别找了 这就是适合入门的第一本算法书
《我的第一本算法书》根据 iOS 和 Android 平台上的应用程序“算法动画图解”编写而成,为配合图书出版,对内容进行了补充和修正,专门添加了基础理论方面的内容。
决定了数据的顺序和位置关系
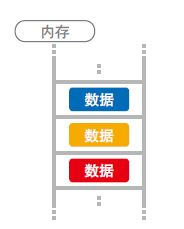
数据存储于计算机的内存中。内存如右图所示,形似排成 1 列的箱子,1 个箱子里存储 1 个数据。
数据存储于内存时,决定了数据顺序和位置关系的便是“数据结构”。
电话簿的数据结构
▶ 例① 从上往下顺序添加
举个简单的例子。假设我们有 1 个电话簿——虽说现在很多人都把电话号码存在手机里,但是这里我们考虑使用纸质电话簿的情况——每当我们得到了新的电话号码,就按从上往下的顺序把它们记在电话簿上。
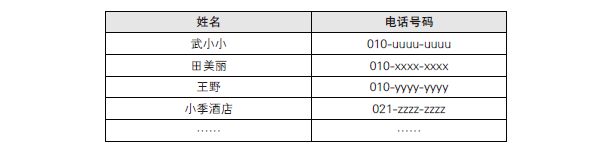
假设此时我们想给“张伟”打电话,但是因为数据都是按获取顺序排列的,所以我们并不知道张伟的号码具体在哪里,只能从头一个个往下找(虽说也可以“从后往前找”或者“随机查找”,但是效率并不会比“从上往下找”高)。如果电话簿上号码不多的话很快就能找到,但如果存了 500 个号码,找起来就不那么容易了。
▶ 例② 按姓名的拼音顺序排列
接下来,试试以联系人姓名的拼音顺序排列吧。因为数据都是以字典顺序排列的,所以它们是有“结构”的。
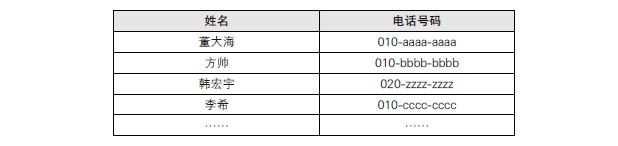
使用这种方式给联系人排序的话,想要找到目标人物就轻松多了。通过姓名的拼音首字母就能推测出该数据的大致位置。
那么,如何往这个按拼音顺序排列的电话簿里添加数据呢?假设我们认识了新朋友“柯津博”并拿到了他的电话号码,打算把号码记到电话簿中。由于数据按姓名的拼音顺序排列,所以柯津博必须写在韩宏宇和李希之间,但是上面的这张表里已经没有空位可供填写,所以需要把李希及其以下的数据往下移 1 行。
此时我们需要从下往上执行“将本行的内容写进下一行,然后清除本行内容”的操作。如果一共有 500 个数据,一次操作需要 10 秒,那么 1 个小时也完成不了这项工作。
▶ 两种方法的优缺点
总的来说,数据按获取顺序排列的话,虽然添加数据非常简单,只需要把数据加在最后就可以了,但是在查询时较为麻烦;以拼音顺序来排列的话,虽然在查询上较为简单,但是添加数据时又会比较麻烦。
虽说这两种方法各有各的优缺点,但具体选择哪种还是要取决于这个电话簿的用法。如果电话簿做好之后就不再添加新号码,那么选择后者更为合适;如果需要经常添加新号码,但不怎么需要再查询,就应该选择前者。
▶ 将获取顺序与拼音顺序结合起来怎么样
我们还可以考虑一种新的排列方法,将二者的优点结合起来。那就是分别使用不同的表存储不同的拼音首字母,比如表 L、表 M、表 N 等,然后将同一张表中的数据按获取顺序进行排列。
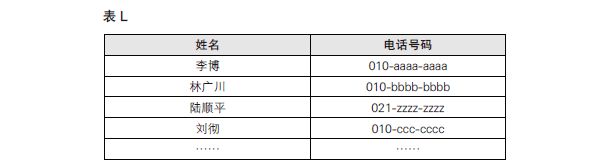
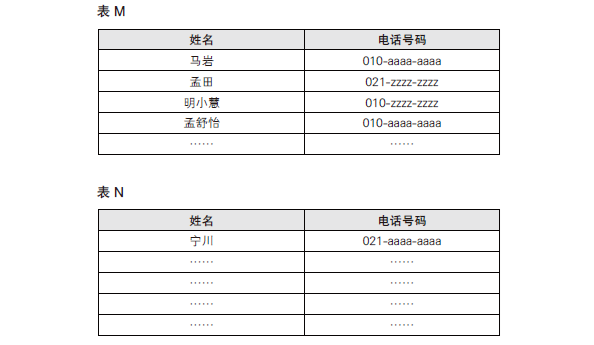
这样一来,在添加新数据时,直接将数据加入到相应表中的末尾就可以了,而查询数据时,也只需要到其对应的表中去查找即可。
因为各个表中存储的数据依旧是没有规律的,所以查询时仍需从表头开始找起,但比查询整个电话簿来说还是要轻松多了。
选择合适的数据结构以提高内存的利用率
数据结构方面的思路也和制作电话簿时的一样。将数据存储于内存时,根据使用目的选择合适的数据结构,可以提高内存的利用率。
本章将会讲解 7 种数据结构。如本节开头所述,数据在内存中是呈线性排列的,但是我们也可以使用指针等道具,构造出类似“树形”的复杂结构(树形结构将在 4-2 节详细说明)。
参考:4-2 广度优先搜索
1-2 链表
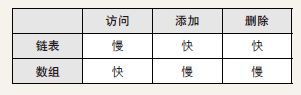
链表是数据结构之一,其中的数据呈线性排列。在链表中,数据的添加和删除都较为方便,就是访问比较耗费时间。
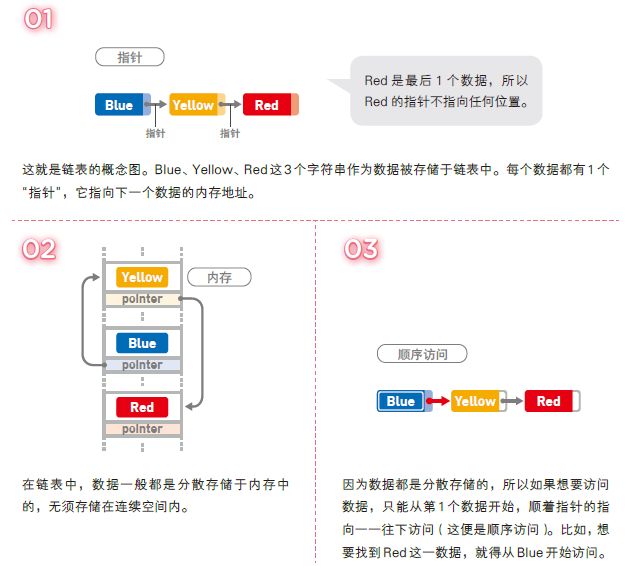
解说
对链表的操作所需的运行时间到底是多少呢?在这里,我们把链表中的数据量记成n。访问数据时,我们需要从链表头部开始查找(线性查找),如果目标数据在链表最后的话,需要的时间就是 O(n)。
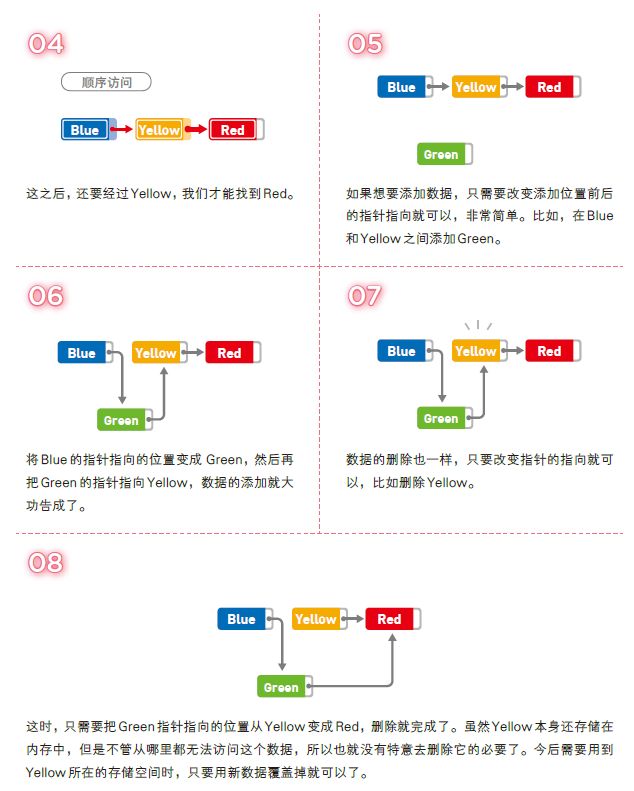
另外,添加数据只需要更改两个指针的指向,所以耗费的时间与 n 无关。如果已经到达了添加数据的位置,那么添加操作只需花费 O(1) 的时间。删除数据同样也只需O(1) 的时间。
参考:3-1 线性查找
补充说明
上文中讲述的链表是最基本的一种链表。除此之外,还存在几种扩展方便的链表。
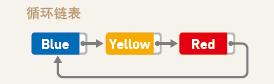
虽然上文中提到的链表在尾部没有指针,但我们也可以在链表尾部使用指针,并且让它指向链表头部的数据,将链表变成环形。这便是“循环链表”,也叫“环形链表”。循环链表没有头和尾的概念。想要保存数量固定的最新数据时通常会使用这种链表。
另外,上文链表里的每个数据都只有一个指针,但我们可以把指针设定为两个,并且让它们分别指向前后数据,这就是“双向链表”。使用这种链表,不仅可以从前往后,还可以从后往前遍历数据,十分方便。
但是,双向链表存在两个缺点:一是指针数的增加会导致存储空间需求增加;二是添加和删除数据时需要改变更多指针的指向。

1-3 数组
数组也是数据呈线性排列的一种数据结构。与前一节中的链表不同,在数组中,访问数据十分简单,而添加和删除数据比较耗工夫。这和 1-1 节中讲到的姓名按拼音顺序排列的电话簿类似。
参考:1-1 什么是数据结构
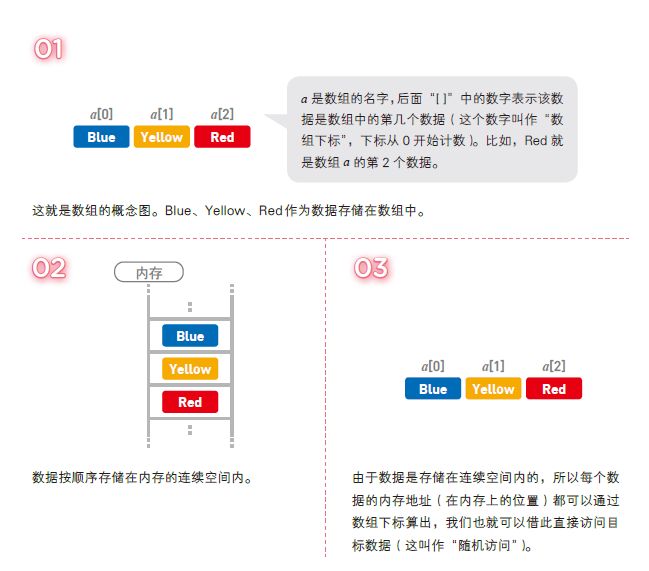

解说
这里讲解一下对数组操作所花费的运行时间。假设数组中有 n 个数据,由于访问数据时使用的是随机访问(通过下标可计算出内存地址),所以需要的运行时间仅为恒定的O(1)。
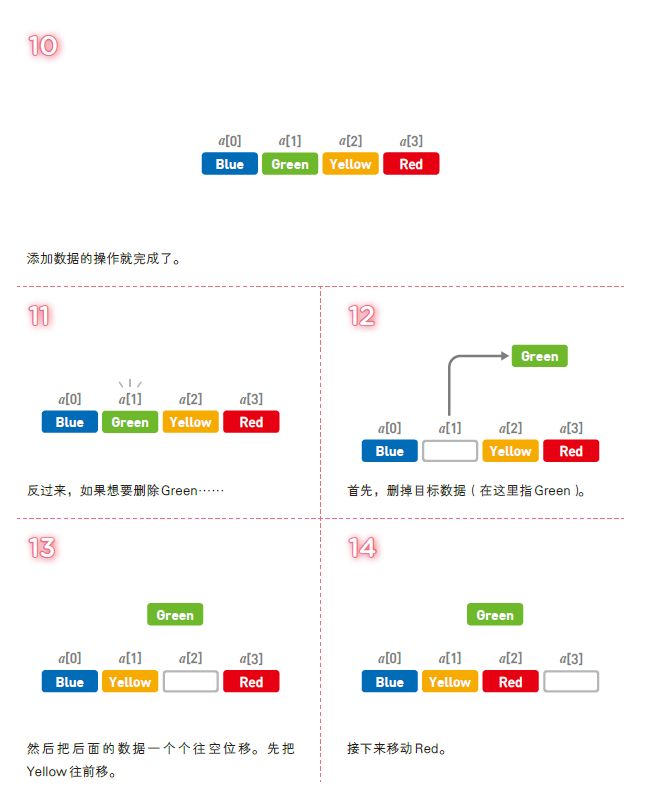
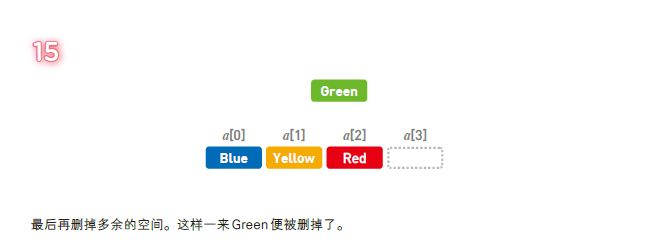
但另一方面,想要向数组中添加新数据时,必须把目标位置后面的数据一个个移开。所以,如果在数组头部添加数据,就需要 O(n) 的时间。删除操作同理。
补充说明
在链表和数组中,数据都是线性地排成一列。在链表中访问数据较为复杂,添加和删除数据较为简单;而在数组中访问数据比较简单,添加和删除数据却比较复杂。
我们可以根据哪种操作较为频繁来决定使用哪种数据结构。
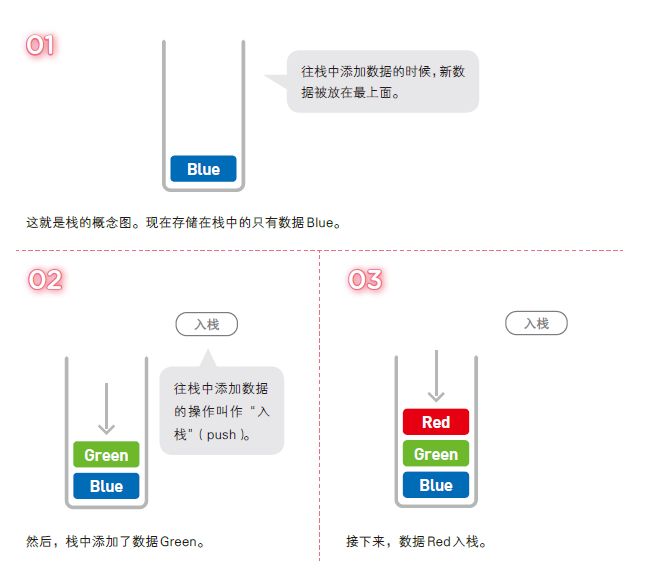
1-4栈
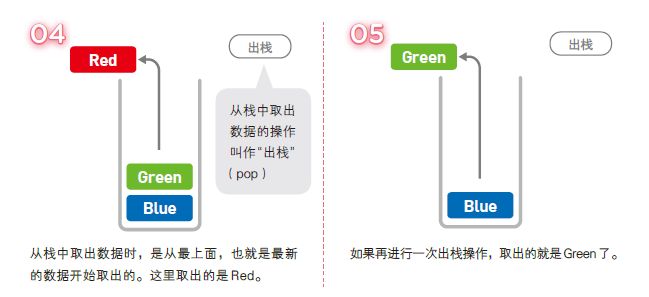
栈也是一种数据呈线性排列的数据结构,不过在这种结构中,我们只能访问最新添加的数据。栈就像是一摞书,拿到新书时我们会把它放在书堆的最上面,取书时也只能从最上面的新书开始取。
解说
像栈这种最后添加的数据最先被取出,即“后进先出”的结构,我们称为 Last In First Out,简称 LIFO。
与链表和数组一样,栈的数据也是线性排列,但在栈中,添加和删除数据的操作只能在一端进行,访问数据也只能访问到顶端的数据。想要访问中间的数据时,就必须通过出栈操作将目标数据移到栈顶才行。
应用示例
栈只能在一端操作这一点看起来似乎十分不便,但在只需要访问最新数据时,使用它就比较方便了。
比如,规定(AB(C(DE)F)(G((H)I J)K))这一串字符中括号的处理方式如下:首先从左边开始读取字符,读到左括号就将其入栈,读到右括号就将栈顶的左括号出栈。此时,出栈的左括号便与当前读取的右括号相匹配。通过这种处理方式,我们就能得知配对括号的具体位置。
另外,我们将要在 4-3 节中学习的深度优先搜索算法,通常会选择最新的数据作为候补顶点。在候补顶点的管理上就可以使用栈。
参考:4-3 深度优先搜索