个字"落"上的时候,如果利用绝对位置编码,我们用的是 U 4 U_4 U4来代表它的位置,因为"鹅"字是在第五个位置上,所以它对应 U 5 U_5 U5,这两个位置很近,从位置编码上可以反映出来。
然而前一个分段的"群"字在该位置编码体系中也对应 U 4 U_4 U4,这样它会被误认为靠近目标词"河"。这样的错误会带来优化的困难。
作者解决的办法是利用相对位置编码,解除这种歧义。这里不再赘述具体细节。大家有兴趣可以自行看论文。我想说的是,引入recurrence机制的思想是XL最大的创新之处,而使用相对位置编码只是为了合理的实现recurrence,从而采取的一种数学上的做法。为了避免绝对位置编码的歧义,相信未来人们会找到其他的做法。这里的相对位置编码,只是其中的一种技术。
Transformer-XL总算介绍完了,接下来还是回到XLNet。
XLNet的目标函数:排列语言模型(Permutation Language Modeling)
前面说了,XLNet把语言模型放在句子的不同排列之上,以达到利用所有位置上的信息的效果。数学上的表达很简单:

Z T Z_T ZT代表长度为T的序列的所有可能的排列。 z z z代表一个factorization order。
但是具体实现起来是有讲究的,作者并不是简单的对句子进行重新排列作为输入,而是仍然保持原来的句子作为输入(也保留原来的位置编码),但通过合适的attention mask来达到重新排序的效果。 这么做得原因是在finetuning的阶段,模型的输入仍然是自然排序的序列,如果简单的在预训练时采用乱序的输入,模型会在乱序的语言上进行优化,这不合理。
论文中的图示阐明了这个做法:
 这四个图代表了四种在预测 x 3 x_3 x3的时候,句子可能有的不同的排列方式。注意输入一直是用了原始句子即 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4,不同的地方仅在于attention改变了,从而相应的改变了factorization order。比如右上图,仅 x 2 x_2 x2和 x 4 x_4 x4的attention保留, x 1 x_1 x1被mask掉了,达到的效果是factorization order 2,4,3,1。图中灰色的mem部分来自于前面分段的缓存,这个在上面的XL部分介绍过。
这四个图代表了四种在预测 x 3 x_3 x3的时候,句子可能有的不同的排列方式。注意输入一直是用了原始句子即 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4,不同的地方仅在于attention改变了,从而相应的改变了factorization order。比如右上图,仅 x 2 x_2 x2和 x 4 x_4 x4的attention保留, x 1 x_1 x1被mask掉了,达到的效果是factorization order 2,4,3,1。图中灰色的mem部分来自于前面分段的缓存,这个在上面的XL部分介绍过。
双流自注意力(Two-Stream Self Attention)
然而,这些都还不够。这种预训练方法可能会带来歧义。在一个句子里,我们有可能针对不一样的目标词,产生出一模一样的context。还是用名句"山下一群鹅,嘘声赶落河",假设我们的分段长度为11,把整个句子(含标点)都包括进来了。这时针对"鹅"字,在众多的排列中,我们可以有一个自然的序列"山下一群"来预测它。同样针对"河"字,我们在众多排列中,也可以有一个排序过的序列"山下一群"来预测它。那么一模一样的序列(“山下一群”)竟然用来预测两个不同的字,这导致了"鹅"和"河"在此时共享一样的模型的预测结果。
具体用数学表示就是:
p θ ( X z t = x ∣ x z < t ) = e x p ( e ( x ) T h θ ( x z < t ) ) ∑ x ′ e x p ( e ( x ′ ) T h θ ( x z < t ) ) p_\theta(X_{z_t}=x | x_{z<t})=\frac{exp(e(x)^Th_\theta(x_{z<t}))}{\sum_{x'}exp(e(x')^Th_\theta(x_{z<t}))} pθ(Xzt=x∣xz<t)=∑x′exp(e(x′)Thθ(xz<t))exp(e(x)Thθ(xz<t))
x x x是被预测词, z t z_t zt是被预测词的位置。 h θ ( x z < t ) h_\theta(x_{z<t}) hθ(xz<t)是 x z < t x_{z<t} xz<t的经过Transformer层的隐藏层表示。注意它不依赖于被预测词的位置 z t z_t zt,所以上面的分布只依赖于 h h h,即只依赖于 x z < t x_{z<t} xz<t。在例子中, x x x是"鹅"或者"河",但是 h h h只依赖于 x z < t x_{z<t} xz<t即"山下一群"。
为了解决这个问题,一个简单的想法就是在 h h h中引入对位置 z t z_t zt的依赖。用一个新的函数 g θ ( x z < t , z t ) g_\theta(x_{z<t}, z_t) gθ(xz<t,zt)来取代 h h h。这样就很自然通过不同的被预测词的位置,把它们区分开了。(比如上例中"鹅"字位置是5,"河"字位置11。位置不同导致二者不再共享同一个分布。)
在模型中需要同时利用 g g g和 h h h:
1.为了预测token x z t x_{z_t} xzt, g θ ( x z < t , z t ) g_\theta(x_{z<t}, z_t) gθ(xz<t,zt)只能利用它的位置信息即 z t z_t zt,但是一定不能利用 x z t x_{z_t} xzt。否则预测无意义。(注:这种情况下网络只要学会拷贝就可以了) 这里的 g g g称为query representation。
2.在预测其他的tokens x z j x_{z_j} xzj ( j > t j>t j>t),和过去一样,我们需要需要编码 x z t x_{z_t} xzt的信息来提供语境信息。所以我们需要content representation h θ ( x z ≤ t ) h_\theta(x_{z\leq t}) hθ(xz≤t)
(注意: 作者引入query representation的初衷只是为了解决前面提到的预训练歧义问题,所以在fine-tuning阶段不需要它。)
下图是两种representation的更新方式:
 Q, K,V分指query, key和value。第二个公式(content stream)就是一般的self attention的公式。在fine-tuning阶段,可以完全忽略掉第一个公式,仅利用content stream就可以了。
Q, K,V分指query, key和value。第二个公式(content stream)就是一般的self attention的公式。在fine-tuning阶段,可以完全忽略掉第一个公式,仅利用content stream就可以了。
注意第一个公式(query stream),它可以抽象为 g z t = F ( x z < t , z t ) g_{z_t}=F(x_{z<t} ,z_t) gzt=F(xz<t,zt)。它避免使用 x z t x_{z_t} xzt的信息。
以上,就是双流自注意力模型。Again,作者提出它只是为了解决预训练(Permutation Language Modeling)中遇到的问题,正如在Transformer XL中提出的相对位置编码,只是为了解决不同分段中绝对位置的意义含糊问题。所谓自己挖坑自己填
我们在了解这些方法和技巧的时候要注意它们的由来,分清主次:比如在XL中,缓存前面的分段就是方法上的创新,而相对位置编码只是一个由方法创新带来的技术上的子创新。排列语言模型(Permutation Language Modeling)是XLNet的方法上的创新,而双流自注意力是由它引起的一个技术上的子创新。
实现上还有很多细节,比如文章提到的"Partial Prediction",“Relative Segment Encodings”,以及如何把XL的相对位置编码和segment recurrence机制整合进来等等,这里不再赘述。还是强烈推荐读精彩的原始论文。
实验
实验方面的结果非常优秀,在多个任务中明显超过BERT。放几个印象深刻的结果:
 RACE用的是咱们国内初高中学生的英语考试阅读理解题,其中包含较难的推理问题。文章的平均长度(300)远大于很多其他的数据集(比如SQuAD),所以RACE是一个很好的长文章理解的benchmark。XLNet在实验中效果惊人,精度超过了最好的Ensemble的结果7.6点。作者认为模型的基础架构Transfomer-XL功不可没。
RACE用的是咱们国内初高中学生的英语考试阅读理解题,其中包含较难的推理问题。文章的平均长度(300)远大于很多其他的数据集(比如SQuAD),所以RACE是一个很好的长文章理解的benchmark。XLNet在实验中效果惊人,精度超过了最好的Ensemble的结果7.6点。作者认为模型的基础架构Transfomer-XL功不可没。
再放一个GLUE上的综合表现:
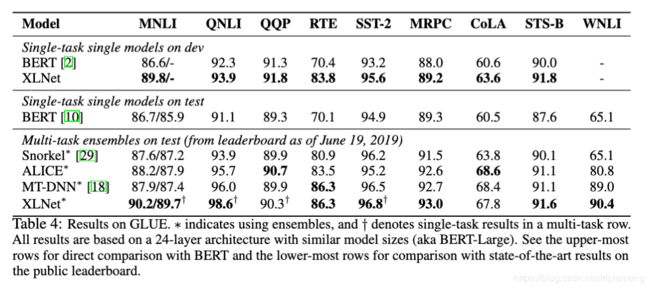
但这些实验还是有些不公平的成分,比如作者利用了更多的数据(BERT用到的数据+Giga5, ClueWeb 2012-B,Common Crawl)做预训练(这里模型XLNet-Large的大小和BERT-Large相似)。所以作者利用(BooksCorpus+Wikipedia即BERT的数据)预训练了一个XLNet-Base模型来和BERT-Base做比较。
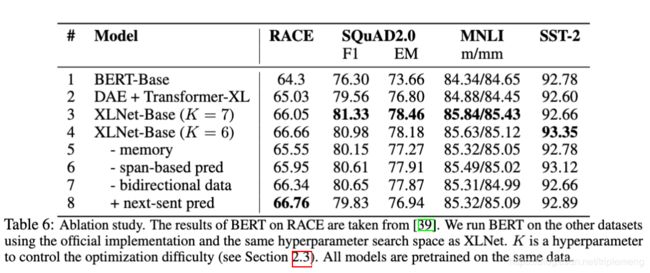 K=7的Base模型明显超过了BERT-Base,仅在SST-2落后一点点。(K是XLNet的一个超参,在论文的"Partial Prediction"里有介绍。大意是为了速度和内存考虑,只预测 1 / K 1/K 1/K的tokens)。
K=7的Base模型明显超过了BERT-Base,仅在SST-2落后一点点。(K是XLNet的一个超参,在论文的"Partial Prediction"里有介绍。大意是为了速度和内存考虑,只预测 1 / K 1/K 1/K的tokens)。
表中包含了ablation study, 作者考察了PLM(Permutation Language Modeling),XL和其他实现细节的效果。表中第二行的DAE+XL可以理解为对PLM效果的考察, 第五行-memory意味着不采用XL的recurrence机制。
首先应该肯定的是XLNet-Base(第三和第四行)的实验效果最佳,超过其他所有的实验,这说明各个组分的必要性。 第二行(DAE+Transformer-XL)采用了BERT的denoising auto-encoding objective,它和XLNet-Base的比较说明了PLM带来的明显的好处。而它和BERT-Base(第一行)的比较可以说明利用XL的效果:在RACE和SQuAD2.0这样的长文本理解任务中XL有优势。第五行(-memory)由于不再缓存segments,精度有所下降,特别是在RACE这样的长文本任务上。有趣的是,在第八行(+next-sent pred)采取了BERT中的下一句预测任务时,竟然意外的发现除RACE之外其他所有的任务表现下降。
实验中唯一的不足是没有给出任何text generation的文本例子,这应该是AR类模型的优势。期待未来会看到XLNet在文本生成类的任务上的精彩表现。
关注公众号《没啥深度》有关自然语言处理的深度学习应用,偶尔也有关强化学习。
